
搭的过程中有一个很深的感受:Agent 好不好使,不取决于模型多聪明,而是底层数据能支持到什么程度。说白了,数据库的主要用户,正在从程序员变成 Agent。这不是一个小变化。正好前几天腾讯云开了一场「数据库+AI」产品发布会,我全程听完,腾讯云副总裁王义成把这个趋势拆得明明白白。他说数据库走过了三个时代:1.0 时代承接互联网洪峰,腾讯云数据库撑住了亿级弹幕、单日 50 亿次查询,核心关键词是高并发、高可用。2.0 时代搞国产自主可控,腾讯云自研的 TDSQL 拿下了某行核心系统,迁移后读性能提升 35%、写性能提升 80%,日交易峰值 19.6 亿笔,扛住了金融级考验。每一次跃迁,都是因为「用户变了」。而现在,3.0 时代来了。新用户是 Agent。Agent 要记住上下文、沉淀经验、跨任务复用知识,还得代替人做开发测试和运维巡检。这些能力的底座,无一例外指向数据库。但传统数据库给 AI 用,处处别扭。数据散落在 MySQL、MongoDB、COS 三套系统里,Agent 光找数据就要花掉 80% 的时间。Vibe Coding 背后是百万级长尾环境,按月付费的实例根本扛不住。RAG 上亿条向量直接吃光内存。所以腾讯云这次发布会,甩出了一套完整的四层架构,从记忆、数据底座、开发范式到智能运维,逐层解决 Agent 时代的痛点。我结合自己搭 Agent 的实战体感,帮大家逐层拆解。Agent Memory:给 Agent 装上记忆这是我体感最强的一层。搭那个营销 Agent 的时候,我输入「CodexGuide 发布」,Agent 自己扒信息、做分析、出图。第一次出的暗色系我说不行,它自己调整重新来。
但真正让我觉得有东西的,是跨轮次的连续性。有次我忘了项目进度随口问了一句,它直接从记忆库里把之前的对话和决策全捞出来了。按场景聚类,带上下文召回,几个工作流互不串台。
聊着聊着,它还顺手记下我的偏好,下次直接按我习惯来。

这背后就是腾讯云 Agent Memory 的三层核心能力。第一层,短期记忆压缩。Agent 跑长任务会产生大量上下文,传统做法是全塞给模型,Token 线性飙升,任务跑到一半就崩了。Agent Memory 用符号化压缩 + 上下文卸载,长任务成功率提升 30%,Token 消耗节省 30%-60%。我实际跑下来体感很明显,任务完成率上去了,消耗反而降了。

第二层,长期记忆沉淀。Agent 要真正理解业务,就得记住用户偏好、业务规则、历史决策。Agent Memory 用四层渐进式记忆提取,在 PersonaMem 测评数据集上把 OpenClaw 原生记忆评分从 48% 拉到了 76%。更关键的是,成功任务还能自动提取成 Skill,让每次经验可被复用。
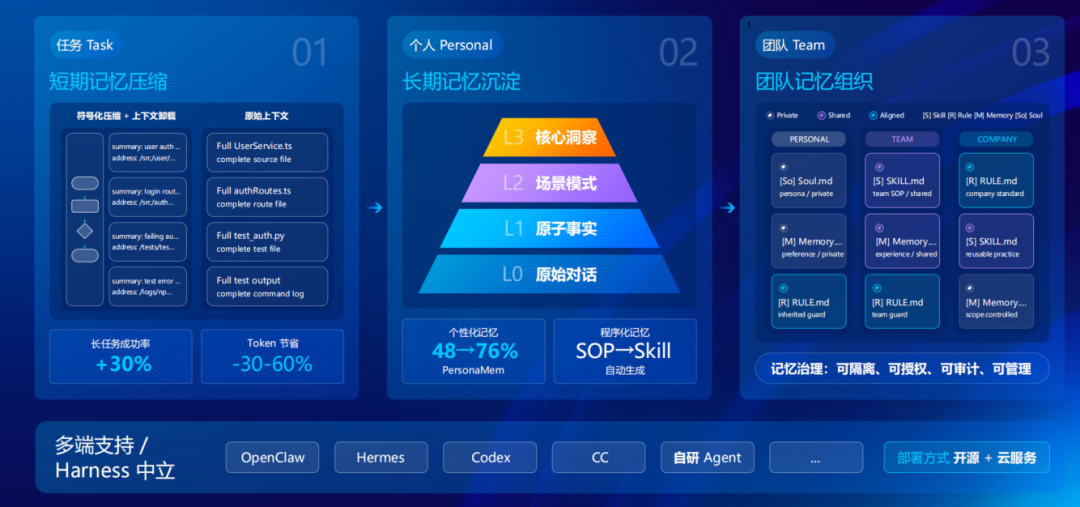
第三层,团队记忆组织化。这层说实话有点超出我预期。如果每个 Agent 只保留自己的记忆,就没法形成稳定协作。Agent Memory 把分散在对话、任务、文档中的团队上下文组织起来,形成可被多个 Agent 复用的共享记忆层,还有隔离、授权、审计的完整治理能力。这是 AI 从个人工具走向组织系统必须补上的基础设施。还有个细节让我印象很深。我中途换了一次模型,对 Agent 搭建一点影响都没有。传统做法下换模型等于换脑子,但 Agent Memory 把记忆和模型解耦了。换壳不换脑,体验连续。

