


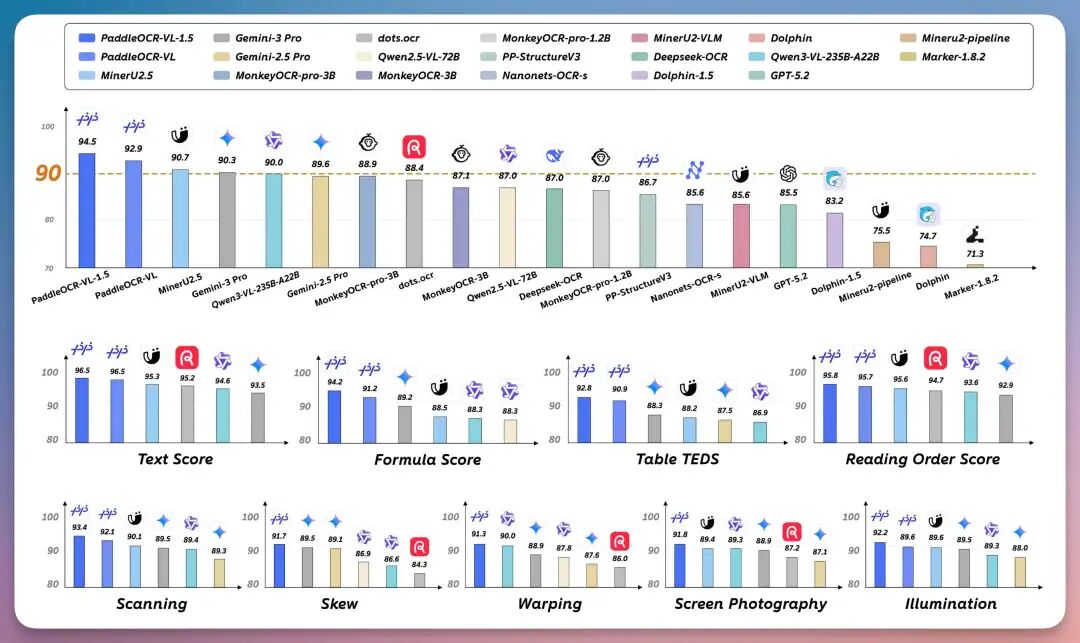
卷得离谱,双向+因果流视觉推理,详细的分析可以看文章,里面也提到了,“纯端到端上DeepSeek-OCR-2相较于DeepSeek-OCR有很大提升,但,PaddleOCR-VL依旧是唯一真神”确实,单论 “真实可用的 OCR 能力”,目前最强的,依然是百度的 PaddleOCR。而刚刚,百度发布了PaddleOCR-VL-1.5,以仅0.9B参数的轻量架构,在全球权威文档解析评测榜单 OmniDocBench V1.5中再次霸榜。
而且发布即开源(开源万岁),你可以直接在HuggingFace上下载部署,很多小伙伴其实都好奇:为什么到了 2026 年,OCR 这个看起来“很老”的技术,会突然变得这么重要?今天这篇,我就跟你聊聊:
-
关于OCR这件事为啥又重提? -
这次推出来的PaddleOCR-VL-1.5能力都有哪些? -
PaddleOCR-VL-1.5的实战表现如何? -
OCR都有哪些落地之处?
那么,我们开始吧!OCR 这件事,其实从来没“过时”很多人以为 OCR 已经是上个时代的技术了,现实刚好相反,越是大模型时代,越需要一个稳定把“图里的文字、结构、顺序”变成可用数据的入口。
