
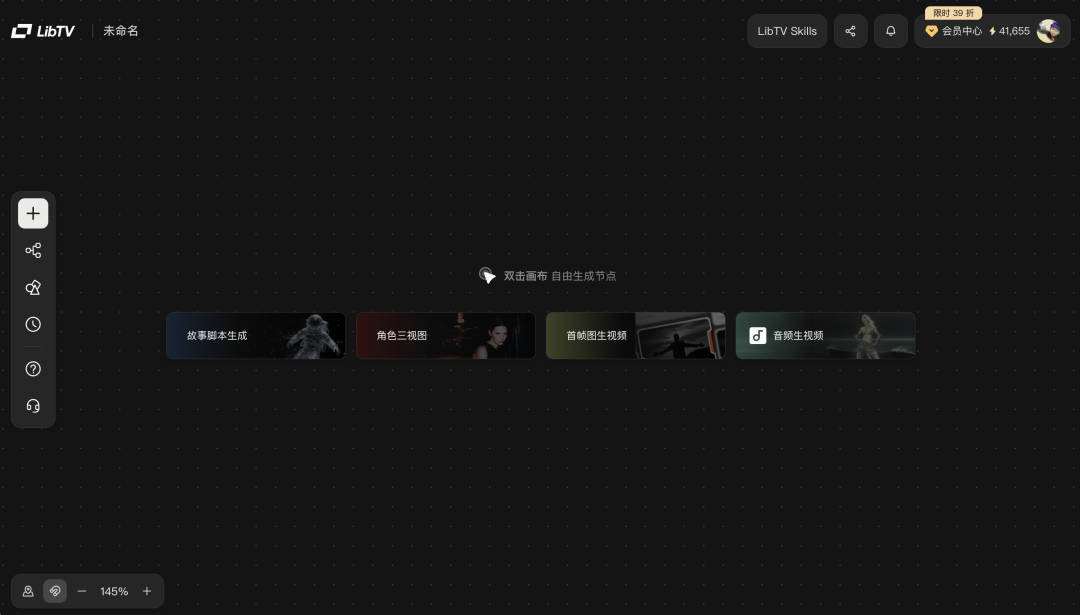
🔗 liblib.tv重要的是,LibTV已经有了自己的 Skill,能够连到 OpenClaw 里面用,这下我的虾又变厉害了!那我这次先直接按照我之前的创作习惯,在 LibTV 里做了一个蒙娜丽莎出逃的小短片,可以调用我们目前能用的几乎所有图片和视频生成模型。
实际上上手非常快,基本上没有什么学习成本,你只需要会创建节点,拉节点,写提示词进行生成就行了。
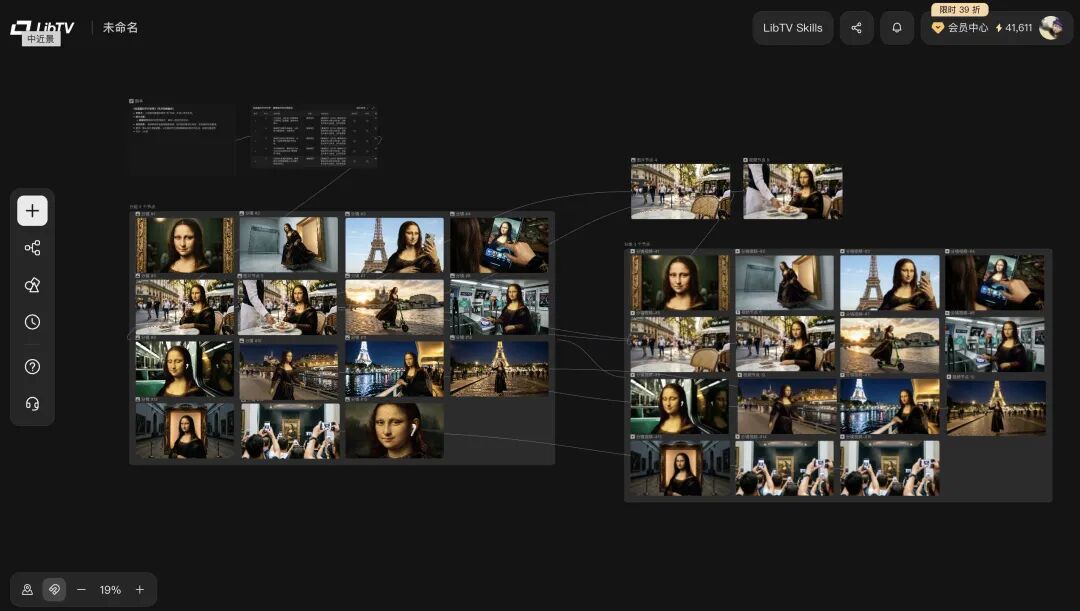
而且 LibTV 可以根据你给的一个大概的剧情自动设计完整的分镜脚本,支持一键批量生成分镜图片和批量生成视频,做起来速度非常快。

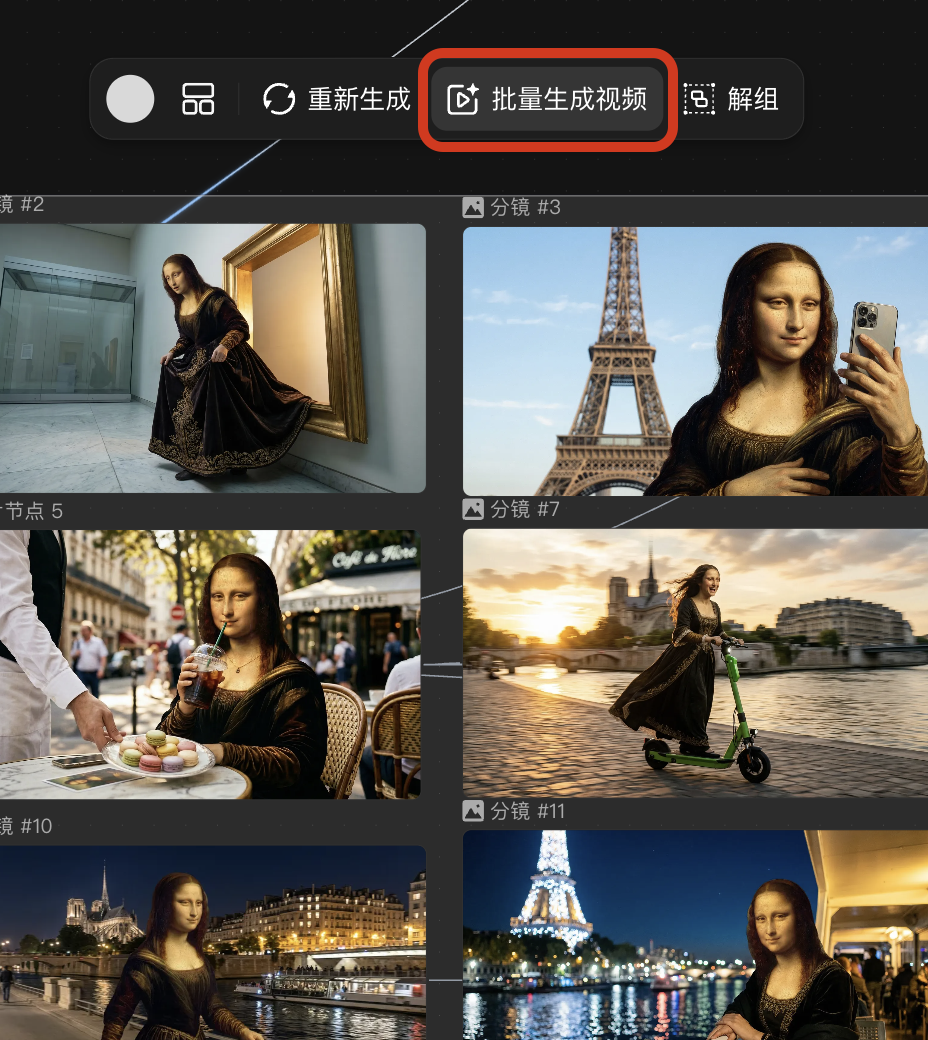
而且除了图片,视频生成之外,LibTV在图片编辑和视频编辑方面的功能也非常全面。比如我们生成一张图片之后,点击它会发现,上面的功能栏里面几乎囊括了目前所有 AI 图像编辑方面的功能,高清,扩图,重绘,擦除,抠图这些都有。
