








其实事情得从前两天说起。那天我去参加观猹的线下活动,跟聪哥碰头。聊到一半他突然神神秘秘跟我说:“甲木,我最近测了阿里刚出来的 Qwen 3.7-Max,有点东西,强烈建议你也试试。“聪哥是行走的 Qwen 代言人,一旦 Qwen 出好东西了总是会给我安利,然后我就当场掏出手机找阿里云的同学”刷了下脸”,要到了内测白名单。晚上回到酒店,模型到手,琢磨搞点什么东西来测测模型能力,想了想——决定用 Qwen 3.7-Max 写一款武侠 RPG 页游,看看它效果怎么样。
最近这一年,AI 圈两个词:VibeCoding和VibeWorking。前者是”氛围编程”,后者是”氛围工作”。本质上都是让 AI接管一段过去需要专业能力才能完成的工作流。
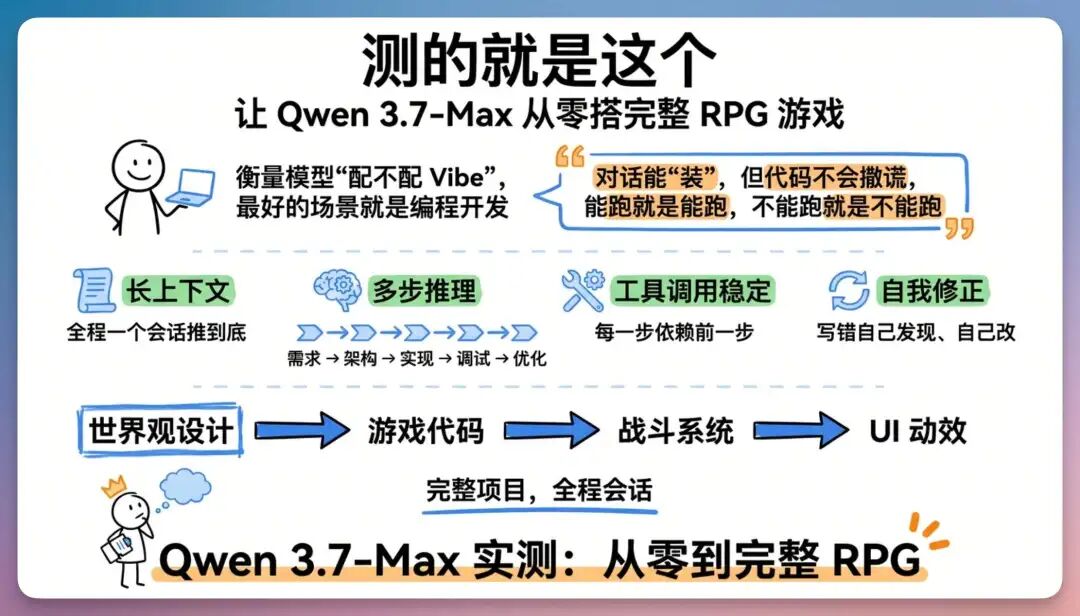
听着挺玄的,但底层逻辑只有一句话——所有的 Vibe,都建立在底座模型够不够硬的基础上。你让一个能力一般的模型去 VibeCoding,它跑两步就丢上下文;让它去 VibeWorking,它做完一个环节就忘了上下文。Vibe 不起来,反而比自己干还累。所以我一直觉得,衡量一个模型”配不配 Vibe”,最好的场景就是编程开发。它要求你有长上下文、多步推理(从需求 → 架构 → 实现 → 调试 → 优化,每一步都依赖前一步)、工具调用稳定,还能自我修正(写错了得自己发现、自己改,不能傻等用户指出)。
