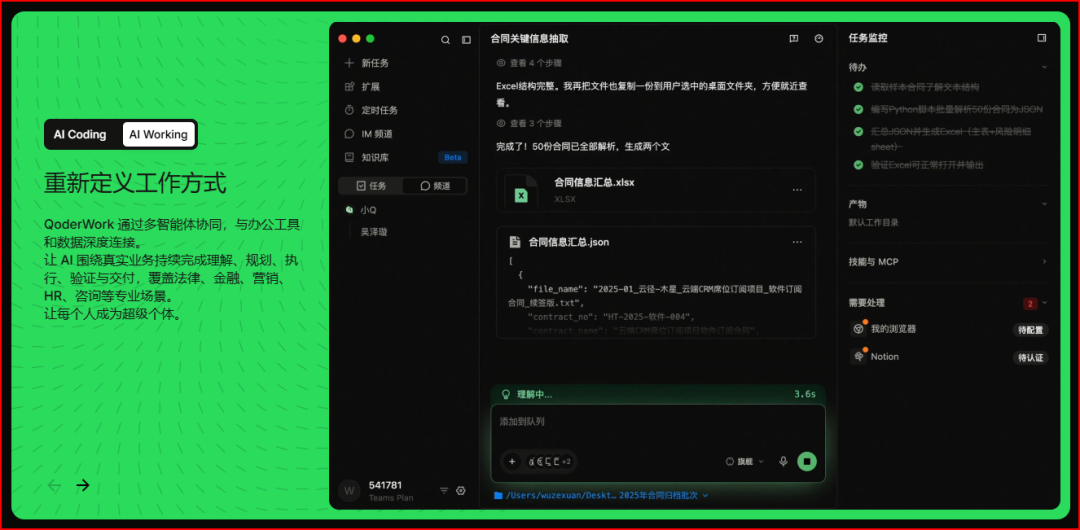
看到技术报告后我就只想说三四五六个字,真齐活了,啥都不缺了。今年模型发布太多了,我对又一个更强模型其实已经有点麻了,赢的指标太多了,每个月都充Token Plan的我更关心的是,它有没有把Agent高频用到的几大能力都凑齐,从纸面能力上看,M3在SWE-Bench Pro(软件工程)拿到59.0,超过了GPT-5.5和Gemini 3.1 Pro,接近Opus 4.7;在GPT5.5擅长的终端编程上,跟Opus 4.7同分。在多模态测试集OmniDocBench上,得分超了Gemini 3.1 Pro;在自主Agent的端到端评测框架Claw-Eval上拿到最高分。感觉就像是张无忌,拿着乾坤大挪移在对手最厉害的招数上打败TA。

说实话,GPT5.5 400k的上下文我忍很久了,放到Hermes里不够用啊,Claude就别说了,看到我Agent里不是Claude Code的系统提示语之后第一时间就ban我了。用的时间越久越觉得有点像个不可能三角一样,写代码强但上下文短,进到代码库里,改几轮就开始忘前文了。上下文长但代码力不够,结果就是读了很久文件然后给我一个丑不垃圾的网页

拜托,真的不要再让我看到这种雷霆大丑网页了好吗。那接下来就是传统环节了,把MiniMax M3放哪个框架来测试呢?我这里整合了一张表,我出于想试试看Claude Code新能力Dynamic Workflows,一口气开几百个subagent的壮观之感就单方面选这个了。

额外补充一下,M3在MiniMax Code里面是可以调用Minimax全家桶API的,文字、语音、视频分析都有。大家如果跟我一样经常换模型测试的话,可以用cc switch来切换模型。直接先来复刻一把,这次MiniMax放出来的主case本来是把ICLR 2025 Outstanding Paper Award论文丢给M3,让它独立复现。技术报告里面给到的数据是,M3自主运行接近12小时,产出了18次commit和23张实验图表,并跑通了核心实验。离谱的是,M3的多模态能力已经可以做到把论文里的公式,曲线图、实验设定放到同一个长线程里处理。我第一时间想到的跟这个类似的就是Karpathy大神三个月前把他的nanoGPT升级成了nanochat,这是一套完整的大模型训练实验框架,覆盖了所有主要阶段,包括分词,预训练,微调,评估,推理和聊天 UI,只花48刀就把模型训练到了GPT-2水平。