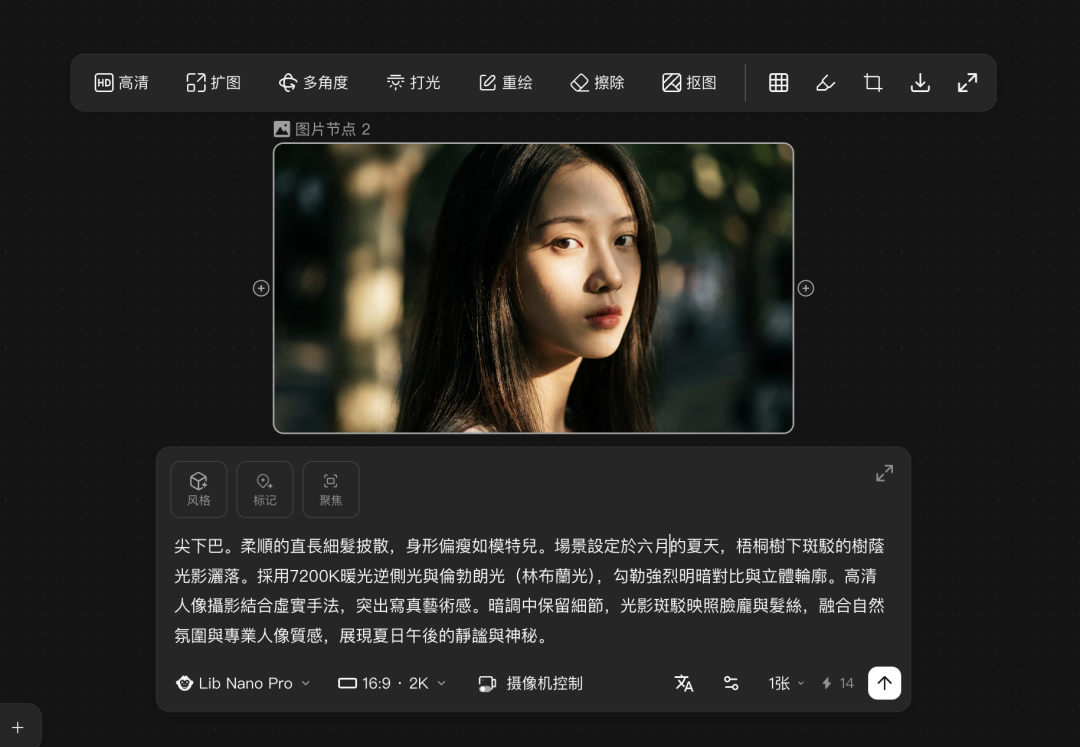
除了这些生成功能之外,这里还有四个我个人觉得比较有趣,而且实用性还挺高的功能,多角度、打光、摄像机控制和九宫格切分。首先是多角度这个功能,可以通过拖拽摄像机来调整拍摄的角度,这样就非常直观,能够迅速找到自己想要拍摄的位置,从而得到相应的图片。试了几次,这个角度调整还挺精准的。
还有这个打光功能,也可以直接拖拽去调整光源的位置和颜色。而且如果你不好把握光源位置的话,也可以直接用它提供的一些主光源位置。通过这个功能,我们可以非常直观地得到想要的打光角度。最终生成的图片效果,与我设置的光源位置和颜色都是完全一致的。
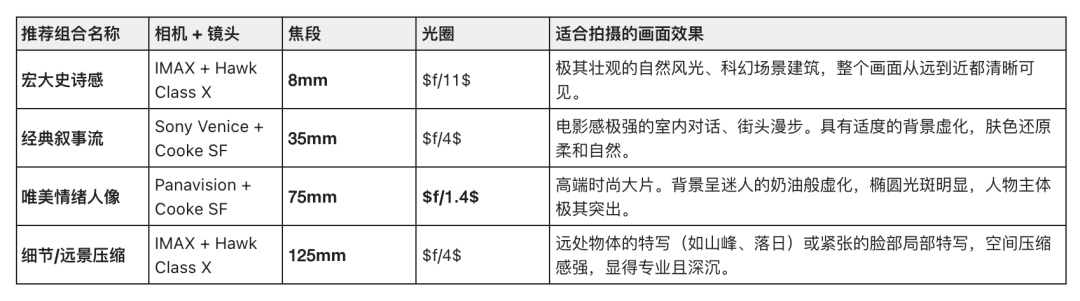
还有啊,LibTV做了一个摄像机控制功能,内置了非常多的相机种类,镜头,焦段和光圈,可以适应多种场景的需求,比如这里有四张图,就是我用同一张图作为底图,使用了同样的提示语,但是用了不同的摄像机组合来做出的图片,摄像机镜头、焦段和光圈的不同搭配,其实能够做出不同的效果。