对话能”装”,但代码不会撒谎,能跑就是能跑,不能跑就是不能跑。我要测的就是这个。让 Qwen 3.7-Max 从零搭一个完整的 RPG 游戏项目,从世界观设计到游戏代码,从战斗系统到 UI 动效,全程一个会话推到底。能跑通,它就还算可以。
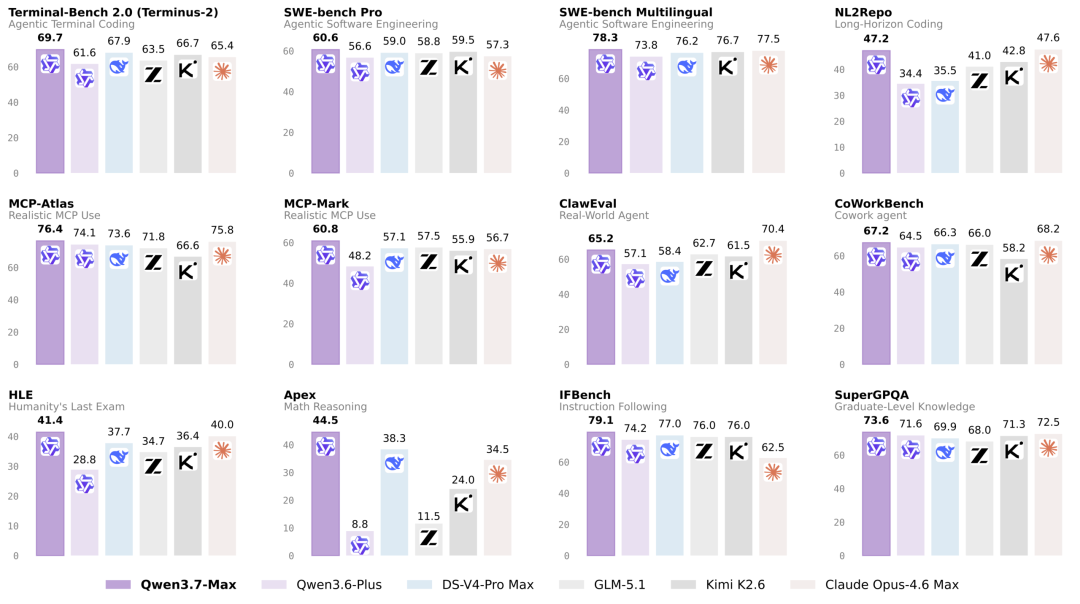
正式开测前先简单交代一下背景,不啰嗦,三段说完。▎第一 · 编程榜单全面上探Qwen 3.7-Max 在真实智能体编程榜 Terminal-Bench 2.0 Terminus 上拿了69.7 分,超过了 DS-V4-Pro Max 的 67.9 分。
▎第二 · 推理能力刷了一堆纪录详细数据大家可以看下面文章。
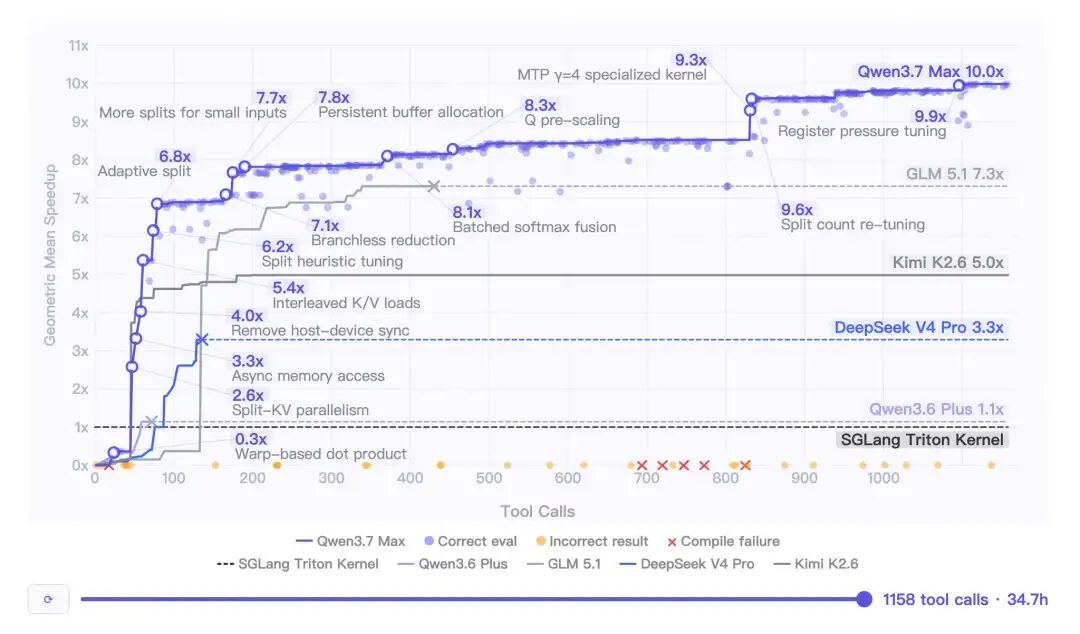
▎第三 · 长程任务能力是这次最炸的点官方放出来的一个 case 是:在一颗它训练时从未见过的全新芯片(平头哥真武 M890)上,Qwen 3.7-Max完全自主跑了 35 小时,独立做了432 次内核评估、1158 次工具调用,从零写出一个 CUDA 注意力内核,最后比 SGLang Triton 官方实现快 10 倍。
运行到 30 小时它还在发现新的优化点,甚至主动发起了一次架构重设计。“模型能在长链路任务中不丢上下文、不胡说八道“,是用好的关键,这也是我接下来这个 RPG 开发要重点验证的。当然,榜单数据仅供参考,还是要通过实战来看看效果到底怎么样。