OCR 的全称是Optical Character Recognition,光学字符识别。两句话讲清楚它的价值:把图片里的字变成可编辑文本,再把文档里的结构还原成可被系统直接使用的数据。很多人对 OCR 的印象,还停留在几个很早期的场景里。比如:扫描件转 Word、PDF 复制不了文字、发票识别等等。这些都没错。但只说对了一半。真正的 OCR,从来不是“把字读出来”这么简单。它解决的,本质上是一个更底层的问题:现实世界里的信息,如何被机器稳定、可靠、可结构化地理解。你随手拍一张合同,你在会议室拍一页 PPT,你用手机拍一张被折过的报销单。你翻拍一页老档案,纸张卷边、反光、歪斜。人类大脑一眼就能理解。但对机器来说,这些场景,全都是地狱难度。做过 AI 企业落地服务的朋友们想必都清楚… 难得不是AI应用,而是企业数据数字化、结构化比如“资料入库”和“流程自动化”,再聪明的智能体,如果吃进去的是一坨乱码,最后只会吐出一坨更漂亮的乱码。也正是因为这样,OCR 在大模型时代,反而重新站到了舞台中央。正好今天,百度把 PaddleOCR-VL-1.5 推出来了先说结论。PaddleOCR-VL-1.5 是一个0.9B 参数规模的文档解析模型。
