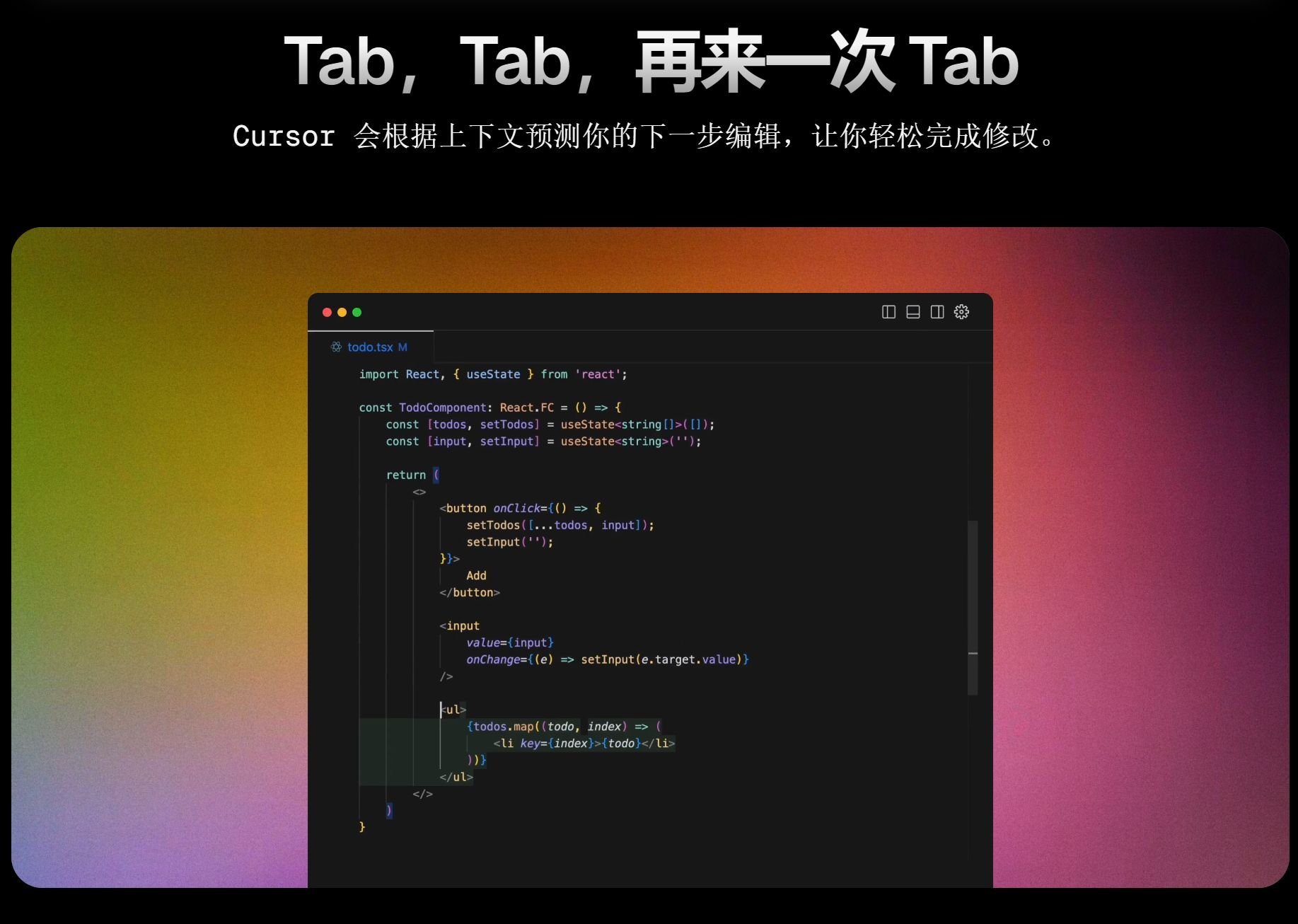
先超简单回顾一下Seedance 2.0是怎么用的,在即梦里使用视频生成模式,打开全能参考,就可以上传文件生成了,豆包和小云雀的互动逻辑也都差不多。

Seedance 2.0现在支持图像,视频,音频,文本四种模态输入,混合输入总上限是 12 个文件,量大管饱,更加具体的一些操作方法,大家可以看我上次写的这篇文章。史上最短字节Seedance2.0AI视频小白教程!这两天即梦还上线了图片5.0 Preview(也就是Seedream 5.0 Lite)图片模型,4k版本目前只有在即梦上才能体验,这次我结合在一起玩了一下。