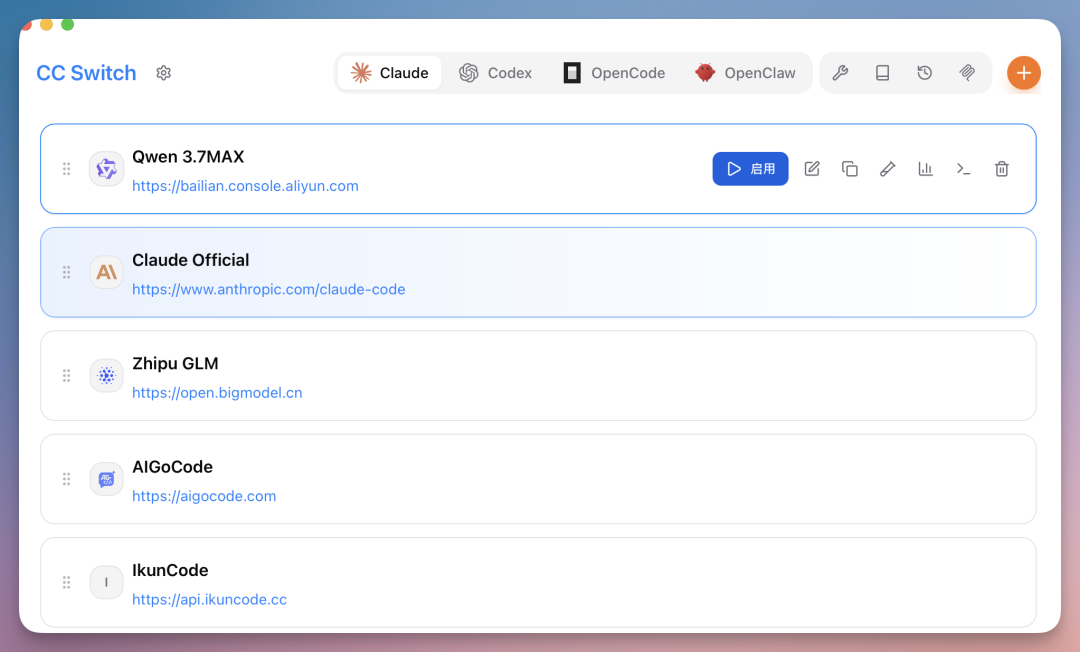
我用的是这套组合:
CC Switch 是个挺好用的小工具,可以把底层模型一键切到 Qwen 3.7-Max。
然后我用的本地 Superpower Skills,这是一套我自己常驻在 Claude Code 里的 Skill,里面包括 brainstorming、writing-plans、subagent-driven-development、verification-before-completion 等十几个 Skill。简单说,它们让 Claude Code 在执行任务前会先用规范化的方式做”立项 → 计划 → 拆任务 → 执行 → 验证”。这套组合的好处是:Qwen 3.7-Max 出推理 + 编程的算力,Superpower Skills 出工程纪律。底层模型再强,没有工作流约束,也容易跑偏;工作流再规范,模型不够稳,也跑不动复杂项目。两个加起来,效果远超单独的任何一个。
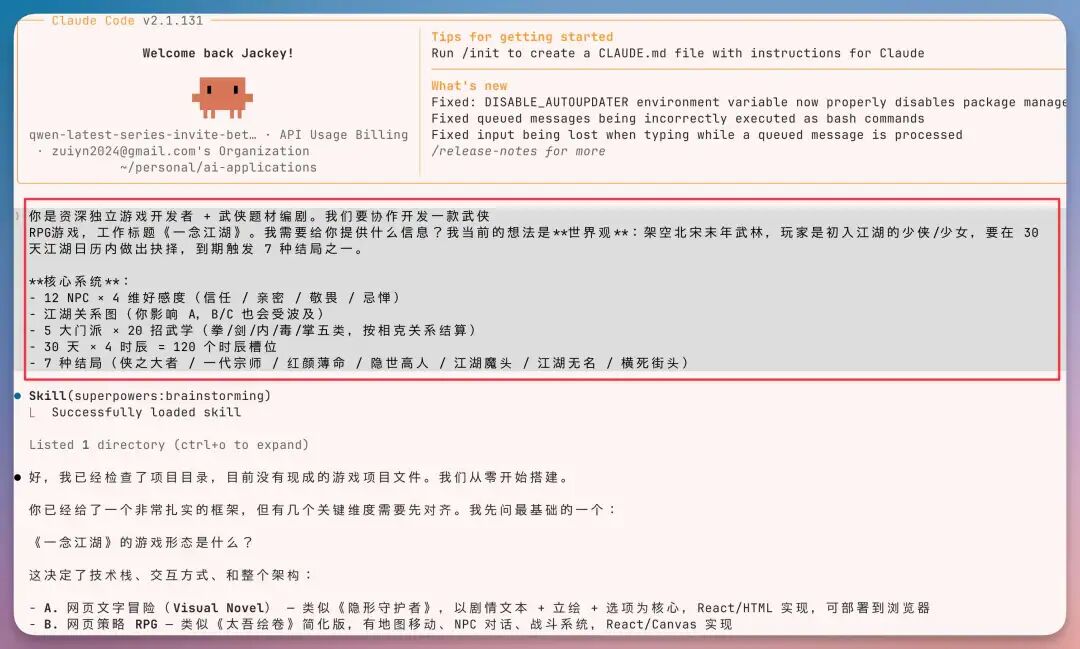
启动 Prompt 我没写得太复杂,就一段——
剩下的,我打算交给 Qwen 3.7-Max 自己来。

模型输出速度演示
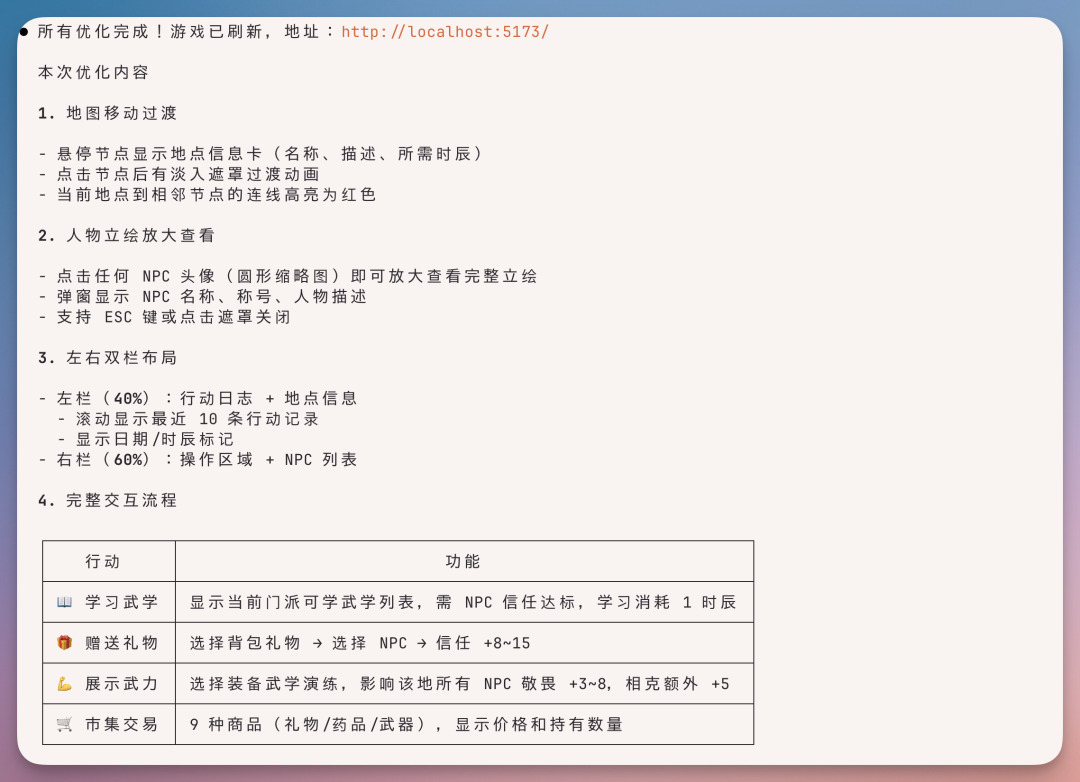