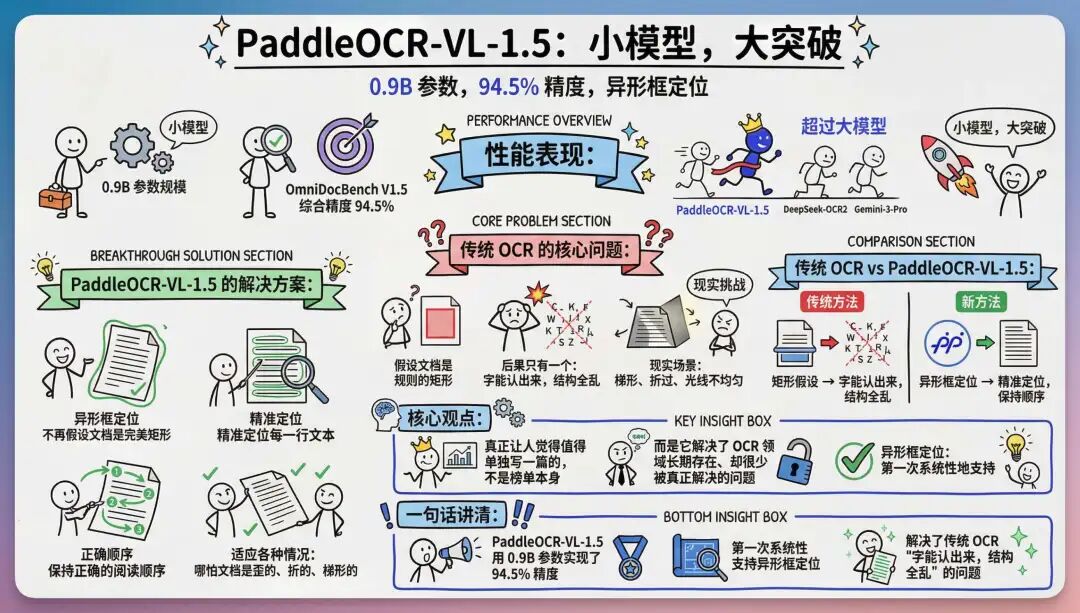
但在OmniDocBench V1.5这个全球权威评测里,它的综合精度达到了94.5%,超过了包括 DeepSeek-OCR2、Gemini-3-Pro 等一系列大模型 。但真正让我觉得“这次值得单独写一篇”的,并不是榜单本身。而是它解决了一个OCR 领域长期存在、却很少被真正解决的问题。真正的核心突破:异形框定位我们先抛开所有模型名字,说一个现实问题。你现在拍一张文档,大概率会遇到什么情况?要么文档是梯形、要么页面被折过、光线不均匀有反光等等..传统 OCR 的假设是:“文档是规则的矩形。”一旦这个前提不成立,后果只有一个:字能认出来。 结构全乱。而 PaddleOCR-VL-1.5 做的事情,是在模型层面,第一次系统性地支持了:异形框定位。什么意思?它不再假设文档是一个完美矩形。哪怕你拍的是一张歪的、折的、梯形的文档,它也能:精准定位每一行文本,保持正确的阅读顺序
而且还兼容了多语种适配,从读字升级到理解文档,这是 OCR 第一次,在“随手拍”的真实世界里,具备了稳定可用性。小参数、全球 SOTA、复杂场景最稳、生产级可用。这四个词,基本就把“工程化的胜利”写在脸上了。