对于一些非常懂摄像机方面专业知识的人来说特别友好,能够精准地得到自己想要的光线和拍摄角度。
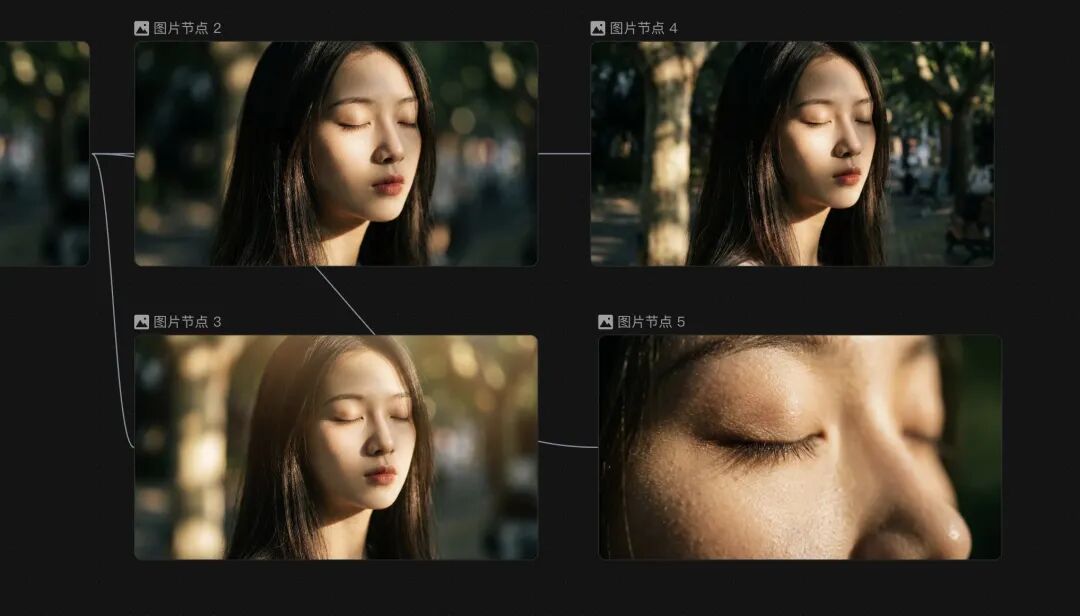
这里我还总结了四组适合拍摄不同类型画面的镜头组合,大家感兴趣可以自己去尝试一下。
还有一个九宫格切分的功能,我觉得也很有用。之前我们玩 AI 视频的时候,经常会用到一种用九宫格去生成一整段视频的玩法。但是中间经常会出现一些问题,比如某一个分镜可能不太准确,而其他分镜做得很好。针对这种情况,我们可以直接把九宫格拆分成九张图:你可以对每一张图单独去生成你想要的分镜,生成后可以替换回原本完整的视频里。或者如果你对其中某一个分镜图不是很满意,或者它有一点 bug,你可以单独去修改这张图。这样的话灵活性就更高了。
再有就是在生图节点上,LibTV 也有很多已经内置好小功能。我们在视频创作过程中,经常会要修改部分分镜图片,这几个都是我觉得会经常使用到的,这样已经把这些提示语内置成了固定的功能,会非常方便。