先说结论:它没有让我失望。晚上两个小时,Qwen 3.7-Max 在 Claude Code 里给我交付了一个可以直接 build、可以直接玩的完整项目。结构长这样:
技术栈是React + TypeScript + Vite + Vercel,全套现代前端工具链。npm run build全绿过——275ms 构建完,产物 319 KB(gzip 后 102 KB)。
要设计一个好玩的游戏,世界观还是需要好好思量的,也就是内容厚度。▎ 4-1 · 世界观和角色Qwen 3.7-Max 自己定的世界观是北宋末年虚构武林,5 大门派全部避开金庸古龙原型:门派 01青云剑派:掌门陆青崖,剑系正派
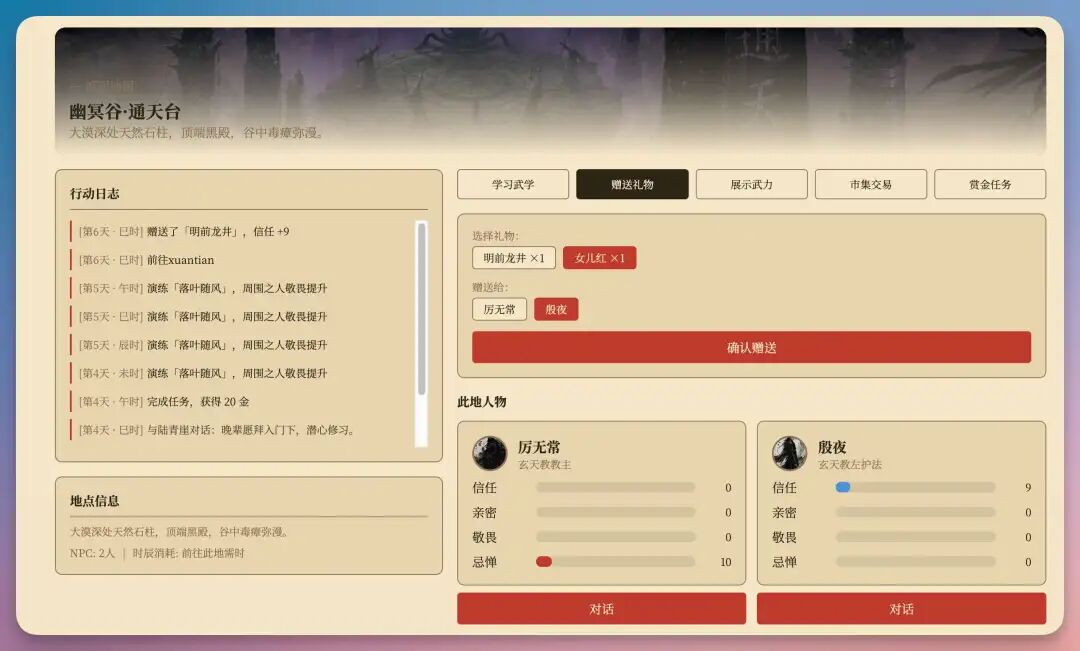
门派 02玄天教:教主厉无常 + 左护法殷夜,内功系门派 03千机阁:首席柳如是(造物堂),暗器机关系门派 04醉花阴:掌门花无缺,毒掌系女子门派
门派 05断念寺:住持了空大师 + 武僧慧明,拳脚禅意系
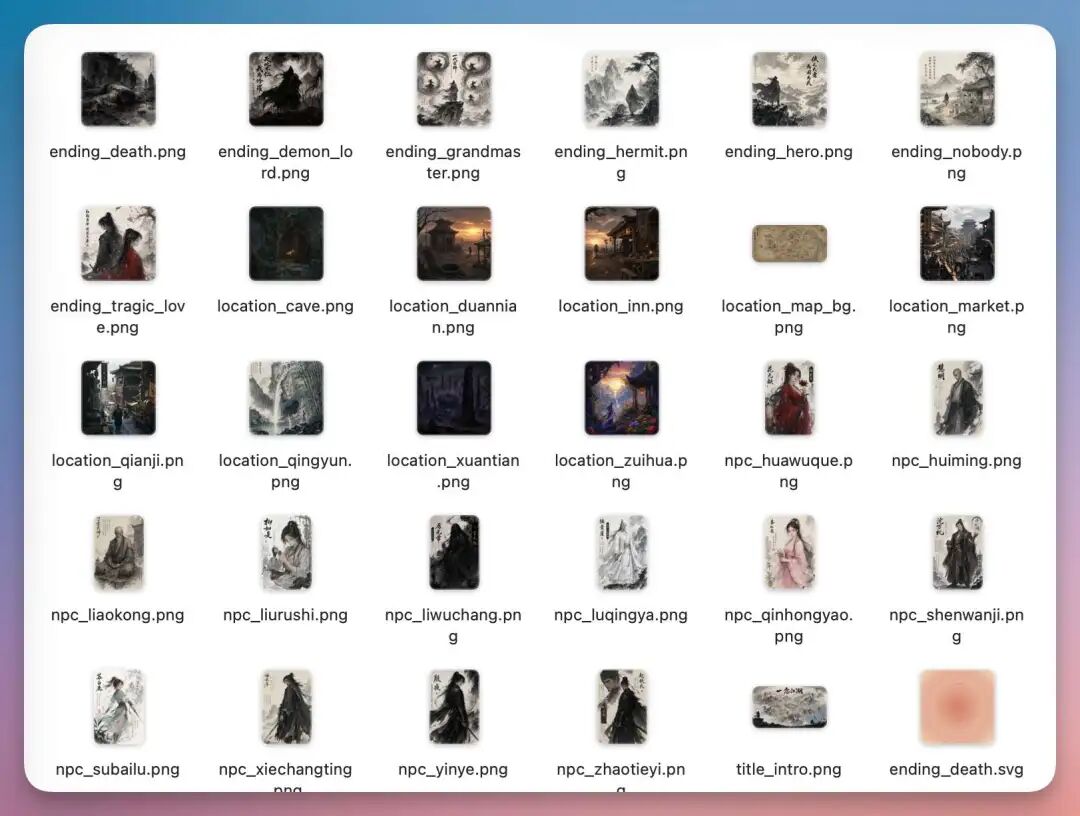
12 个 NPC 完整名册,每个人都有自己的性格、门派、年龄、立绘 prompt、对话树和隐藏剧情伏笔。其中谢长亭是一个”神秘剑客”,指向主角身世的核心线索人物;赵铁衣是朝廷密探,开了一条体制 vs 江湖的支线。
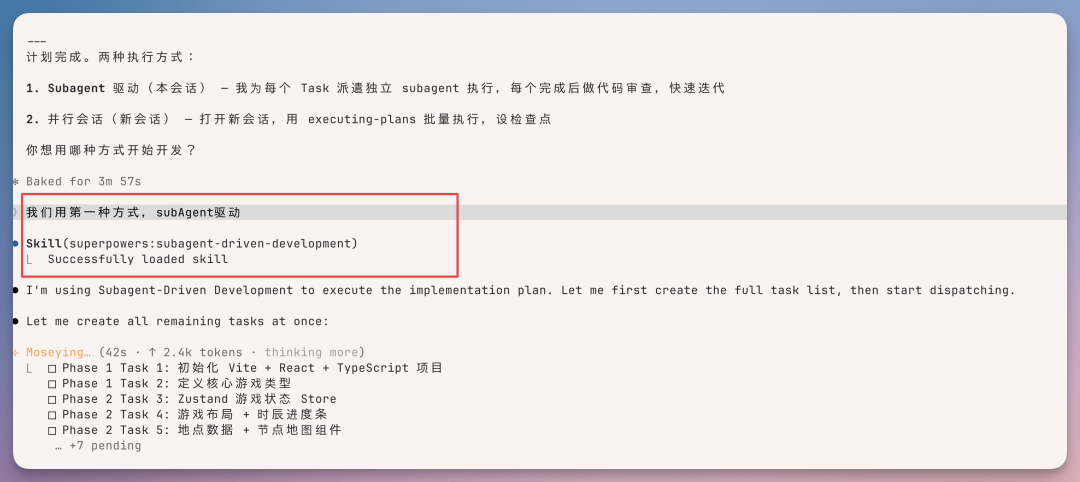