Gogogo,快来看看这一大筐玩法,以及Seedream 5.0 Lite和Seedance 2.0的组合用法,首先就是我一直想做的,让我家小猫和奥特曼对战的一个场景,之前要用两个模型,一个Banana2生成九宫格,一个sora2在九宫格基础上生成视频,但现在Seedance 2.0也可以做出九宫格分镜图生成连贯视频的操作了,动作和运镜转换超级丝滑,论导演的分镜思维这块。。。
操作过程so easy,先用我的小猫生成一张和我想用的角色对战的场景图,5.0 Lite 现在目前对于角色的复刻做得还是不错的。然后我可以直接用这张图片,让 5.0 Lite给我做一张九宫格的分镜图,

然后这张图可以直接通过生成视频的小窗跳转到即梦下方的生成视频功能,步骤非常方便,

再用这个提示语就能做出上面给到那个带有动作和运镜的连贯打斗镜头了。
如果你不知道这些动作要怎么写,我们也可以直接给 Seedance 2.0 提供一个带有动作的视频,给出人物形象图片还有场景图,让这些人物出现在视频中,并按照你提供的视频动作进行打斗对战。这里需要注意的是,上传的视频素材必须在 15 秒以内。而且即梦对于素材的尺寸有很高的要求,我这里实测,只要提供 720p 左右的视频素材基本上都是可以的。

我这里直接做了一个对比,将我提供的原始打斗动作视频与生成的视频进行了演示。我提供的原始视频实际上只是一个没有经过渲染、类似建模画面。但是,它可以直接把我想要的人物按照视频中的形象和风格渲染上去。人物动作,分镜和运镜几乎与原视频保持的非常一致。说实话,以前要是按照提示语去写这样的一个分镜图或者画面内容,不知道要写多少提示词才能做到。但今天 Seedance 2.0只要给个视频就可以了。
当然,如果你想自己输入一段非常简单的提示词,它也可以做出一段非常精彩的打斗效果。

这里我尝试让自己和我家的猫进入到最近很火的“邵氏兄弟武侠电影风格”场景中,实现了一段非常流畅丝滑的打斗。这三天测试下来,我发现如果只是提供图片作为参考,所消耗的积分要比同时提供图片和视频素材给模型参考时要少一半。
或者你就是想复刻某一段动画里的运镜镜头,也只需要把想要复刻的片段上传上去,这里我用到的人物、大鸟坐骑以及场景图片,都是用Seedream 5.0 Lite图片模型生成的,不同的主体也能保持一致的画风。



然后写好下面这个提示语,其实主要就是把每一张图片中的人物,对应视频中的哪一个元素写清楚,然后就可以直接生成了。

我同样是做了一个原视频和生成视频的对比效果,
虽然不是百分百完全复刻,但是这个效果至少已经能够做到七八成。而且,整个镜头中比较明显、比较突出的运镜也已经做到了。就这个效果放在之前,我是会有质疑到底能不能通过提示词做到这种运镜效果的。还有一个很好玩的是,我们其实可以直接用 Seedream 5.0 Lite图片模型去做一个四格漫画,提示语这里我有一个模板,大家可以根据这个剧情去修改,这个5.0图片模型的文字效果稍微有点弱,但是他们会在年后对这个版本进行一个更新。
角色设定同一位男主角,普通打工人,黑短发,灰色卫衣或灰色T恤,背单肩包同一位上司,深色西装或衬衫,表情严肃
四格分镜与台词第一格,办公室门口,男主探头进来,满头汗,上司站在门边盯着他男主气泡:不好意思我迟到了,路上堵车上司气泡:你家到公司三分钟路第二格,镜头更近,上司皱眉,男主认真解释男主气泡:电梯坏了,我走楼梯上来的上司气泡:你在一楼第三格,男主表情更紧张,突然灵机一动,抬手比划男主气泡:我在路上还见义勇为了上司气泡:你救了谁第四格,反转,场景切到公司楼下花园,男生和另一个老头聊天,那个老头说:“你好,我叫义勇为”
画面要求四格边框清晰,气泡不要遮脸,字要清晰不糊,上司表情要有那种无语凝噎的停顿感,整体节奏轻快。
然后我们就可以得到这样的一张四格漫画图。