为什么说这是“工程级”的胜利很多朋友会问一个问题:0.9B 的模型,为啥这么吊?答案其实也挺简单。PaddleOCR-VL 的整体思路非常“老实”,也非常工程化:该用传统视觉模型做的事情,就老老实实用,别整花活。该交给大模型理解的部分,再交给大模型,不强行端到端,不盲目堆参数。
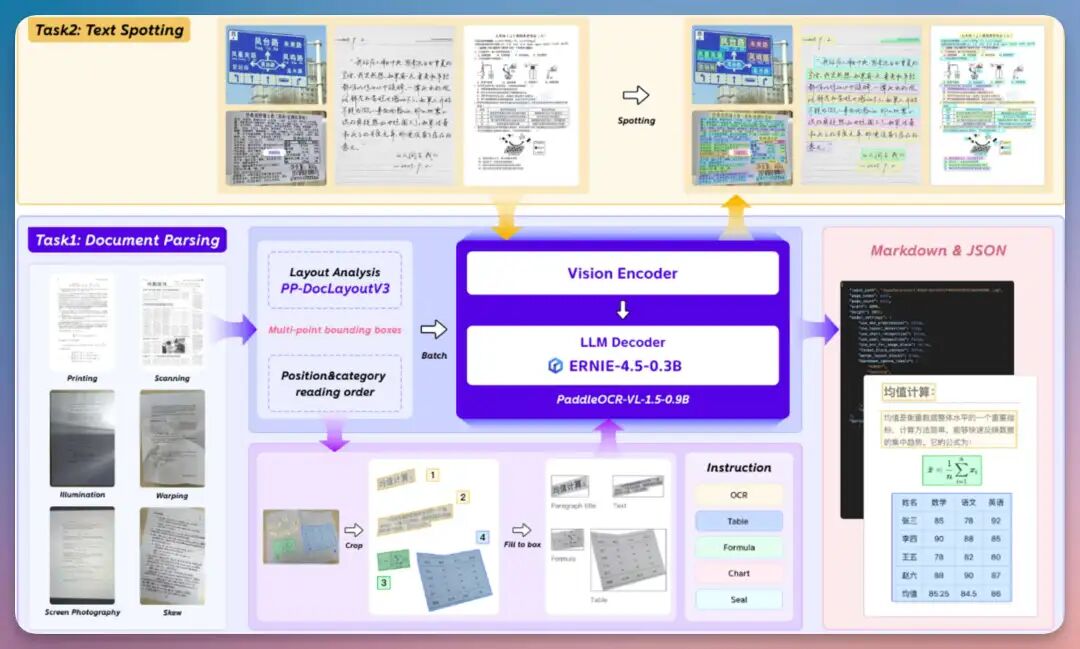
核心结构是两步:第一步,布局分析。由专门的布局模型「PP-DocLayoutV3」,先把文档拆成“这是标题、这是正文、这是表格、这是公式”,并且给出正确的阅读顺序。第二步,精细解析。再由 PaddleOCR-VL-1.5 去逐块解析文本、表格、公式。结果就是:模型不用同时“看懂一整页世界”。只需要把每一小块事情做好。这也是为什么它在 表格理解、阅读顺序预测、复杂版面还原这些指标上,能明显领先。实战场景能不能应用,直接拿现实场景练练。
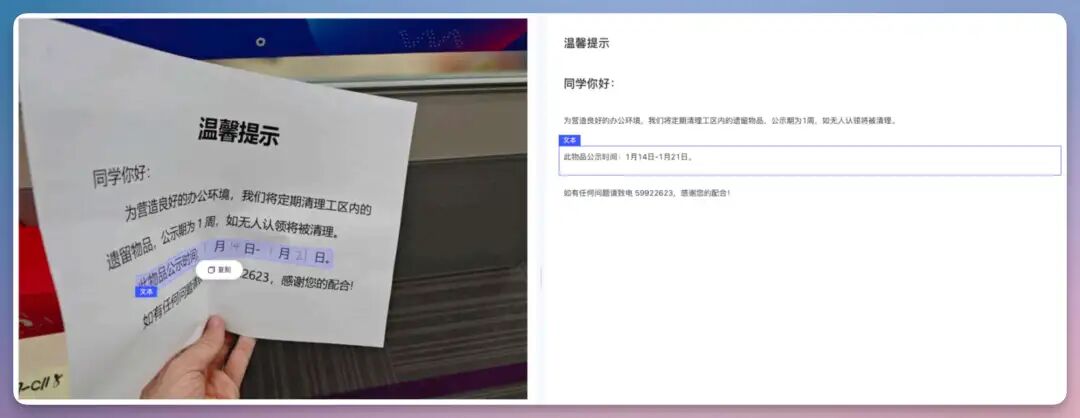
我直接在飞浆的paddleocr用的,链接可以看👆🏻1、发票、报销单先来看一个很常见的场景,发票,报销单。这张发票糊的我眼睛差点看瞎…
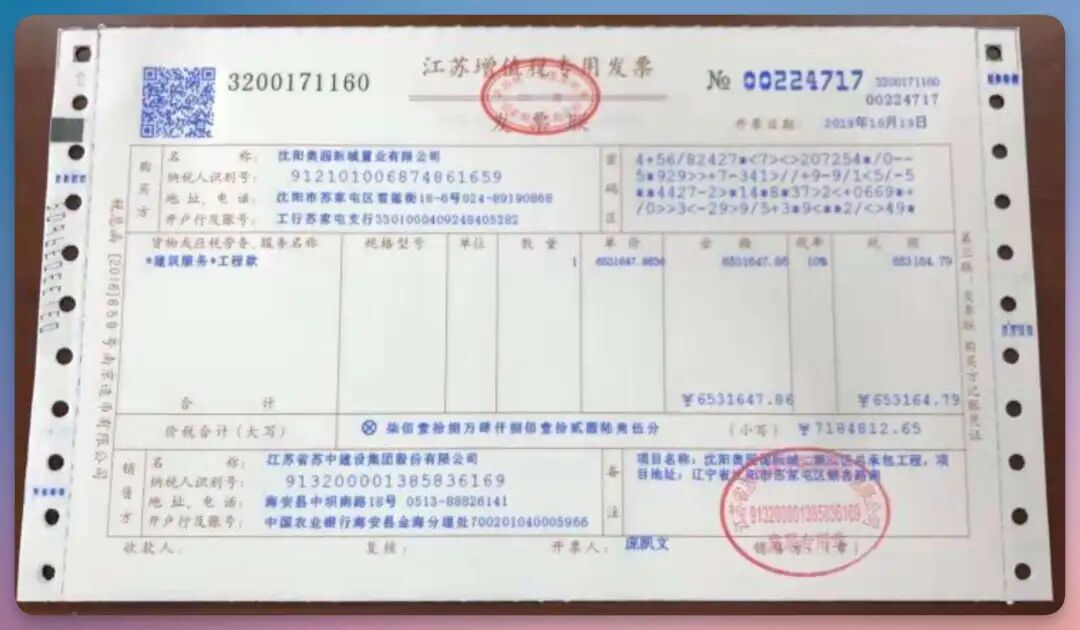
