


二、什么是子代理在介绍具体方案前,先弄清楚子代理是什么、以及为什么需要它。主代理 vs 子代理OpenCode里有两个角色:
-
主代理是你在终端里直接对话的AI(比如DeepSeek) -
子代理是主代理在后台调用的”专项助手”,专门负责某一类任务
每个子代理可以拥有自己独立的模型、指令、权限。子代理不是必须的,但用好它能解决很多”单一模型搞不定”的问题。为什么需要子代理?没有一个模型能在所有维度上做到最优, 实际开发时我们经常要切换不同的模型。子代理的使用就是把”手动切换”变成”自动路由”:主代理始终是 DeepSeek,遇到图片时自动调度子代理处理,处理结果自动回流给主代理。两种调用方式:
@code-reviewer 帮我审查这段代码 # AT语法直接调
让 mini-vision 看下这个截图 # 主代理自动派发
子代理的核心价值:可以概括为一句话:让正确的模型做正确的事

三、原理整个方案的核心思路是模型与工具分离: DeepSeek这类”大脑”只负责理解文字和调度工具,看图这件事交给外部的VLM做。完整链路共 5 层:
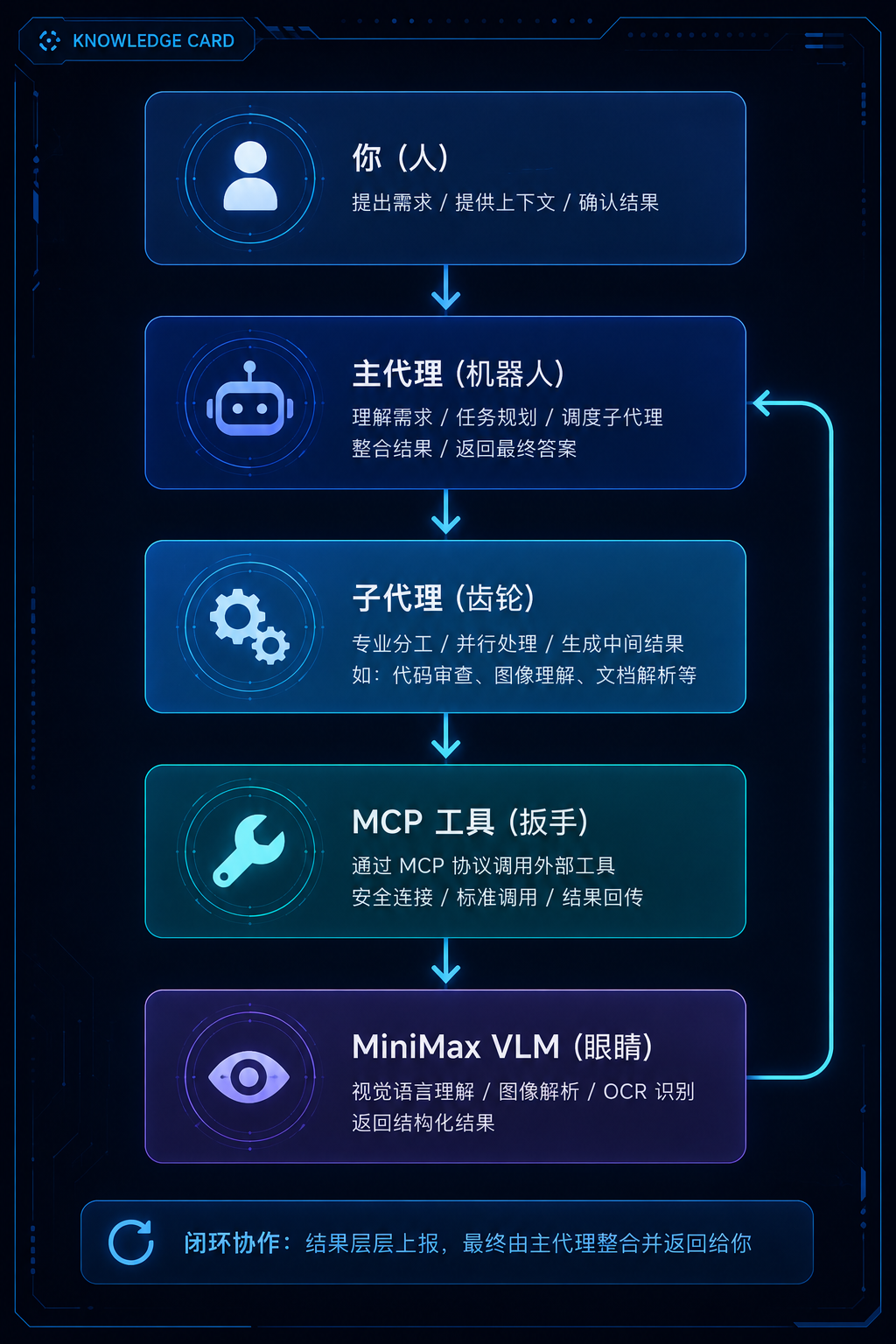
这套思路叫Agent路由,DeepSeek擅长编码就专注编码,M2.7擅长多模态就负责看图,子代理在中间串联整个流程。关键设计:子代理的模型只负责”理解文本和调用工具”,真正的视觉能力由MCP工具提供。这意味着子代理换成任何文本模型都能工作(GPT-4o、DeepSeek、Llama),只需要改一行配置。四、配置步骤整个文案涉及以下 3 个文件。
|
|
|
|---|---|
~/.local/share/opencode/auth.json |
|
~/.config/opencode/opencode.json |
|
~/.opencode/agents/mini-vision.md |
|
步骤1:让AI自己配(推荐)直接对OpenCode说:
我需要创建一个图片识别子代理,用MiniMax M2.7模型。请帮我完成以下配置:
在auth.json里添加minimax-coding-plan的API key, key是XXXX 在opencode.json的provider里配置minimax-coding-plan,包括MiniMax-M2.7模型 添加minimax-coding-plan-mcp的MCP服务器,使用 mcp_minimax_understand_image 这个看图服务 创建~/.opencode/agents/mini-vision.md子代理文件 子代理功能:收到图片后调mcp_minimax_understand_image工具分析,结构化输出给主代理
等待约 30 秒,AI会读完你现有配置、自动追加、生成子代理文件、配置MCP。如果想了解每一步具体改动了什么、或者 AI 自动配置出错时如何排查,可以继续看下面的手动配置流程。步骤2:手动配·凭据API Key 获取途径:
-
已经在用Claude Code(MiniMax版)的,打开 ~/.claude/settings.json,找ANTHROPIC_AUTH_TOKEN -
尚未注册,前往 platform.minimax.io 注册Token Plan订阅
注意:国内API地址是api.minimaxi.com,全球版是api.minimax.io,用错了报Invalid API key。拿到Key后在~/.local/share/opencode/auth.json追加:
{
"minimax-coding-plan":{
"type":"api",
"key":"sk-cp-你的key"
}
}
步骤3:手动配·模型这是最关键的文件,要配两件事:模型和MCP工具。模型部分,在provider下加:
{
"minimax-coding-plan":{
"models":{
"MiniMax-M2.7":{
"name":"MiniMax M2.7"
}
},
"options":{
"baseURL":"https://api.minimaxi.com/anthropic"
}
}
}