我今天就让MiniMax m3用动态工作流在我这台mabookpro训练一个GPT出来,触发动态工作流的方式主要有两种,最简单的方式就是带上workflow这个词,词会变成一个彩虹的配色,系统识别到之后就会生成一个脚本,在执行之前会给我们预览,确定后再启动多Agent的并行。在运行的过程中,随时可以用/workflow指令或者直接用/config 指令关掉这个动态工作流。

如果都想要MiniMax M3的额度打满,也可以输入/effort 选择ultracode,然后按shift+tab切换到auto mode自动模式,后面基本上都全自动多Agent了。之前用Claude sonnet 4.6的时候都没敢切换成ultracode,现在用MiniMax m3顶上之后这大紫色是真好看啊。确认之后,对话框还会短暂地变换成全彩虹色,非常有仪式感,所以这就是氪金玩家的愉悦之感嘛。

真正跑起来的时候反而是有点唏嘘了,大家都知道我是个算法程序员,几年前运行个比GPT小40倍LSTM(循环神经网络),从数据准备到模型训练,然后等训练曲线出来再到模型推理,再快也要个三五天,最崩溃的就是跑一半发现包的版本不对,模型智力倒退五十年,现在一个Agent就可以在90分钟把所有活干完了。

接着又训练了1000步之后,这个模型就从一个我咋问都只会回答A的版本变成开始有逻辑的回复,还能算个乘法,简单做问答的版本了。

大模型训练,很神奇吧!现在你也可以做到了。

很多模型最容易挂在前30次的尝试里,跑几轮不行,就开始绕圈,摆烂,不然就是来个万金油话术建议我手动检查。但真实工程里,很多进展就是出现在这种平台期后面。你试了很多次都没提升,然后突然某个方向打穿了。如果一个Agent没有足够长的上下文,没有稳定的工具调用,它根本走不到后期。
第二个case我来给正在开发2.0版本的Humanize PPT加加速,Humanize PPT的出发点是给HTML PPT加一个人话大纲和演讲模式,也就是在生成之前先把所有的资料整理一遍,缺失的细节会进一步补全,确定要用多少页,每页都是什么内容才能把我们想讲的内容讲明白。至于演讲模式一看就清楚了,有下一页的预览,演讲主题,大小进度条,口播稿,想要脱稿的也可以看关键点。
样式的部分本着不重复造轮子的想法,我兼容了中文的guizang-ppt-skill和英文的frontend-slides,用它们来生成HTML PPT的页面,Humanize PPT完成其他部分。为了保证设计出来的中英文HTML PPT都好看,我之前要Claude Code辅助设计,Codex来做资料整合和大纲生成的,这个对于模型的多模态能力还是要求很高的。每一页PPT我都需要模型先用浏览器自动化打开HTML PPT的当前页,然后来个截图让模型去判断动态背景有没有生效,字体有没有大小不一致啥的,跟上一页的视觉元素有没有不同。

但是GPT5.5偷懒得很严重,就算我给它开启了超高的推理模式,在前几次运行的时候,它还是只给我做了一个临时的兼容处理,就算我明确跟它说了,我们的定位是原生兼容这个 HTML PPT,完全可以以自然语言的方式去批量生成。

能看得出来我都有点破防了,甚至想自己上手去改代码了。刚好现在就把这这条做到一半链路全交给MiniMax M3出个计划试试看。

又花了一小时,重新梳理了一遍解决了GPT偷懒留下来的历史代码,Humanize PPT现在可以在对话中调用子Agent,一次性生成guizang-ppt-skill里所有主题了。









看了一下,是因为M3还有一个新架构MSA,能把每个token的计算量压到上一代的1/20,也就说一百万 token 的上下文窗口,预填充(模型在正式回答之前,先把你发给它的内容理解一遍)快9倍,解码(模型个字一个字把答案写出来的过程)快15倍。最后的最后,到了经典价格环节,M3上线之后,Token Plan从固定时间刷新额度变成了固定token。Plus 6 亿 token 49 元/月 ,Max 18 亿 token 119 元/月 ,Ultra 55 亿 token 469 元/月。不得不说,百万上下文+动态工作流带来的体感太不一样了,富足到连开发完后做个最小测试,M3都给我模拟了七种场景,我打算就把M3当做动态工作流的专属模型了,直接先来个一个月的Ultra试试看耐不耐用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。