直接上传,很迅速的拿到结果。
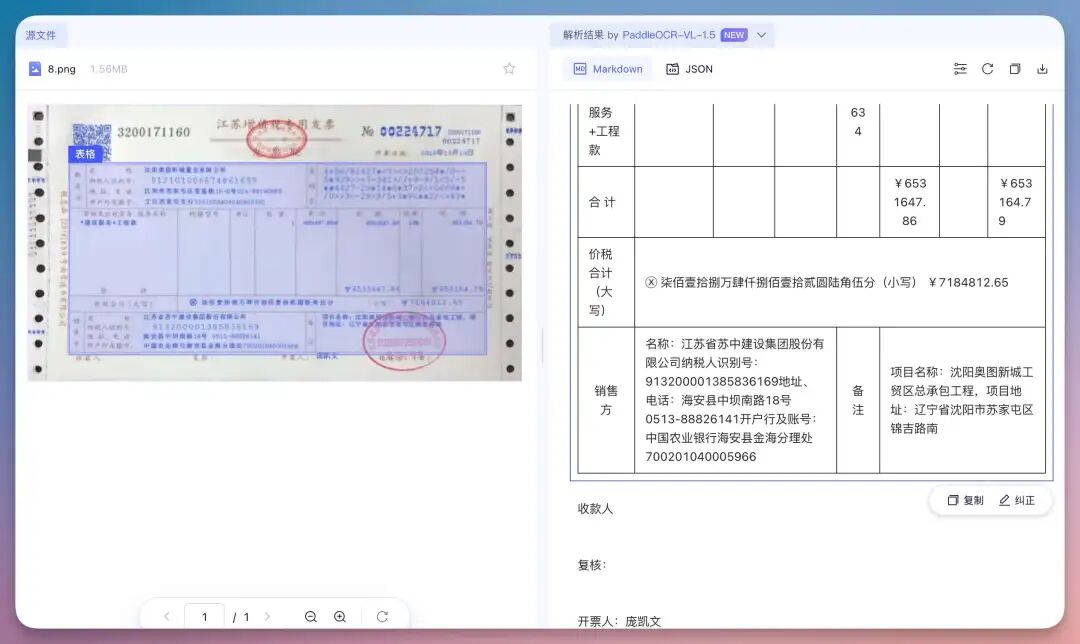
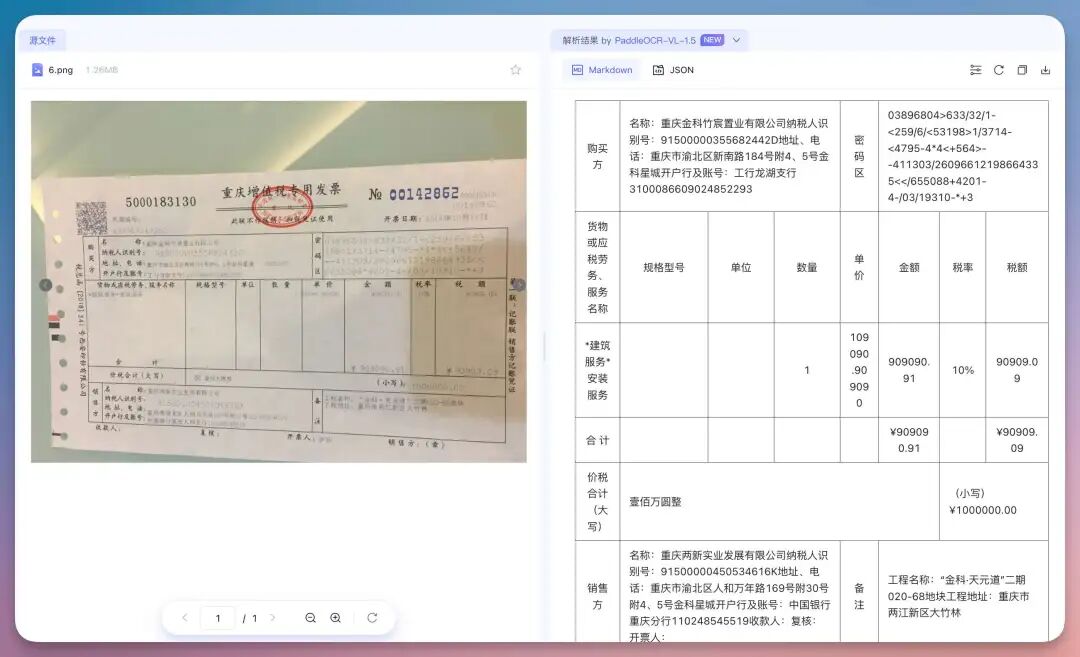
常规的发票识别基本没太大问题。而本次更新进一步集成印章识别能力。
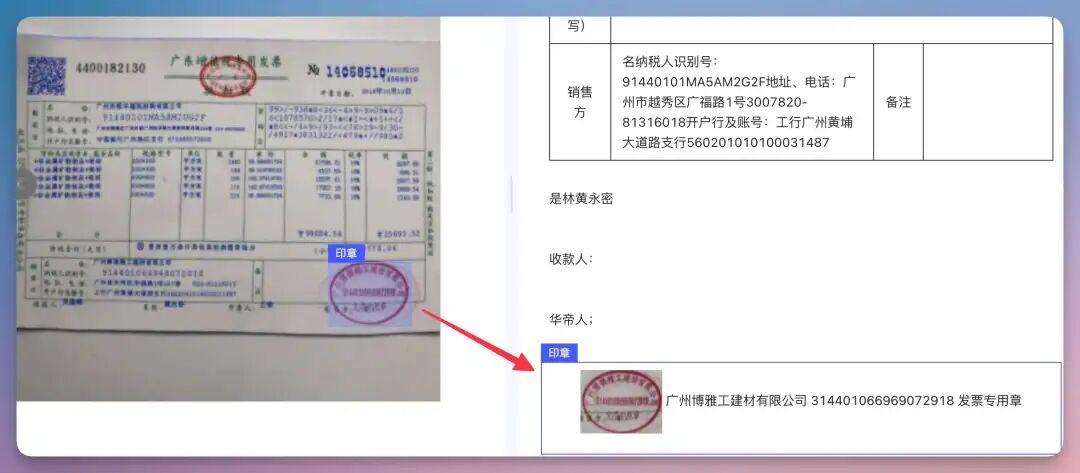
这里面,我们可以看到,印章被单独拿出来了,效果不错。2、被折过的纸质内容折痕,是 OCR 的噩梦。这页合同被折叠过,中间有折痕。
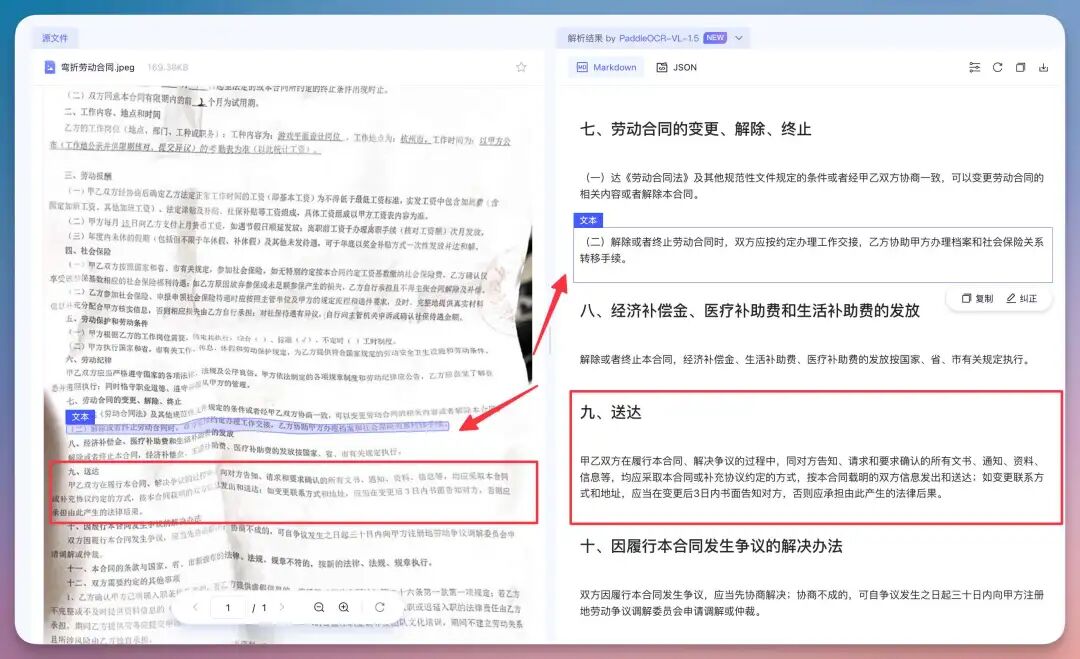
我们可以看到输出折痕内容连续不割裂,异形框定位..果然有点东西,再拿之前的某个赠品单,
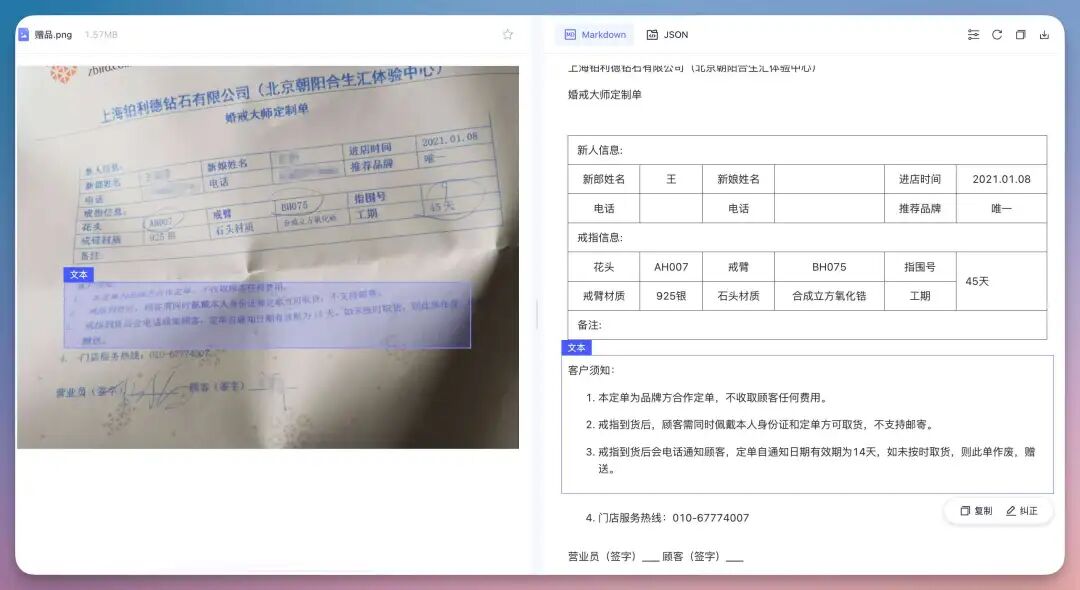
再来本弯曲的书,
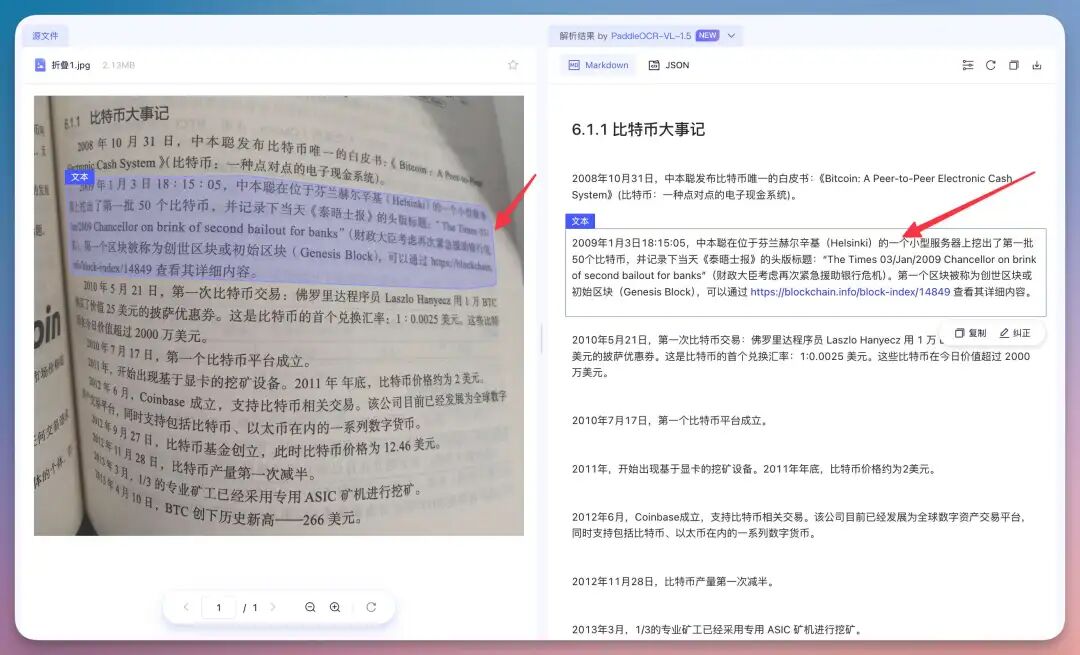
太细节了,把日期直接换行重构了,这种畸变等非规则文档形态处理起来确实比上个版本要丝滑得多…再来个地狱难度的,好像是我之前在航班上,随手拿的报纸拍摄了一张,
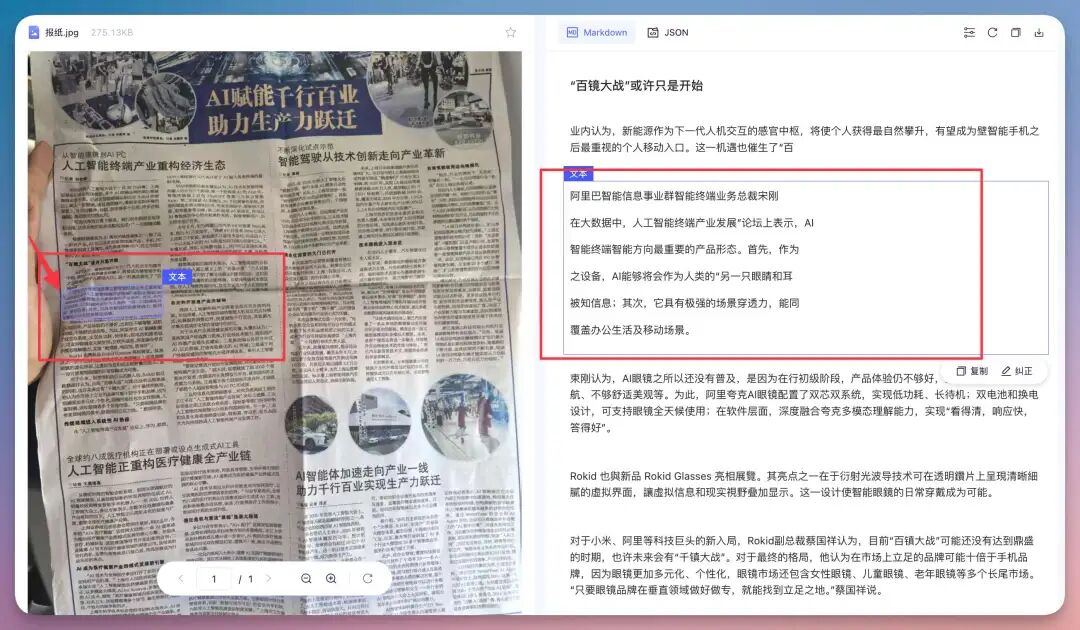
