
如果想要充分发挥大模型的潜力,懂一些RAG的基本原理还是非常关键的。今年智能体Agent爆火,RAG技术同样是当前Agent增强记忆能力的关键技术。
让大模型学会做笔记
理解一个东西还是要从本质去理解,首先肯定要看看RAG全称是啥对吧。别来一个人问你RAG全称,你却支支吾吾的说不出来,那显然是不懂RAG啊。
RAG全称就是Retrieval Augmented Generation,检索增强生成嘛。很简单,就字面意思,用检索得到的知识来增强生成的效果。增强啥效果呢?增强大语言模型的生成效果。
为啥RAG就能增强效果了,其实就是因为大模型生成时会有个致命问题——幻觉。幻觉就是捏造事实。
当你问为啥要有RAG时,其实就像是在问我为啥我要天天做笔记呢?假如你没看我这篇文章,别人问你RAG是啥,你是不是瞎说一通?你说你是不是也有“幻觉”问题。
这时你把我这篇文章看了然后写到笔记里,下次别人问你RAG时检索出笔记对着念,自然就解决了幻觉问题。那么大模型也是一样,没看到文章时就会乱说一通,假如用某种方法将文章存到笔记里,然后让大模型回答问题前把笔记检索出来参考,那不就解决幻觉问题了。
讲完了RAG的基本定义,接下来就可以看看RAG到底是怎么实现的了。
RAG的核心步骤
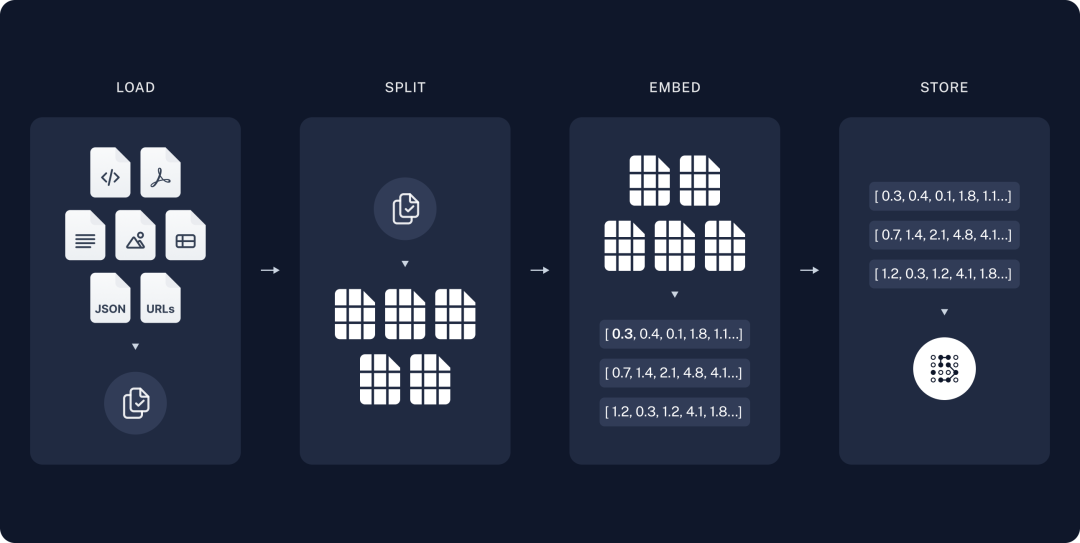