把这张图片放到 Seedance 2.0 中,再给他一个你想要展示的动画视频类型,让他学习这段动画的风格,再给他这段提示词,

他就可以直接帮你复刻,把四格漫画做成一段连贯的小动画。我宣布AI漫剧这块我承包了!
或者我可以让他直接给我复刻抖音上很火的 @陶阿狗 的特效视频,我直接用它做了一个小猫版本的。

实话实说,如果是让我自己手抠的话,我是做不出来的,但是现在Seedance 2.0做到了。还有一个很牛的就是 Seedance 2.0 还可以做出文字或者logo的释出动画,我还直接用提示词让他给我做了一个我自己的 logo 文字视频动画。这要是放在以前,绝对是要会AE的人才能做出这种效果。。。

之前即使我用 AI 去做这种类型的文字动画,给到的版本其实还是稍微有些粗糙的。但是现在Seedance 2.0给到的版本,几乎和AE渲染的没差别了。更厉害的点是,Seedance 2.0可以直接根据我们提供图片中的文字去生成一段视频。我测试了很多遍,提供的文字内容我们要判断一下能不能在15秒内呈现出来,塞的内容不要太多。这里我给 Seedance 2.0 提供了三张十日终焉开头的小说截图,然后它就给我生成了对应的剧情。



你们可以看到,它对应这些图中的文字,呈现了一整段的内容(虽然时钟的时间错位了),我觉得看过这本小说的人就能发现,这个味道是特别对的。尤其文字中会有很多对于环境氛围的描述词,包括人数、整体的氛围感,它都拿捏得很到位,而且还能自动生成文字不崩坏的字幕。这里有一个小 tips,如果大家在使用 Seedance 2.0 的时候,会发现它在 80% 以上的情况下,都会自动给视频加上 BGM 和字幕。如果大家不需要音乐和字幕,可以直接在提示词中告诉它“不要 BGM”,“不要字幕”就可以了。甚至不只是这种纯文字图片,如果我做好了一个脚本,我甚至可以把这种表格形式的脚本图片发给 Seedance 2.0,让它直接根据脚本中的分镜去做一个完整的视频。

整个视频呈现出来的效果让我非常震惊,它真的能够识别每一个镜头对应的画面景别,人物对白等细节,然后直接输出一个成片给我。

说实话,这个真的让我有点惊到了。如果你是一个做广告的公司,甚至可以不需要预拍了,去给甲方提案的时候可以做个成片,让他们看预览效果。如果你提供了一个完整的产品图片,这甚至能作为一个几乎可以完整使用的小片。目前唯一需要提升的就是 Seedance 2.0 的清晰度。如果清晰度能再进一步,我觉得甚至可以直接拿去用了。最后就是藏师傅发现的,可以直接上传一些我们平时旅行时拍的照片,让 Seedance 2.0给我们做出一段Vlog。

我年底去马来西亚拍的照有救了,
它没有改动原图,而且还会卡点,加一些小特效。我没有告诉它我去游玩的地方是哪里,它竟然能够识别出来,说明它是有一定的世界知识的。平时分享生活肯定够用了,甚至弥补了一些朋友在出去玩回来后,想做动态视频展现却觉得花时间、麻烦、有难度的痛点。没想到这一圈盘下来,排队就排到晚上十点了,但隔壁老外比我更惨,排都排不上,

这两天还有人发现有的时候不能传真人素材,我去验证了,目前在web端确实提醒了暂不支持真人人脸,但在app端,完成真人校验后,你依然可以让自己出演AI视频。这是一个必然的过程,一方面,像Seedance 2.0这样强大的模型,它在技术上追求生成内容的极致真实。因为它知道,更强的复刻能力,意味着更强的艺术表现力,能为我们创作者带来更大的创作自由。但另一方面,平台也在积极地探索,如何为这种强大的能力,建立起必要的护栏。在鼓励创作和保护个人信息安全之间,寻找一个微妙的平衡。当AI生成的内容,在像素层面,在物理规律层面,甚至在情感表达层面,都达到了与真实世界难以分辨的程度时,我们该如何与之共存?今天的Seedance 2.0,其实已经给了我们一个答案的雏形。平台和我们创作者要做的,就是共同去建立一套成熟理性的规则。我们追求AI的真,是为了让我们的想象力,以最逼真的方式呈现同时,我们也需要一个清晰的边界,来守护真实世界里,每一个人的权利和尊严。
@ 作者 / 阿汤 & 卡尔
© 版权声明
文章版权归作者所有,未经允许请勿转载。