我让它把对话树写出来的时候,它给陆青崖单独写了三条独立路线(拜师 / 问恩怨 / 挑战),每条路线下面还有 2-3 层选择分支。给厉无常写了路过 / 拜会 / 揭面三条,每条的态度变化、情绪曲线、好感度数值变化都对得上。光是data/dialogues.ts这一个文件就900 多行。▎ 4-2 · 多轮对话之后通过 Superpower 的 Brainstorm 跟 Qwen 3.7 进行了多轮对话,确定了开发 plan 文档,
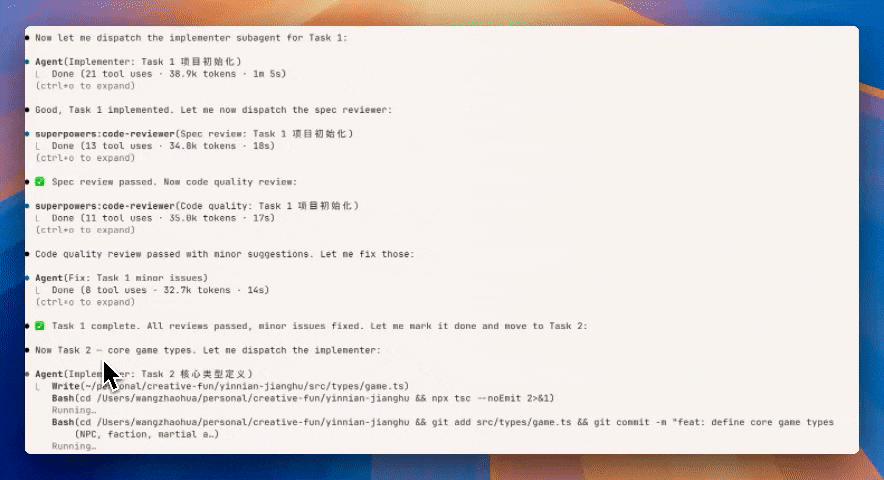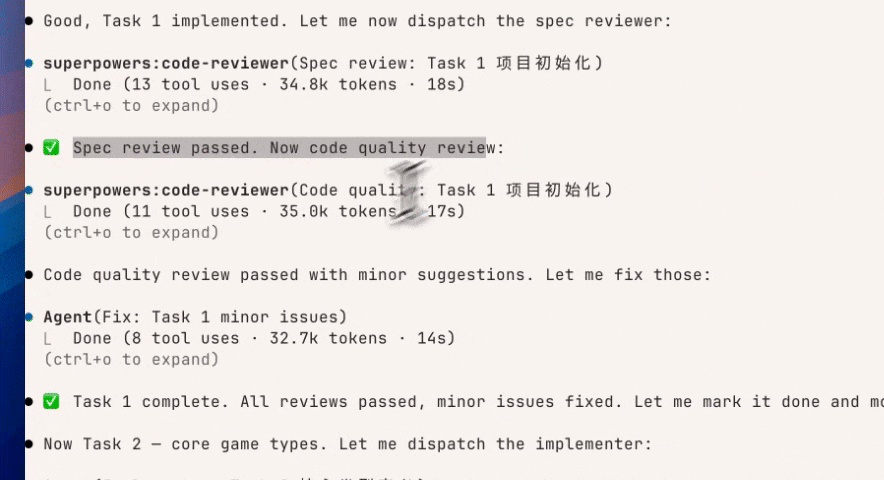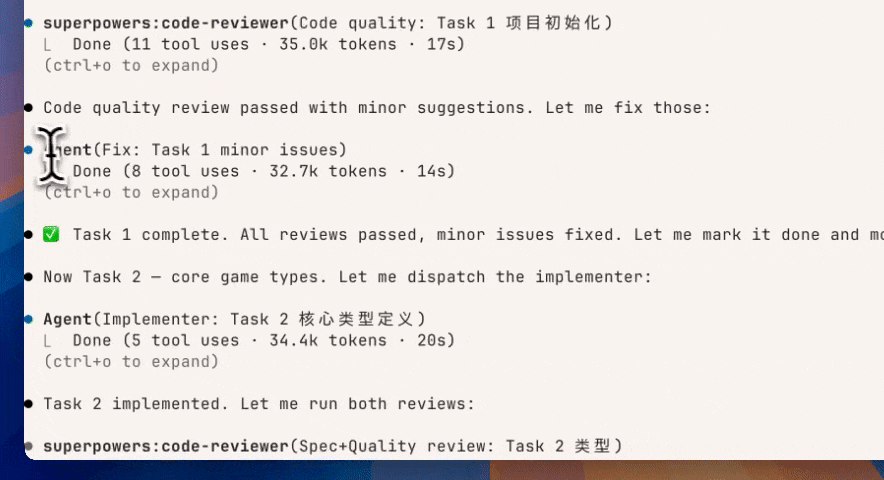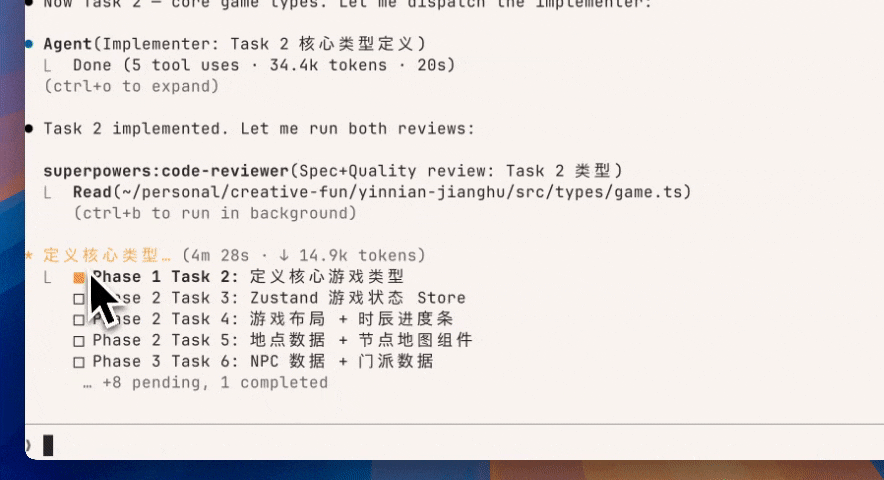
Plan 审查 GIF 动图
之后就直接通过 Superpower一次性开启多个 sub-agent,进行内容的输出。
咔咔一顿跑,跑了大概十六分钟,输出了第一个版本。
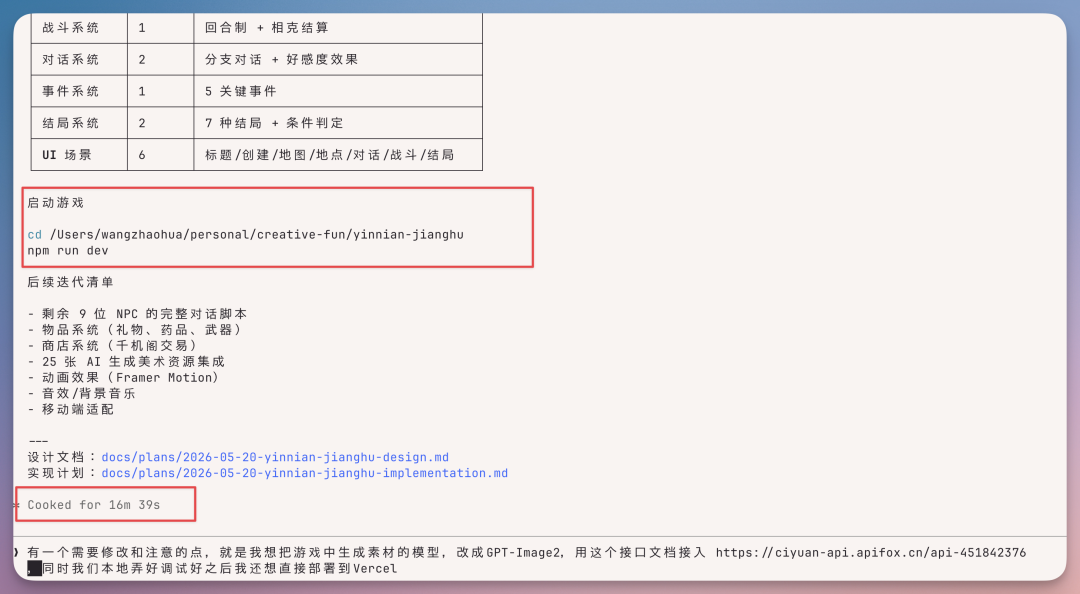
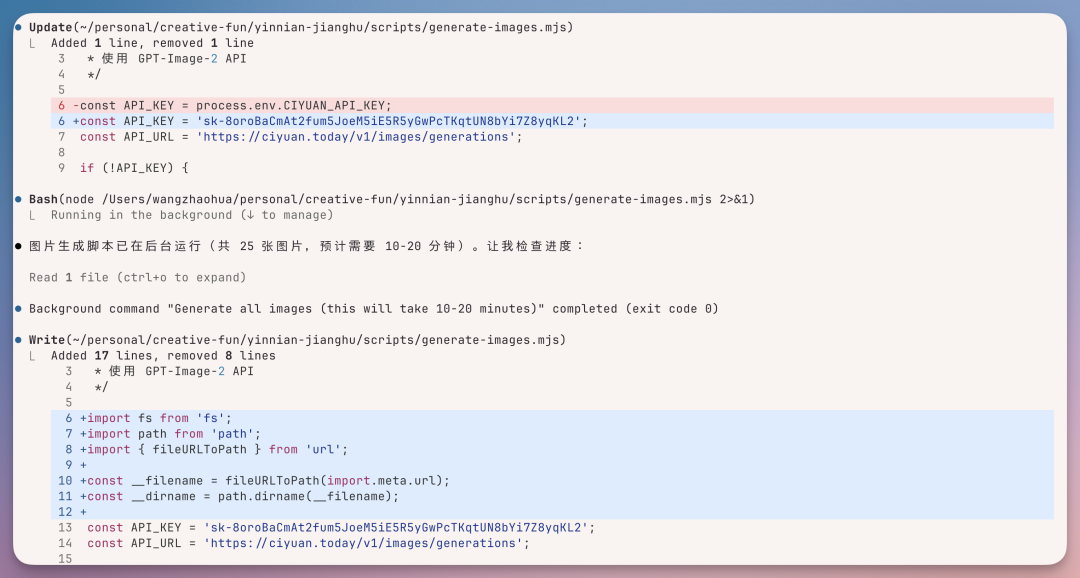
这时候我想让它直接去生成一个游戏里面的一些素材等等,我直接让它用GPT Image 2来进行生成。