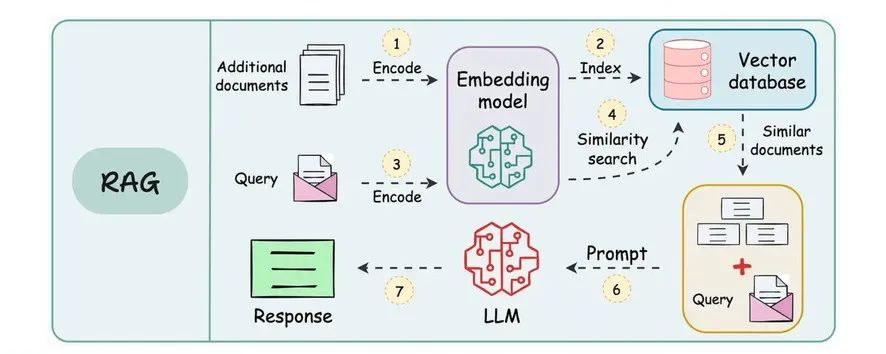
按照上面的思路,RAG首先是得存笔记对吧。所以第一步我们得把文本信息存到一个地方,而在技术上我们采用向量数据库(Vector DataBase),最终笔记都会存到向量数据库里。
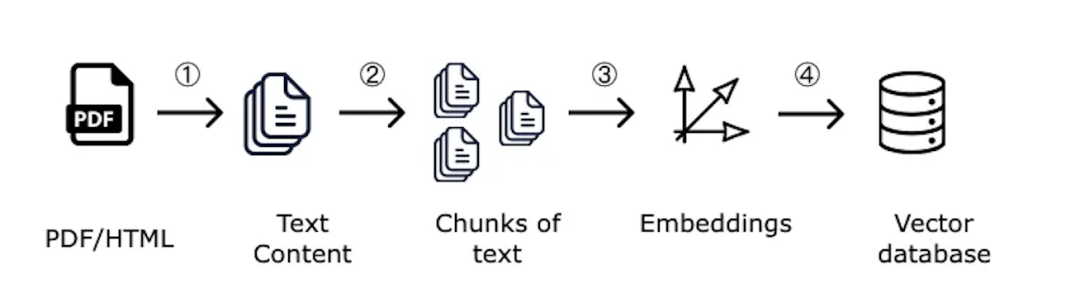
1、文本分块
由于文本信息可能很多,比如一本书这么大,肯定没法直接存一整本书,所以首先需要把书拆成一页一页甚至是一段一段的小块(Chunk)。而且分块还有其他好处:模型有长度限制:一次肯定不能检索出一本书作为参考资料,别说模型吃不消了,人也不可能每次回答问题前先看完一本书。找重点的效率高:每次查东西时其实重点只在那几句话里,而不是整本书的信息都有用。通过分块的方式,最终检索出来的就是有用的几块重点内容。
2、生成向量并存储
分块后,需要将每一块的文本信息通过向量模型(Embedding model)转化为文本向量(Embedding),然后将这些向量存到向量数据库里。
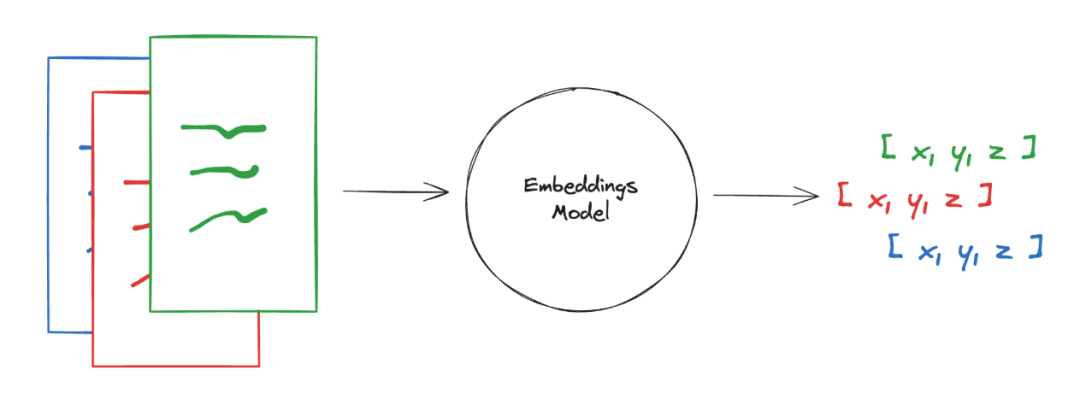
向量就是将文字转化为计算机能理解的数字,通过算法将文字映射为数字数组。其实你可以理解为就是计算机读书的方式。
我们记笔记是通过文字的方式,大模型记笔记是通过向量的方式。我们把文字写到纸上,大模型把向量写到向量数据库里。