记忆不是模型的附属品,而是独立的基础设施。这是我搭完之后最深的体会。TDSQL Boundless:Agent 的多模数据中枢光有记忆还不够。Agent 跑起来之后,数据散落是下一个瓶颈。王义成在发布会上举了一个很形象的例子:今天企业的数据现状就像章鱼一样,结构化数据在 MySQL,半结构化在 MongoDB,大文件在对象存储。Agent 想拿一份完整新鲜的数据,要穿三套系统、三套延迟、三套一致性协议。结果就是 Agent 80% 的时间在找数据,20% 留给用数据。散、乱、慢。TDSQL Boundless 的解法是把关系型事务、向量语义检索、全文搜索统一到一套分布式架构上。Agent 不用再在多套异构存储之间跳转,一个连接、一条查询,语义召回 + 关键词搜索 + SQL 分析一起搞定。

发布会上重点讲了三个支柱能力,我觉得很有料。多模融合,一键纳管 MySQL、PG、Mongo、Redis、ES、COS,异构数据源开箱即接。基于 CDC 的实时同步链路让数据新鲜度从天级压到秒级。文本、图片、音视频库内跨模态对齐。多模计算,一次查询调动四种智能:向量搜索十亿级毫秒响应、全文检索关键词精排、图计算跨源关系推理、标量分析传统 SQL 零迁移。单一数据库做不到的事,Boundless 一条查询搞定。库内推理,这个最让我眼前一亮。一行 SQL 调大模型,数据写入即自动向量化,告别 ETL 流水线。检索结果还能二次精排,召回质量提升 30% 以上。算力下沉到数据,而不是数据上浮到算力。这是 Boundless 和所有「外挂式 AI」方案的本质区别。如果说 Agent Memory 是智能体的工作记忆,那 Boundless 就是企业的长期知识中枢。用户画像、行业知识库、Agent 调度日志、多模态素材索引、交易流水,全在这一层统一纳管、统一检索。TDSQL-C:为 AI 开发重塑底座第三层讲的是开发范式问题。讲真的,这层跟我们开发者关系最密切。现在用 CodeBuddy 写代码,用 Cursor 搞 Vibe Coding,Agent 以人类无法比拟的速度写代码、跑测试、做协同。但传统数据库给这种场景用,怎么说呢,笨重。TDSQL-C 这次做了三个关键升级。Serverless,匹配 AI「长尾稀疏 + 突发峰谷」负载。开库秒级、闲置归零、冷启动毫秒响应。Agent 一天调几次也好,活动突然峰值翻百倍也好,按需付费亚秒级扩缩。说白了,工程师喝咖啡的时候不收费。自动 Branch,为 AI 实验与回滚而生。1TB 库克隆从小时级变秒级,时间点回放从备份恢复变快照毫秒级,主库零干扰。Agent 跑流水线每次都能拿到一份和线上一样真又完全隔离的沙箱,像用 Git 管理数据。AI Toolkit,亿级向量零损召回、列存实时分析提速 10 倍、向量检索内存降 75%。RAG、长期记忆、实时洞察,开发者不用东拼西凑,一库直达。