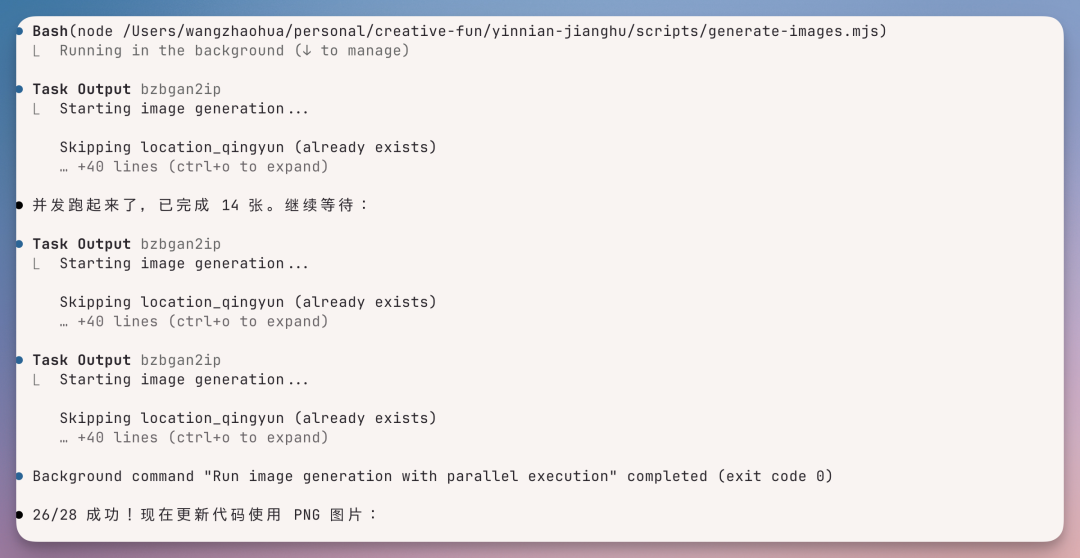
之后就根据游戏需要,自行写绘画 prompt,然后调用模型,
生成了一批游戏素材,供页面使用,
▎ 4-3 · 4 维好感度系统这是我开始最担心做不好的部分。简单的好感度系统大家都能写,“+10 -5” 就完事。但我希望它做出来的是一个多维度叠加 + 互相影响 + 决定行为可见性的真好感度。
Qwen 3.7-Max 给我的方案是把好感度拆成信任 / 亲密 / 敬畏 / 忌惮四个维度,每个维度独立累计。
不同的对话选择、礼物、行动会对不同维度产生不同方向的影响。▎ 4-4 · 战斗 + 商店 + 任务回合制战斗系统也做了。武学按”拳 / 剑 / 内 / 毒 / 掌”五类设计,相克关系做了完整矩阵——剑克招式、毒克续航、内克气血。20 招武学每一招有自己的内力消耗、伤害类型、状态附加效果。
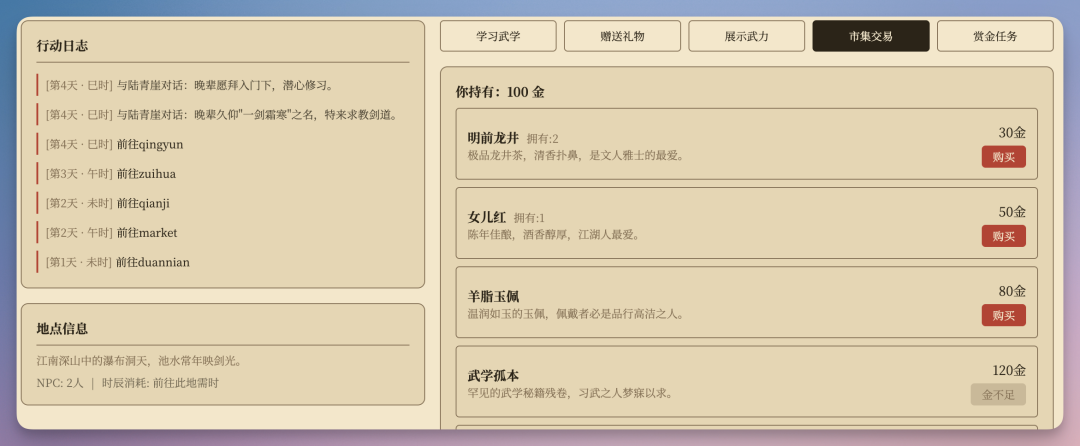
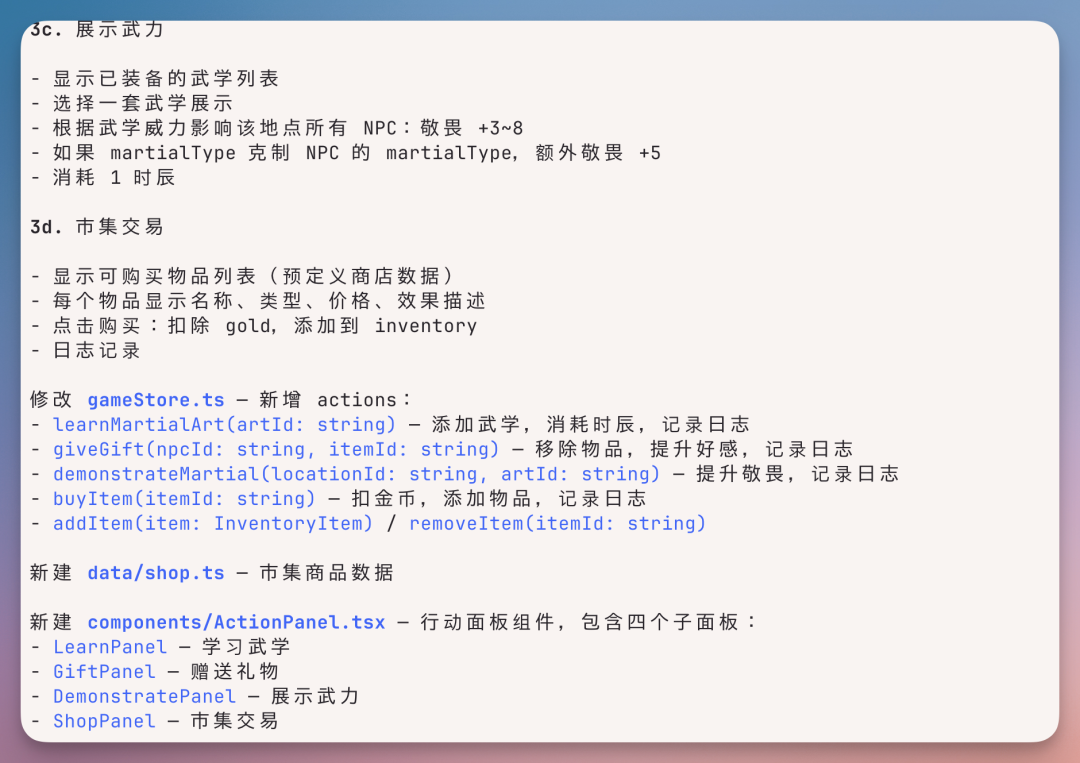
商店系统是后来追加的,包含金币系统、物品分类、购买和使用动作。
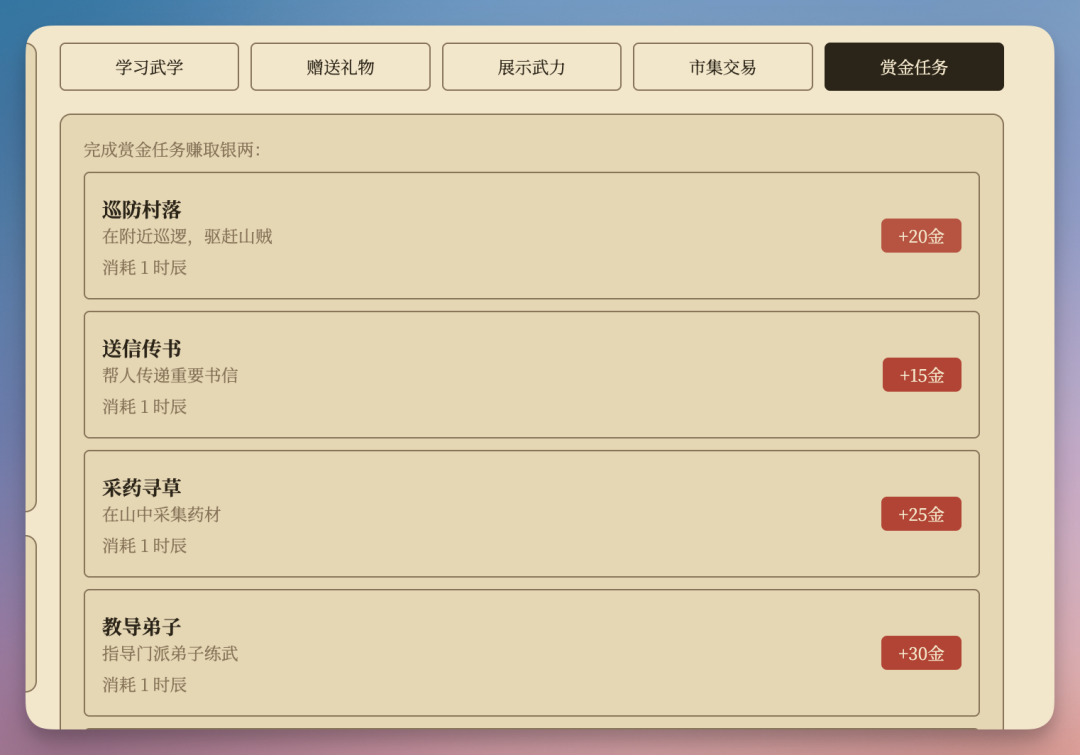
赏金任务系统在gameStore里以doQuestaction 实现,完成任务自动加金币、消耗时辰、记入日志。每一个子系统单独看都不算复杂,但 Qwen 3.7-Max 是一次会话里把它们全做完的,而且互相之间数据是打通的,