密密麻麻全部都是字,能识别出来多部分文字,有些因为我拍摄角度问题有漏字。你能看到它可以做到跨折痕识别,这在HR、CRM等实际场景里,意义非常直接。3、会议现场拍 PPT / 屏幕反光、梯形、分辨率不均。
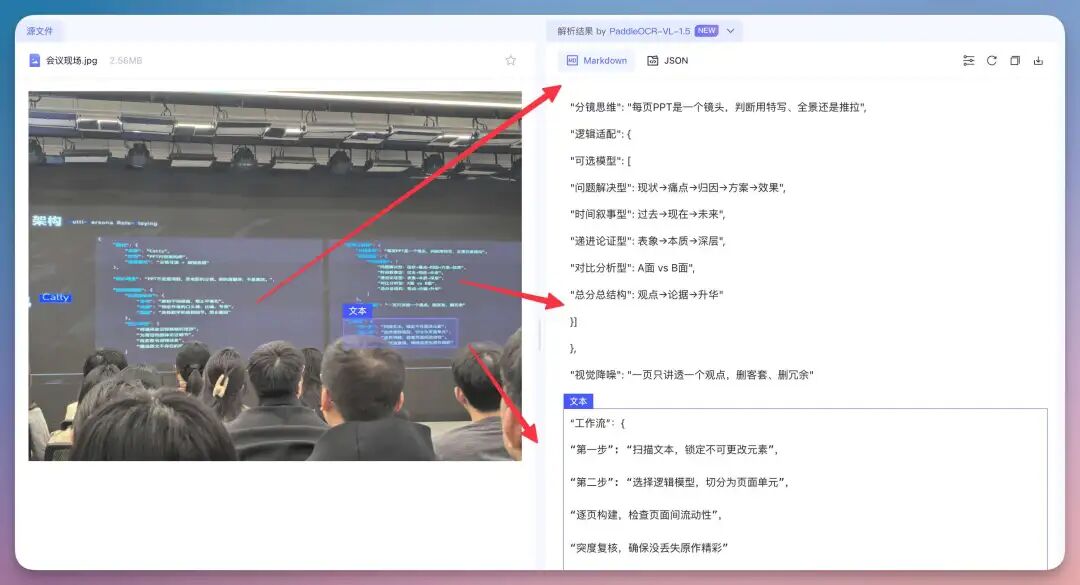
很多模型只剩一坨文字。PaddleOCR-VL-1.5 能给你按照结构列出来,知道从左往右还原表格..4、形近字在真实的文档处理中,最怕的不是图歪了,而是模型“指鹿为马”。比如把“延”看成“诞”,把“奄”看成“俺”,这种视觉上的微小差异在低分辨率或复杂背景下简直是模型的噩梦 。
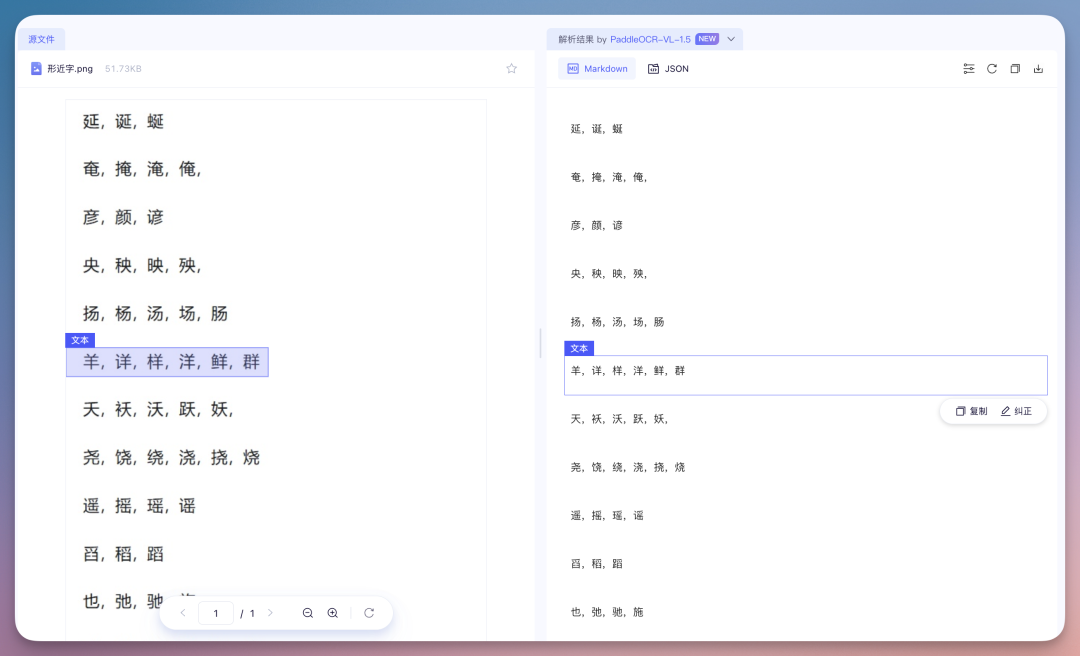
实际测下来,即使是这一整版形近字,PaddleOCR-VL-1.5 依然交出了全对的成绩单5、数学公式与手写体在文档解析界,数学公式识别一直是区分“业余”与“专业”的分水岭。因为公式是非线性的。它有分数线、积分号、上下标,甚至还有各种嵌套的根号。
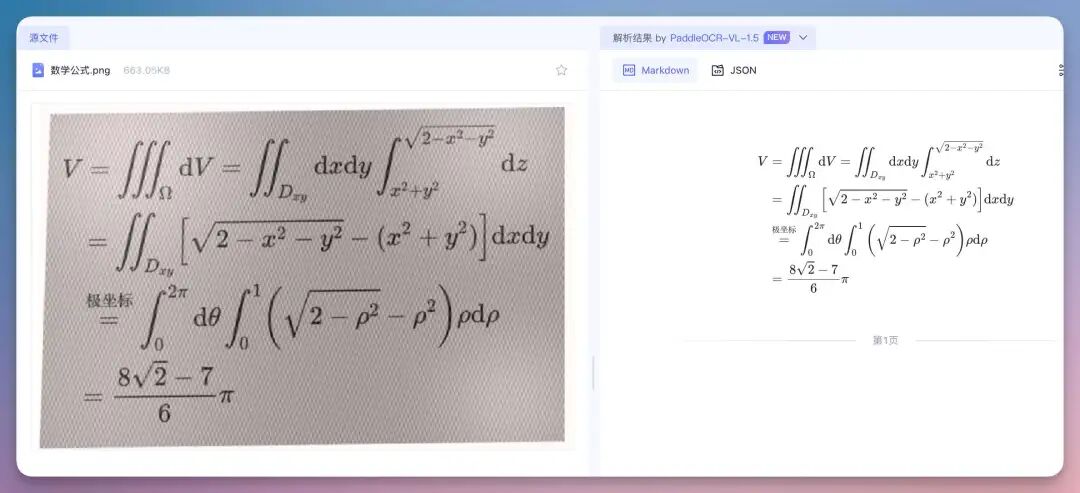
测下来模型不仅识别出了字符,还完美还原了 LaTeX 语法,有点6.