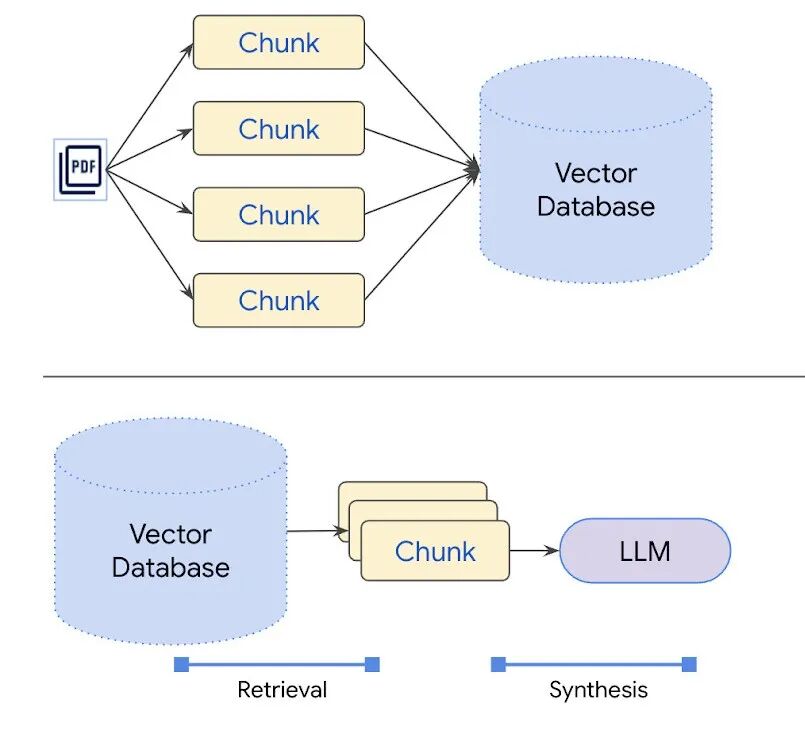
3、用户查询并向量化
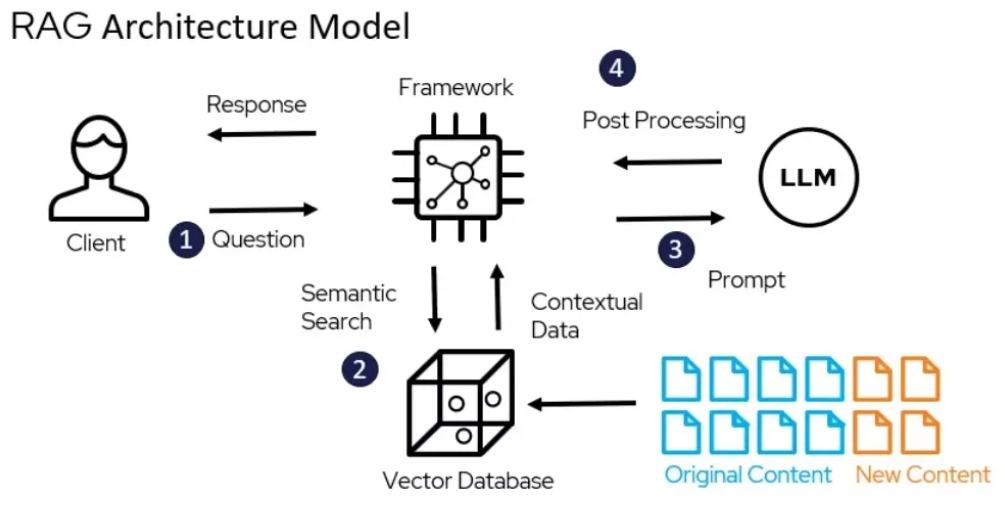
大模型读完书了,也记完笔记了,它就学到知识了、变强了!接下来就到了用户提问的时候了,看看它怎么通过向量数据库应对人类的提问。
首先其实大模型是不理解用户打出的文字的,所以它需要将用户提问也转化为计算机能够理解的数字向量。和前面的文字转向量的方法一样,通过向量模型生成向量。
得到问题(Query)向量后,从向量数据库(Vector DB)里检索出与当前问题最相关的分块。通常是选出K个最相关的块,由人工设置K的值。其实就是人类根据问题从笔记里检索出最相关的几句笔记,到底选几句笔记呢,那就根据你以前的经验了。
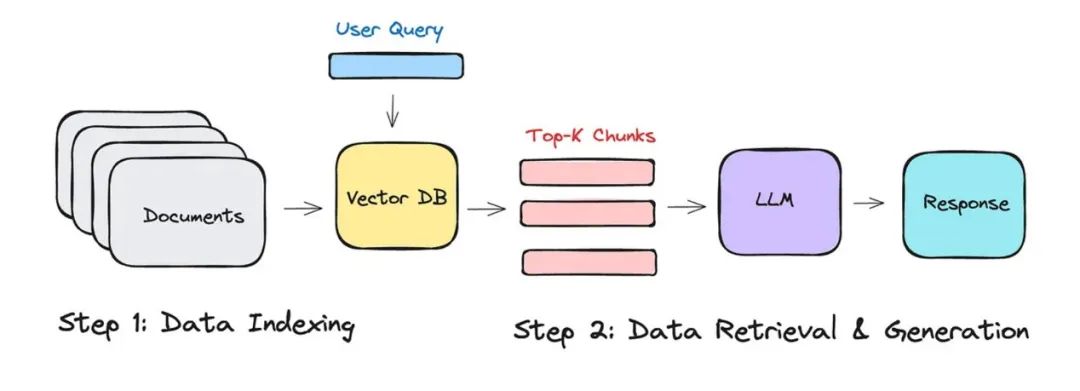
4、重排序分块
本来选完笔记后,就可以回答问题了。但是向量数据库选笔记的技术目前一般般,选出的几个分块很可能不是与问题最相关的分块。所以这里很多情况下会使用更聪明的模型来对选出的K个分块打分排序一下,然后再重新选出打完分后分数最高的几个分块。
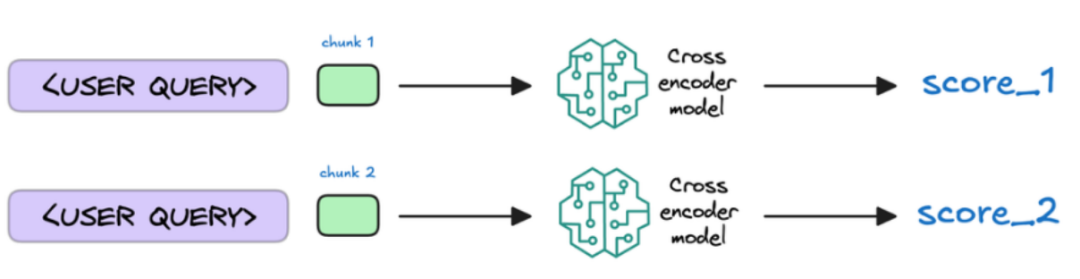
5、生成回答
最后,用户问题有了,相关笔记也有了,直接全塞给大模型进行推理就行了。通过用户问题和笔记,组装好一个Prompt生成结果就行了。