但发布会上让我最意外的,是底层的AI Native Storage。直接把云原生数据库存储底座推翻重来了。王义成在台上讲得很透:前面那些 Serverless、Branch、AI Toolkit,传统存储底座根本撑不起来。闲时归零依赖极致弹性,秒级克隆依赖快照分叉,混合负载依赖一份数据多种引擎,只能从存储层根上重构。他把存储架构的演进拆成了三代:第一代传统云硬盘,主从各挂一块盘,计算存储绑死,弹性代价大。第二代共享存储,存算分离了,但三副本强同步有木桶效应,必须等全部副本确认才返回,延迟容易被放大。第三代 AI Native Storage,做了三件大事:重写日志系统,LogStore 独立做 Redo 持久化,写入读取路径彻底解耦。引入多数派写入协议,3AZ 全对等架构,任意 2/3 副本确认即返回,IO 稳定 50ms 以内,告别木桶效应。原生行列混存,每个 AZ 同时部署行存和列存 PageStore,TP/AP 不再需要两套库两条链路。

一份数据、两种引擎、一次部署。TCO 较同类产品下降 200%+,IO 零抖动,3AZ 金融级强同步 RPO=0。这才是真正为 AI 时代准备好的云原生底座。DatabaseClaw:让数据库自己变聪明前三层讲的都是数据库怎么服务 AI。第四层反过来,AI 怎么让数据库自己变得更智能。王义成提了一个很现实的问题:云原生让数据库实例数量指数级上升,但资深 DBA 培养周期长、成本高,人力只能线性增长。这个剪刀差,靠堆人走不下去了。DatabaseClaw 的定位是对话即运维。一句自然语言,就能完成过去需要在多个控制台跳转、串联指标、翻文档才能解决的事。

它有三个让我印象深刻的点。专家级诊断能力。内置腾讯云十万级真实 DBA 工单沉淀的排障经验,把顶尖 DBA 的 SOP 变成可复用的 Skill。不是通用大模型能搞定的,这是真正「懂数据库」的专家 Agent。全产品覆盖。一个 Agent 管 14 款数据库产品、1600+ OpenAPI,关系型、NoSQL、SaaS 一网打尽。生产级安全。四层安全护城河:权限隔离、AI 行为护栏、架构安全、全链路审计,配合 L1-L4 细粒度操作分权。AI 真的能进生产环境。除了 DatabaseClaw,这次还发布了两个 AI 赋能数据库的能力:预测式弹性。用 DNN、LSTM、Transformer 等算法对流量做时序预测,高峰来临前自动扩好资源,过后小步缩容。全程零抖动、零感知。混元优化器大模型。SQL 优化器是数据库里门槛最高的模块,传统优化器靠规则和成本估算,遇到复杂负载就掉进局部最优。混元大模型探索全计划空间,自动验证候选计划,跨实例复用最优方案。结果也很硬:慢 SQL 平均时延降了 60% 多,探索效率提升 20 倍以上。让 DBA 从救火队员变成架构师,让数据库自己解决数据库的问题。写在最后四层能力串起来看,就是腾讯云数据库在 AI 时代的完整产品主张:

上面两层,数据库服务 AI,让 Agent 跑得好。Agent Memory 给记忆,Boundless 给数据中枢,TDSQL-C 给开发底座。下面一层,AI 服务数据库,让数据库自己变聪明。DatabaseClaw 做自治运维,混元优化器搞性能自愈,预测式弹性解决资源调度。三者叠加在全栈自研底座之上,这就是数据库 3.0 时代的样子。说实话看完整场发布会,我最大的感受是这句话:没有记忆的 AI,只是工具。有记忆的 AI,才是资产。Agent 帮你把经验沉下来,人才能腾出手来专注创造。而数据库,正是让 Agent 拥有记忆、拥有知识、拥有智能的那块基石。数据库 3.0 时代真的来了。你觉得你的工作流里,Agent 最缺的是哪一层能力?评论区聊聊。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