那到了视频生成阶段,一段视频生成完成之后,你还可以继续对这段视频直接进行剪辑,或者高清处理。这里还有一个功能叫做解析。
它可以直接把一段视频拆成分镜脚本。这样的话,假设你有一个想要参考的视频创作,你可以用 LibTV 去分析它的分镜,得到分镜脚本,然后再按照这个脚本进行修改,生成自己的内容。

在OpenClaw里用LibTV也很简单,
只要发一段文本就行,
然后就是在网页版的账号设置里拿到AccessKey,再发给OpenClaw完成配置和第一次测试。
也可以直接在飞书上传一个视频,让他调用 LibTV 去模仿这个视频做一个。我这里给了他经典的腾哥的你过来啊片段,然后得到了一个 3D 动画版本的,实际上效果也还不错。
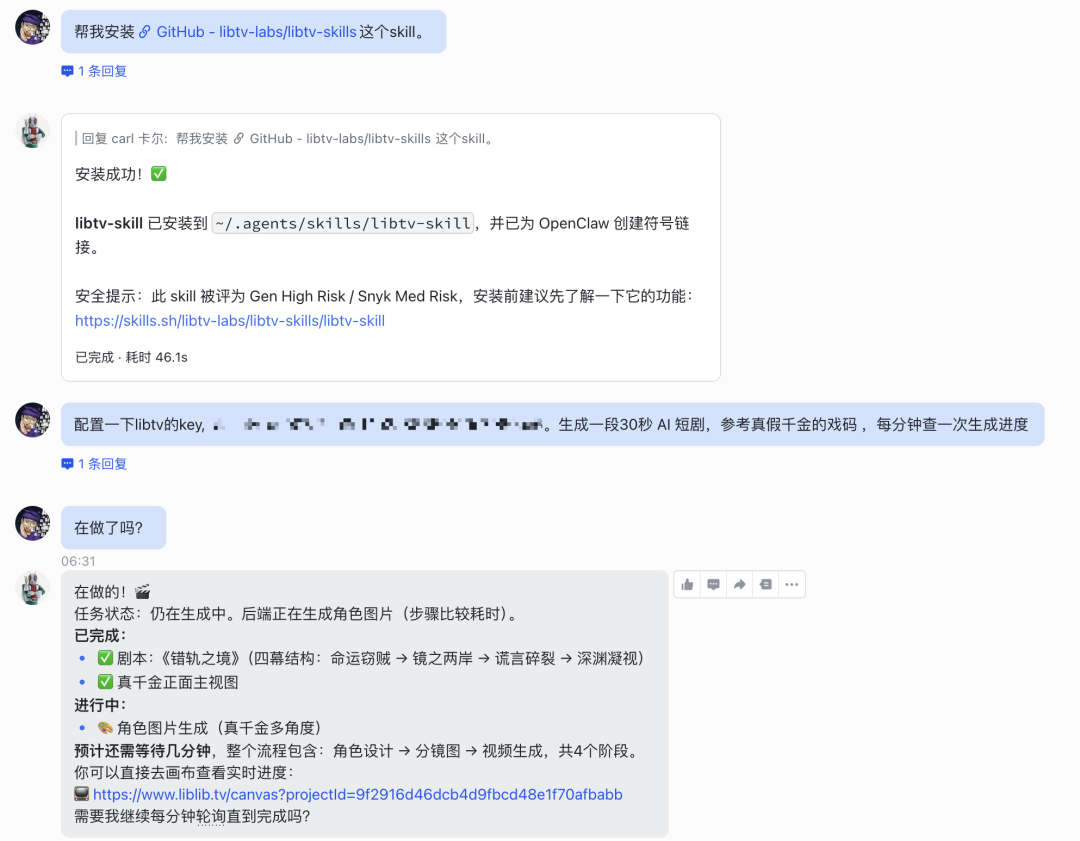
libtv-skills在安装完成后给我发了一个说明文档,我用GPT总结了一把。简单来说,这个Skills在实现上只依赖Python标准库,不需要我们电脑再额外安装第三方依赖。上传文件支持图片和视频,大小在200MB以内。那它跟我们看到的封装了一些视频模型API能力的Skills有什么不同呢?

libtv-skills相当于一个中间层,API封装的Skills是把我们在网页版上操作流程组成脚本,我们要自己去完成提示语的编写,流程推进等等。但libtv的思路是尽可能让用户用自然语言表达意图,由他们的视频Agent来完成统一的编排。最后的最后,又到了紧张刺激的价格环节,用Agent生成,调用模型的次数是会比手动的平均要高,靠量来换审美,一次抽卡不好,我就抽十次选最好的。所以价格不压下来的话,就很少有人会用Agent直接成片的。LibTV目前的定价是年卡最低39折,我是直接入了一年先踩踩坑。而且就现在的趋势来说,我觉得人和AI会变得越来越融合。人类提出想法,AI帮我们去完善这些想法,帮我们执行中间的一些过程。而最终拍板整个故事走向哪一个分支的,永远都是我们。
@ 作者 / 卡尔
© 版权声明
文章版权归作者所有,未经允许请勿转载。