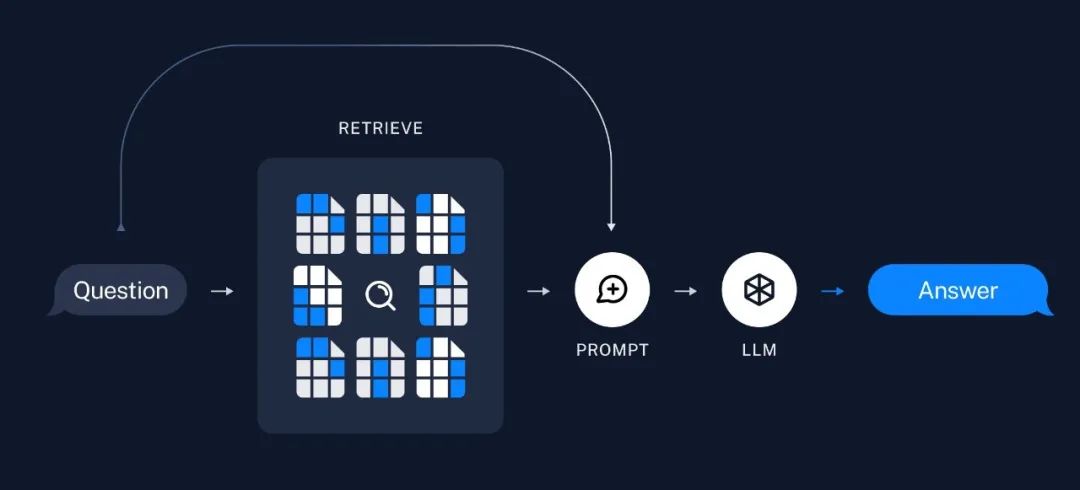
所以最终结果其实还是得看生成大模型有多强。菜鸟有了学霸笔记也没法考上清华啊对吧。
结语
看完以上的介绍,有没有觉得更加清晰RAG到底是啥了。以后别人再问你,拍着胸脯说“这题我熟!”。
不过以上讲的也就RAG的基础理解和用法,后续我还会考虑写写RAG的优化方法或实践,可以关注下我。如果感兴趣的话,可以评论区互动呀,看看大家最想看啥。
往期文章
高考结束后,夸克Agent赛博“张雪峰”10分钟帮你报志愿苹果公司拿4个游戏搞崩o3/DeepSeek,宣称“你这思考太假了”MCP和A2A尚在“幼儿园”。AI时代反而更需要学编程别再纠结“Agent”概念了,来看看怎么做出更好的Agent吧
❝🌟 都看到这里了,如果这篇内容对你有启发:① 点赞/在看/分享 支持原创,这对我真的很重要!!!② 点击「关注」🔔 获取每周AI前沿技术深度解析和AI资料大礼包③ 星标公众号⭐ 第一时间获取AI黑科技更新推送
我是关注AI提效与AI智能体的辰星。谢谢你看我的文章,也祝你在AI时代能找到自己真正想要的生活。也可以链接我,领取之前我整理的AI相关的一些学习资源。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