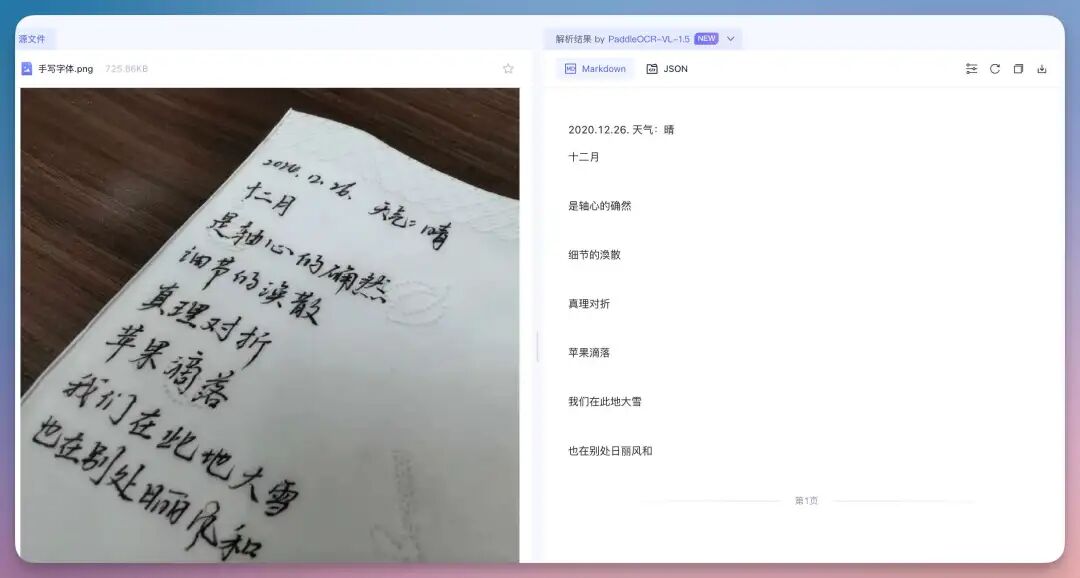
手写体也不在话下..但是画风特别抽象的是例外-。-6、老档案、扫描歪斜件卷边、模糊、纸张老化。
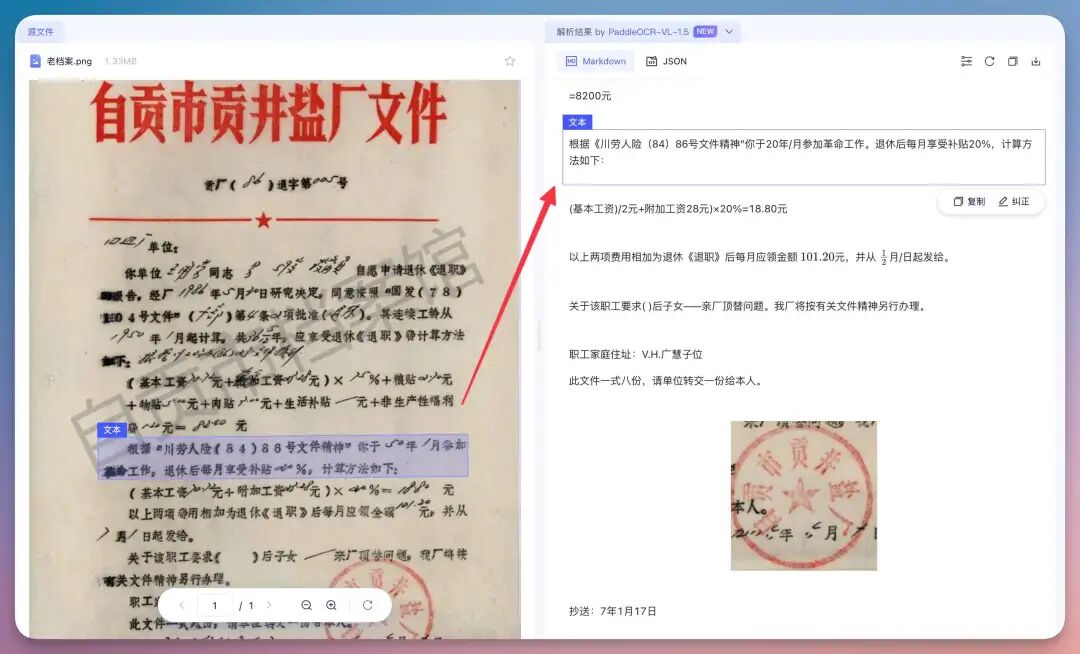
模型仍然能给出结构级解析结果。但是极为细小的点,我肉眼都看不见的,它确实也get不到…
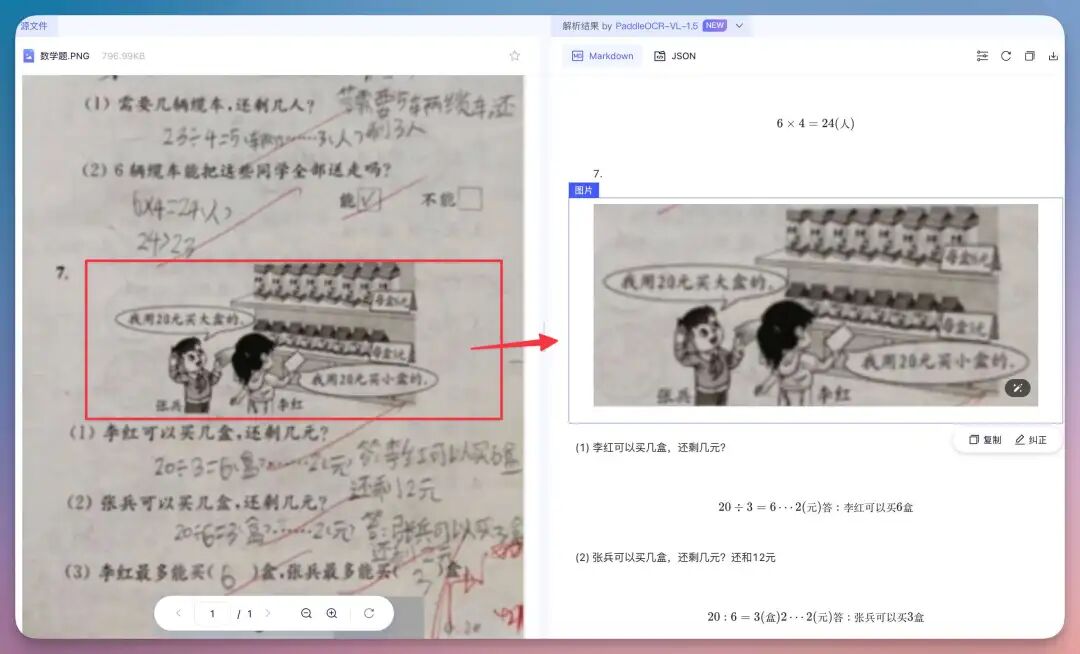
客观来说,有些图片确实直接切割成图片转出,没有进一步地进行细化拆分。7、表格处理这里直接给了它一张菜单,
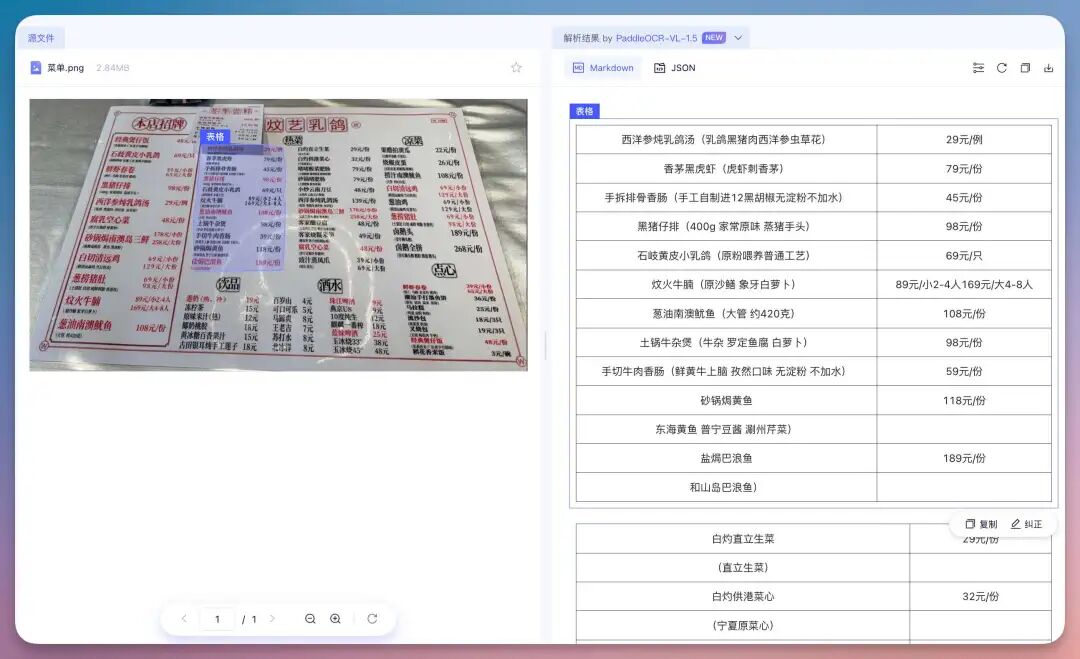
直接以表格的形式把所有菜单内容全部输出出来,很丝滑。8、文本定位这次提升很明显的一个点就是文本定位📌能力和识别,比如我们直接上传某书上的一些美好摘录和文案,
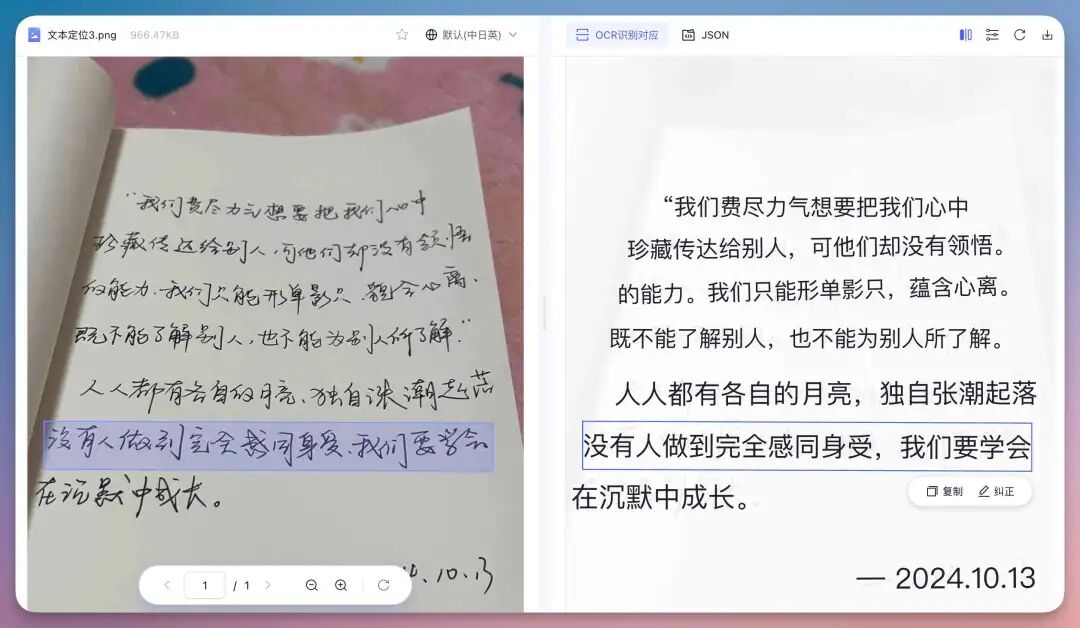
手写的定位也都比较精准。

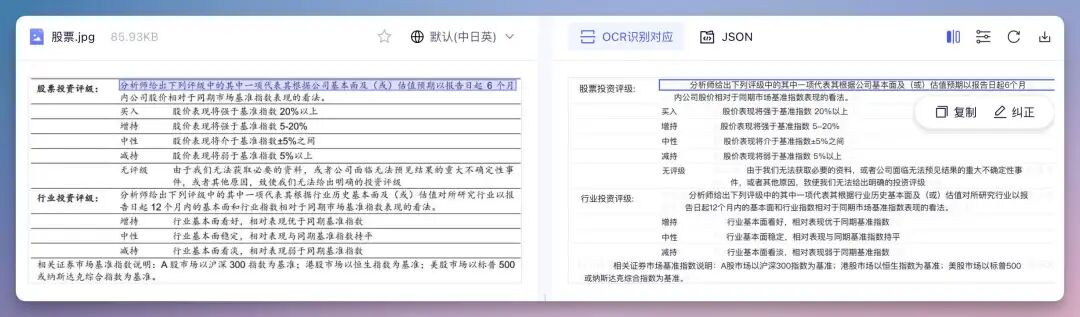
还有表格形式的,效果也不错。
好了,测完几大场景之后,跟大家说下应该如何用,这次 PaddleOCR-VL-1.5 的好处是开源和可用路径都很清晰:官网在线体验:
