ActionMesh是 Meta(Facebook)Reality Labs 在 2026 年 1 月刚刚开源的一个非常炸裂的 3D 生成模型,全称ActionMesh: Animated 3D Mesh Generation with Temporal 3D Diffusion。简单来说,它能把一段普通视频(单目、真实或合成视频)快速转换成一个带动画的高质量 3D 网格(animated mesh),而且这个网格是:
- 拓扑一致
(topology fixed,整个动画过程中顶点数量和连接关系不变) - 无骨骼绑定
(rig-free,不需要传统 rigging) - 可以直接导入
Blender、Maya、Unity、Unreal 等 3D 软件使用 - 生成速度极快
:通常1–3分钟以内(比之前很多优化-based 方法快10倍以上)
https://huggingface.co/spaces/facebook/ActionMeshhttps://huggingface.co/facebook/ActionMesh
我体验的结果:

导入Blender中看一下原理:
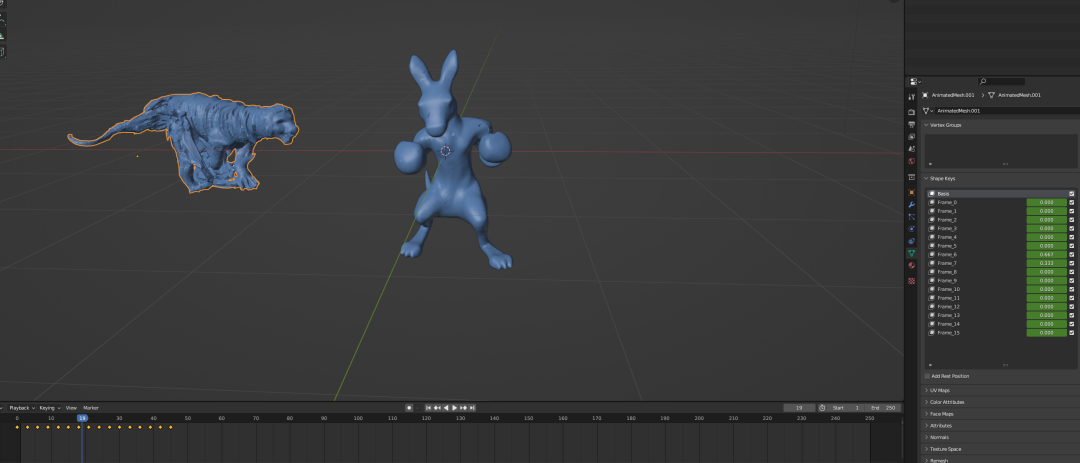
看到它是通过shape keys的动画来完成模型顶点的动画,确实巧妙地省去绑定和动画步骤。看一下布线和UV展开也是很合理的:
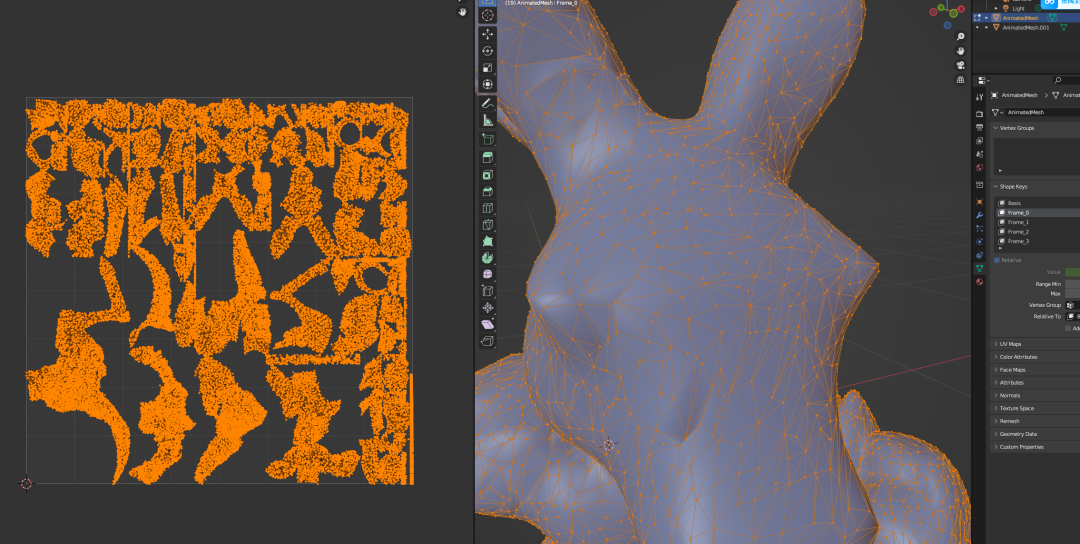
对比绑定效果:

核心技术亮点(Temporal 3D Diffusion)它本质上是把现在的 3D Diffusion 模型(比如生成静态3D物体的那些)在时间维度上做了扩展,变成了时序3D扩散模型(temporal 3D diffusion)。主要分两步:
-
第一阶段:用带时间维度的扩散模型,同时生成一系列同步但独立的3D 形状 latent(每一帧一个形状) -
第二阶段:用一个轻量 temporal 3D autoencoder,把这些独立形状转换成同一个参考网格的连续形变(deformation),从而得到动画
这种方式避免了传统方法常见的两大痛点:
-
每帧独立重建 → 拓扑不一致、闪烁严重 -
先做静态重建再加 motion → 运动和几何经常对不齐
支持的输入方式(不止视频)
- 视频 → animated mesh
(最强表现,主打功能) - 单张图片 + 文本描述动作
→ 先生成物体,再给它动起来 - 纯文本
→ 从零生成一个角色 + 动画(text-to-4D) - 已有静态3D网格 + 动作文本
→ 给已有模型赋予动画
以后可能有哪些用途?
- 游戏开发
快速把真人表演、动作捕捉视频转成游戏可用资产,省掉建模+绑定+动画的大量手工活 - 短视频/虚拟人/直播
把真人跳舞、说唱、表演直接转成卡通/写实3D虚拟形象 - 影视/广告预览
快速把导演拍的参考视频转成3D粗模,用于分镜、灯光测试 - AR/VR内容生产
手机随便拍一段,就能得到能在头显里随意观看角度的3D动画物体/人物 - 电商/元宇宙
商品视频直接转3D可动模型,让用户在虚拟空间里多角度看、互动 -
普通人拍个vlog就能自动生成3D版自己 -
AI导演:文本+参考视频 → 直接出一段可自由机位渲染的3D动画短片 -
游戏/虚拟世界自动生成NPC和环境动画 -
教育/医疗模拟:把手术视频、体育教学视频快速3D化,用于多视角教学 -
数字遗产:把历史影像、老电影转成可交互3D内容
总之,ActionMesh 是今年(2026)开年最重磅的视频到可生产级4D资产的开源工作之一,把“视频随便转3D动画”这件事的门槛又狠狠降低了一大截。
© 版权声明
文章版权归作者所有,未经允许请勿转载。