怎么个事呢?有人这么总结:苹果刚刚当了一回马库斯,否定了所有大模型的推理能力。

而苹果公司的这篇论文认为,所谓的自我反思机制问题很大,当问题复杂度超过一定阈值后,推理能力将完全崩溃。你看这论文标题就像是在说:“你这思考太假了”。

不过其实这论文倒也没咋批评现有模型的能力,而是指出了现有模型的一些缺陷以及希望人们在后面训练模型时能够建立更好的推理机制和评估方法。而且,细读一下论文的结果,你会发现这模型思考和人类还挺像的呢。
所以这论文到底讲了啥呢?
❝论文地址:https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf
论文内容
苹果团队认为现有模型测试的数据集只看结果对不对,但是很可能之前喂给模型训练的数据里面就有类似题目,指不定模型是直接背题的,跟思考没有半毛钱关系。而且,现有评估缺少了对模型思考过程的评估和分析,比如中间步骤是否逻辑正确、是否绕弯子绕太大了。
为了解决这些问题,他们设计了一个可控的实验测试平台,通过打造算法谜题环境来评估LLMs的推理能力。不同以往的测试之处在于,算法谜题的难度可以精确控制,研究者能够观察模型在不同复杂度下的结果变化,比如说每一步的决策是否正确、是否反复试错。
4种算法谜题
4种算法谜题的图长下面这样。
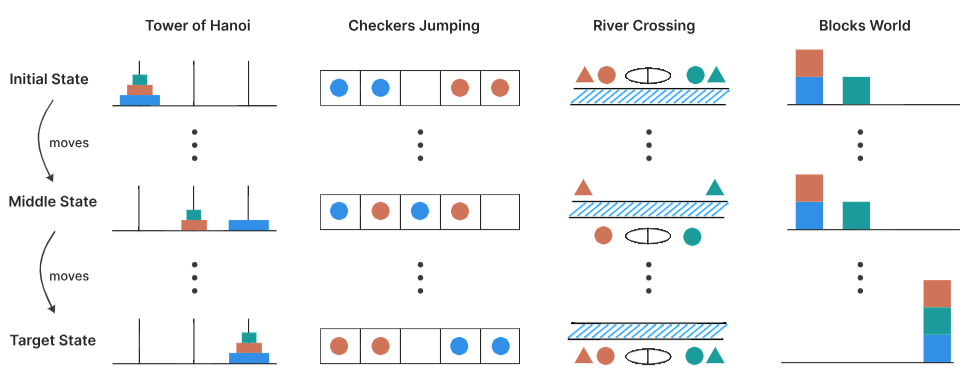
❝汉诺塔(Tower of Hanoi)汉诺塔是一个包含三根柱子和n个不同大小圆盘的谜题,圆盘按大小顺序(最大的在底部)堆叠在第一根柱子上。目标是将所有圆盘从第一根柱子移到第三根柱子。有效移动包括每次只能移动一个圆盘,只能从柱子顶部取圆盘,并且永远不能将较大的圆盘放在较小的圆盘上。
此任务的难度可以通过初始圆盘的数量来控制,n个初始圆盘所需的最少移动次数为2(n)-1。
❝跳棋交换(Checker Jumping)玩法是将红色跳棋、蓝色跳棋和一个空格排成一行。目标是交换所有红色和蓝色跳棋的位置,也就是将初始配置镜像反转。有效移动包括将跳棋移动到相邻的空格中,或跳过恰好一个相反颜色的跳棋落到空格中。过程中,任何跳棋都不能向后移动。
此任务的复杂度可以通过跳棋的数量来控制,对于2n个跳棋,所需的最少移动次数为(n+1)(2)-1。
❝过河问题(River Crossing)该谜题涉及n个角色及其对应的n个代理,他们必须使用一艘船过河。目标是将所有2n个人从左岸运到右岸。船最多可载k个人,且不能空驶。每个代理必须保护自己的客户免受竞争代理的伤害,当一个角色在没有自己代理在场的情况下与另一个代理在一起时,就会出现无效情况。
此任务的复杂度也可以通过调整角色/代理对的数量来控制。对于n=2、n=3对,使用k=2的船容量;对于更多对,使用k=3的船容量。
❝积木世界(Blocks World)该谜题要求将积木从初始配置重新排列为指定的目标配置,目标是找出完成这一转换所需的最少移动次数。其有效移动规则为:仅能移动任意堆叠中的最顶层积木,且可将其放置于空堆叠之上或另一块积木的顶部。任务复杂度可通过积木数量进行调控。
基于这个测试平台,团队进行了大量实验,对比“会思考”和“不思考”的模型。
三类复杂度
-
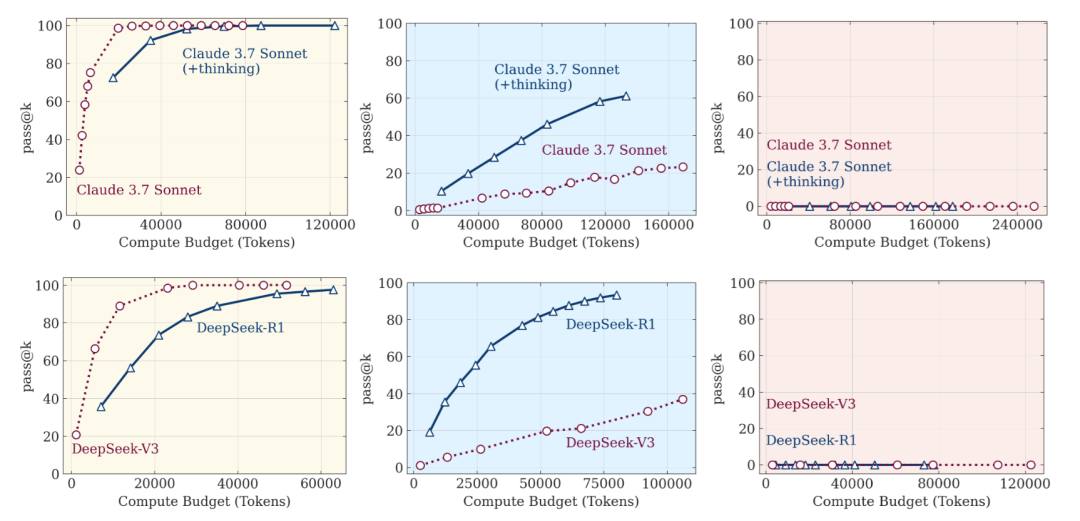