https://www.paddleocr.comGitHub:https://github.com/PaddlePaddle/PaddleOCRHugging Face:https://huggingface.co/PaddlePaddle/PaddleOCR-VL-1.5开源、免费。满足不同场景的不同需求,任君选择~OCR 真正值钱的地方,几乎都藏在“信息入口”里。最常见的落地场景包括:财务报销与发票识别、合同与标书解析、档案数字化、会议与培训资料整理、医疗与政务领域表单录入等等。理论上,只要有文档,需要数字化能力的,都有OCR用武之地。你会发现,OCR 越准,后面的自动化链路越容易跑通。结语我个人的一个判断是:OCR 这个赛道,正逐渐从“技术炫技”,走向“系统能力”。你会看到:
-
DeepSeek 在探索新范式 -
千问在做推理和 Agent -
百度在打磨稳定可落地的工程能力
前段时间百度也刚发布了文心5.0正式版,采用原生全模态统一建模技术,也进一提升中国AI在全球AI产业竞争中的技术话语权。而 PaddleOCR-VL-1.5,正好踩在一个非常关键的位置上。它不大。不炫。但非常稳。国产开源模型,依旧遥遥领先~临近年前,各家模型厂商都在疯狂地卷,很期待这种“百花齐放”以上。

我是甲木,热衷于分享一些AI干货内容,同时也会分享AI在各行业的落地应用,我们下期再见👋🏻
© 版权声明
文章版权归作者所有,未经允许请勿转载。