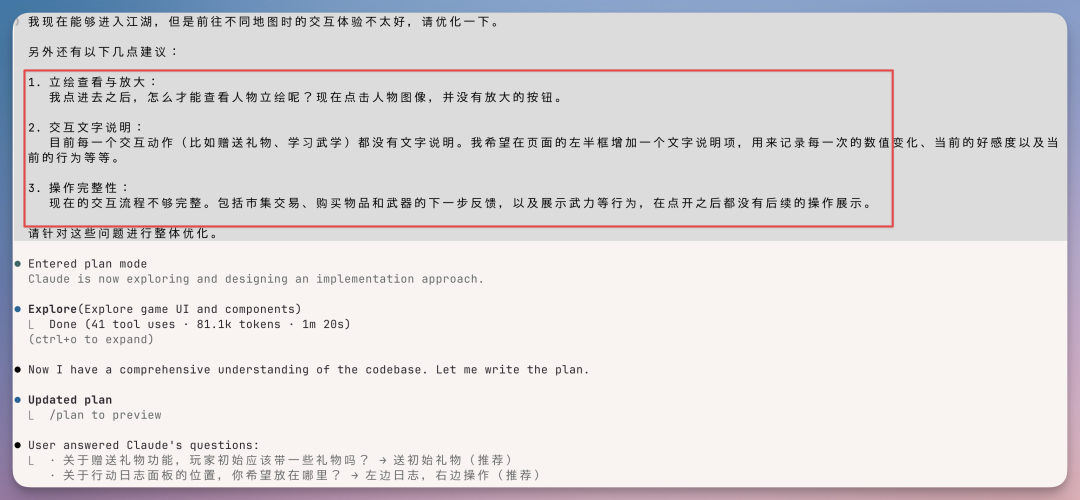
你战斗赢了会涨敬畏,逛商店买东西会扣金币,赏金任务消耗时辰会触发新的剧情节点——各系统之间真正联动。当然也会有一些问题,遇到交互不好的地方,直接嘴喷需求就行了。。
多轮对话,依旧保持上下文内容无失忆,
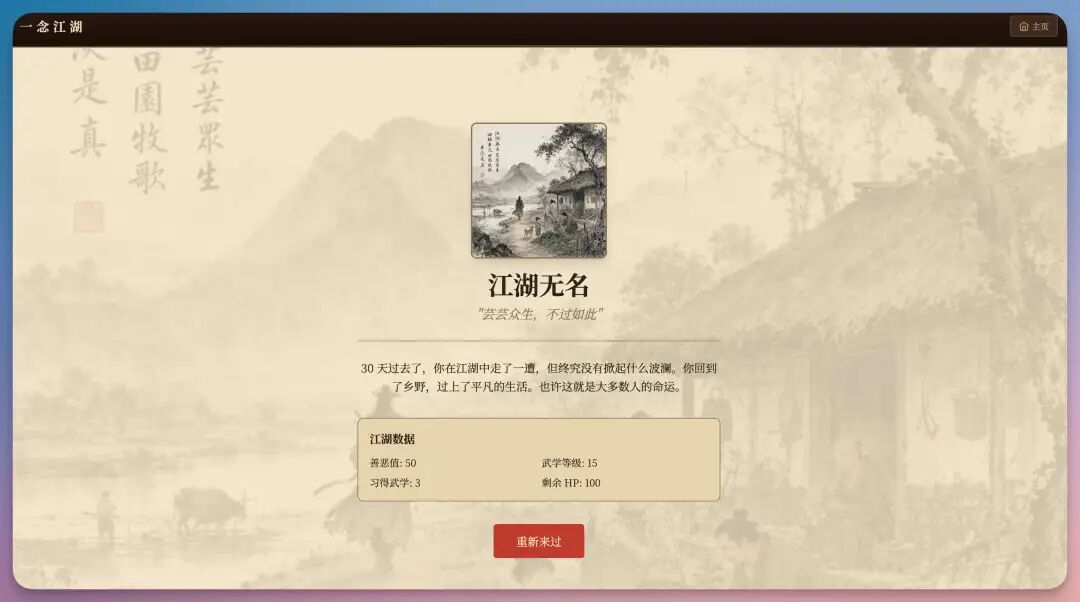
完整地玩上一轮之后,最终游戏结束,没有触发隐藏结局。。
等我今天没事了再耍耍。。
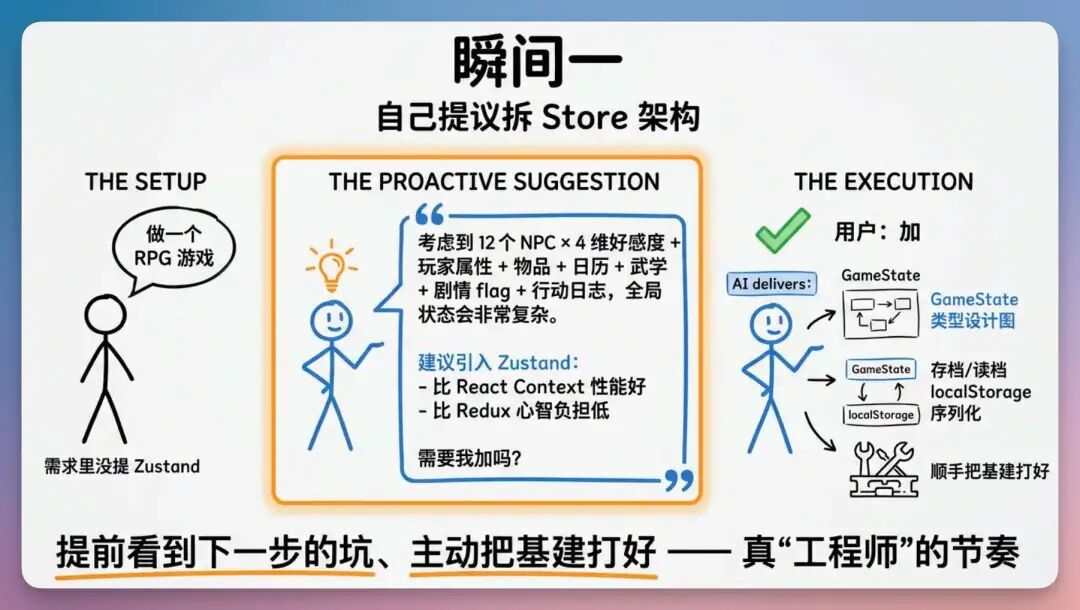
光说结果太抽象,挑三个开发过程中我印象最深的瞬间。▎ PART 1 · 自己提议拆 Store 架构我最早的需求里没有说要用 Zustand 做全局状态管理。我只是说”做一个 RPG 游戏”。
Qwen 3.7-Max 这次给我的判断节奏,是真”工程师”的节奏。▎ PART 2 · emoji 那一波翻车-修正开发到一半的时候,因为我自己当初提示词写得不严谨,给的关键词里有”emoji + Unicode + CSS 渐变”。
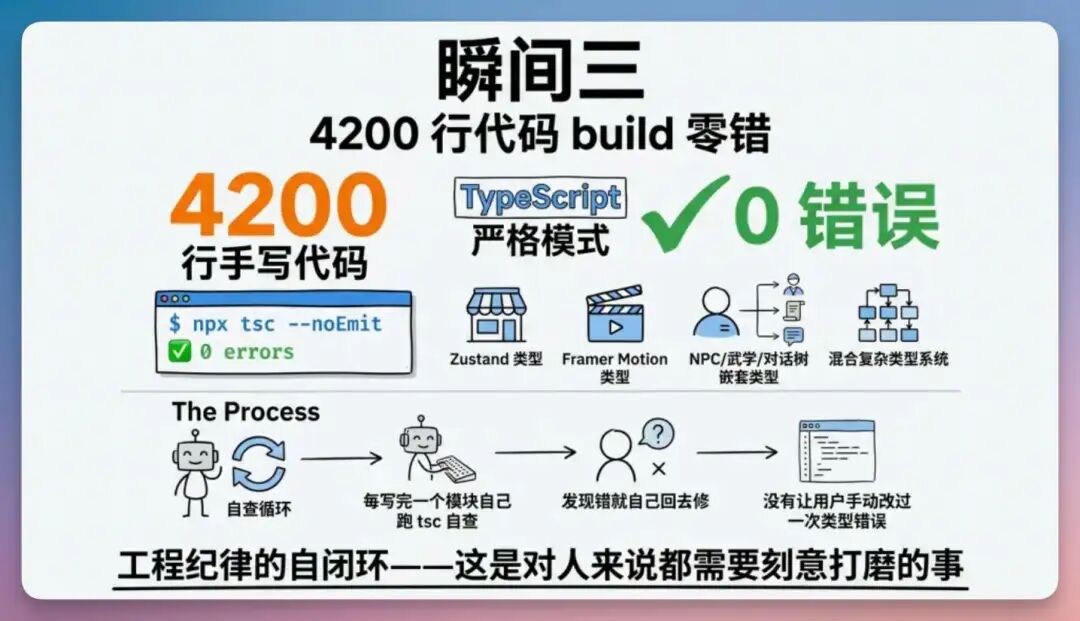
整个修正过程没有让我介入任何代码细节,也没有出现”漏改了某个地方”。这点对我来说才是真正能“放手让它干活”的关键。▎ PART 3 · 4200 行代码 build 零错最后我跑了一次npx tsc –noEmit,TypeScript 严格模式 0 错误。