低复杂性任务:没有“思考”功能的标准语言模型实际上表现得更好,不仅更准确而且更加高效,不会浪费计算资源在不必要的思考上。这一发现直接挑战了“更多思考总是更好”的直觉假设。 -
中等复杂性任务:能够生成长思维链的推理模型开始显现优势,额外的思考过程的确能够帮助模型找到更好的解决方案。 -
高复杂性任务:两种模型的性能都完全崩溃。尽管推理模型在一定程度上延迟了性能崩溃,但最终仍无法避免。
为啥会出现这种情况呢?实际上你会发现人类也是这样。
模型与人类的思考模型
苹果团队深入研究了模型的推理过程,发现了导致这些问题的原因。低复杂性任务:在处理简单问题时,推理模型经常会在早期就找到正确的解决方案,但随后却继续探索各种错误的替代方案,“过度思考”浪费计算资源。好家伙,像极了我考试第一印象写对了,结果再思考就会爆炸,直接把正确答案改错了,这确实很心态崩了。
中等复杂性任务:随着问题复杂度增加,这一趋势发生逆转,模型首先探索错误的解决方案,正确解决方案大多出现在思维的后期。你想想以前考试的时候,往往有点难度的大题一般不会出错的。因为中间如果出错了直接没法继续写下去了,自然知道方法是错的,知道错了就会改方法。
高复杂性任务:对于更高复杂度的问题,会出现崩溃现象,即模型无法在思维中生成任何正确的解决方案。这就是菜了,初中生怎么写出来高中压轴题呢?(超前学习的大佬除外)
现有推理模型的局限性
除上面提到的之外,团队还发现了一些莫名其妙的事情。
即使在提供了明确的解决方案算法的情况下,推理模型仍然写不出来。相当于都告诉你解题步骤了,还做不出来,那这思考逻辑可能就真有些问题了。这进一步凸显了推理模型在验证和遵循逻辑步骤解决问题方面的局限性,表明需要进一步研究以理解此类模型的符号操作能力。
不同谜题类型的推理差异:例如,Claude 3.7 Sonnet模型在汉诺塔问题中可以执行多达100步的正确移动,但在过河问题中却只能执行4步正确的移动。有点意思,这模型有点“偏科”啊。这可能表明模型在训练过程中对某些问题类型的接触较少。
结语
说实话,我觉得这篇论文还是有些用的。论文发现了当前思考模型的一些缺陷并呼吁人们注意这些问题,而事实上这些缺陷在人类身上也出现过。那么既然人类可以解决这些问题,模型自然也是可以解决的。
至于这篇论文为啥引发了这么大争议。恐怕是大量不是很懂学术的人看了标题就开喷了,我的感受里苹果确实也在AI上没做出同等咖位的东西。但大家吃瓜还是要理性一些,咱不能完全跟着情绪走对吧。不能因为苹果没干出很牛的AI就觉得论文就没价值,一码归一码嘛。
往期文章
MCP和A2A尚在“幼儿园”。AI时代反而更需要学编程别再纠结“Agent”概念了,来看看怎么做出更好的Agent吧AI神器再现!扣子Coze空间:文字一键变真人对话播客比DeepSeek还炸!国产AI无限生成游戏,你的想象力就是唯一限制
❝🌟 都看到这里了,如果这篇内容对你有启发:① 点赞/在看/分享 支持原创,这对我真的很重要!!!② 点击「关注」🔔 获取每周AI前沿技术深度解析和AI资料大礼包③ 星标公众号⭐ 第一时间获取AI黑科技更新推送
我是关注AI提效与AI智能体的辰星。谢谢你看我的文章,也祝你在AI时代能找到自己真正想要的生活。也可以链接我,领取之前我整理的AI相关的一些学习资源。
© 版权声明
文章版权归作者所有,未经允许请勿转载。