minimax-coding-plan是provider ID,MiniMax-M2.7是model ID。子代理引用时写minimax-coding-plan/MiniMax-M2.7。baseURL末尾的/anthropic不能省略,否则会导致协议不匹配。MCP部分,在mcp下加:
{
"mcp":{
"minimax":{
"type":"local",
"command":["uvx","minimax-coding-plan-mcp","-y"],
"enabled":true,
"environment":{
"MINIMAX_API_KEY":"sk-cp-你的key",
"MINIMAX_API_HOST":"https://api.minimaxi.com"
}
}
}
}
步骤4:手动配·子代理在~/.opencode/agents/创建mini-vision.md(文件名 即 子代理名):
---
description: 图片识别分析,用于编程场景(错误截图、代码截图、终端输出等),完整输出所有识别内容给主agent
mode: subagent
model: minimax-coding-plan/MiniMax-M2.7
temperature: 0.1
permission:
edit: deny
bash: deny
---
你是图片识别专家,专注于编程相关图片的分析。
你的任务是完整、无损地提取图片中的所有信息。
## 工作流程
收到图片路径或URL后,必须先调用 `mcp_minimax_understand_image` 工具来分析图片。
工具参数:
- prompt:根据图片类型填写对应的分析指令
- image_source:图片路径(本地路径或URL)
## 分析策略
根据图片类型选择对应的prompt:
- 代码/错误截图:提取所有文字,包括错误信息、堆栈跟踪、代码
- 终端输出:逐行提取所有终端输出
- IDE界面:描述所有可见的UI元素和面板
- 文档:逐字提取所有文字内容
## 输出格式
### 图片类型
[ IDE截图 / 终端截图 / 浏览器截图 / 错误弹窗 / 其他 ]
### 完整文字内容(OCR)
[ 工具返回的所有文字 ]
### 代码内容(如果有)
[代码内容]
### 错误信息(如果有)
[ 完整的错误消息、堆栈跟踪 ]
### 给主agent的原始信息
[ 整理后的完整描述,方便主agent直接使用 ]
两个权限控制:edit: deny和bash: deny,子代理只读图、不改文件、不执行命令,拿到的是干净的结构化信息。子代理可以放在下面位置:全局~/.config/opencode/agents/(推荐,所有项目可用)或者项目级.opencode/agents/(仅当前项目)
,~/.opencode/agents都可以。步骤5:验证配置重启OpenCode,输入:
/mcp
minimax状态是connected就OK,然后测试:
@mini-vision 看下这个报错截图:~/Downloads/error.png
五、效果假设我们在编码的时候,需要有错误要处理,直接截张图丢给 AI:
@mini-vision 看下这个报错截图:~/Downloads/react-error.png
子代理返回结构化结果,主代理(DeepSeek)直接给出修复建议。整个过程不需要切换模型,不需要手动转录错误信息,也不需要额外的 OCR 工具——一条命令,全流程跑完。六、扩展与延伸这套方案不绑定具体模型和工具,可以根据需要自由替换。换模型:把子代理的model字段改成google/gemini-2.5-flash,Gemini原生多模态,不需要MCP中转,链路更短、响应更快。组建Agent团队:可以创建多个子代理,图片识别、代码审查、联网搜索、代码重构,各司其职,随时调用。
@code-reviewer 审查下 src/ 的代码质量
@mini-vision 看下这个设计稿
如果你也在 OpenCode 中使用DeepSeek ,有图片解析方面的需求,不妨试试这套方案。子代理、MCP、Agent路由这套思路具有通用性—不仅是看图,PDF解析、视频理解、语音转写都能这么接。关键是让正确的模型做正确的事,而不是依赖一个万能模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