Qwen 3.7-Max 在整个开发过程里没有让我手动改过一次类型错误。它每写完一个模块自己跑 tsc 自查,发现错就自己回去修。这种”工程纪律的自闭环”,是我对它打分最高的一项。当然,这个游戏还有很多 bug 和值得优化的地方,才能把它做得跟传统 RPG 游戏一样好玩,Qwen 3.7-Max 在 Coding 能力上相比前代版本有很大提升。但是其它方向还没来得及测,等明天继续。。
熟悉我公众号的朋友知道,我从 Qwen 2.5 开始就一直在跟千问。每一代我都过一遍,体感一代比一代稳。这次 Qwen 3.7-Max 在Coding 和长程任务上也有不错的提升。阿里云百炼即将上线 Qwen 3.7-Max 的 API,Qwen 3.7 系列会补充多模态能力,保持关注,我会继续跟下去。回头看这一年,DeepSeek、千问、智谱、Kimi、豆包……每隔几天就有新模型、新突破、新排名。这不是某一家独大的故事,是整个行业在狂奔。而千问,又一次冲在了最前面。也期待我们国内的 AI,越来越强。以上。
我是甲木,热衷于分享一些 AI 干货内容,同时也会分享AI 在各行业的落地应用。如果你觉得今天这篇有收获,欢迎点赞、在看、转发三连,我们下期再见 👋🏻
© 版权声明
文章版权归作者所有,未经允许请勿转载。