
大家好,我是焦哥。零代码基础手搓工作流,专注于AI智能体工作流的搭建知识分享。
看到那些火爆全网的古诗词视频,不仅孩子们看得目不转睛,连咱们大人都会心一笑,频频点赞。今天,焦哥就来分享一个巧妙的coze工作流搭建方法,自动配上动听的音乐、生动的画面和清晰的字幕,1:1复刻那些古诗词爆款视频。
先看下效果
工作流总览
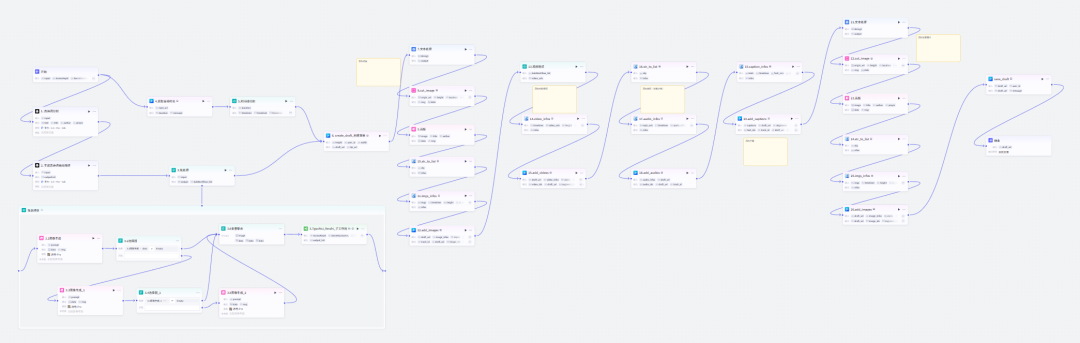
工作流主要分为三部分第1部分:大模型生成的文本、图片、导入的音频素材第2部分:利用即梦AI插件进行的图生视频子工作流第3部分:通过插件把图片、视频、音频、字幕添加到视频中
工作流节点第一部分
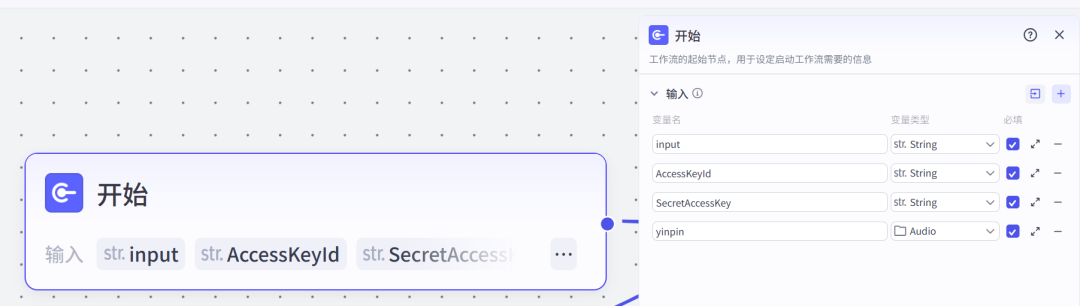
开始节点input:输入一首古诗词的全文。AccessKeyId与SecretAccessKey:这两个是秘钥,即梦插件需要,下一步我们需要准备好。yinpin:上传一段古诗词音频,因为扣子现阶段生成不了真人的咏唱音频(我称为天籁之音),所以我们需要提前从网络上下载准备好。
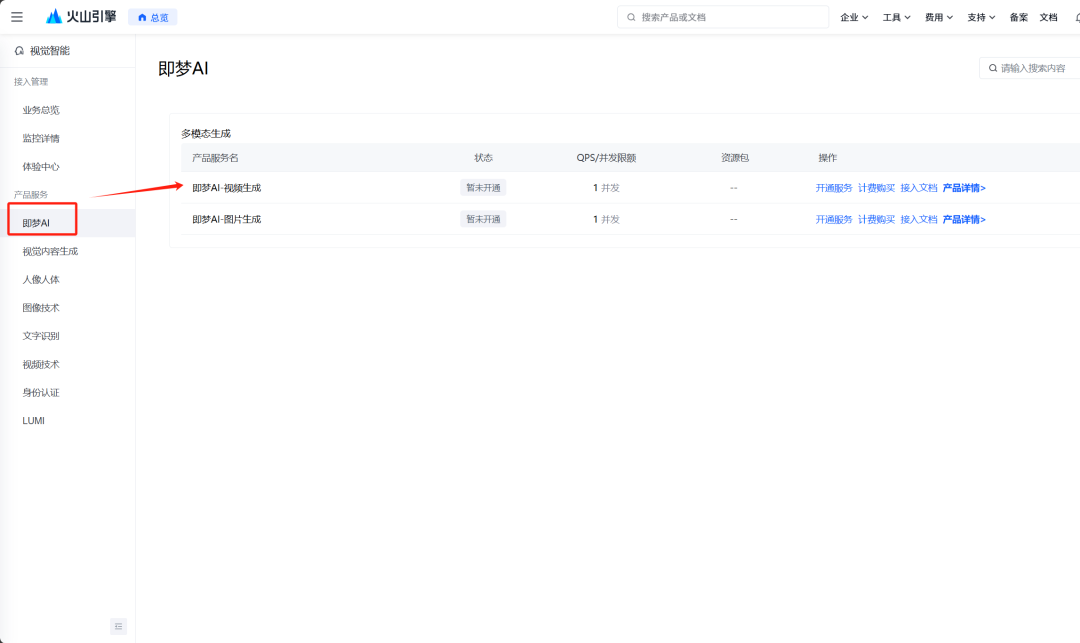
这个工作流的核心主要有两个,图生视频及背景音频。图生视频调用的是插件(封装调用的是即梦AI的API)我们提前注册一下,申请一个500S的免费额度
开通即梦AI_视频生成https://console.volcengine.com/ai/ability/detail/10
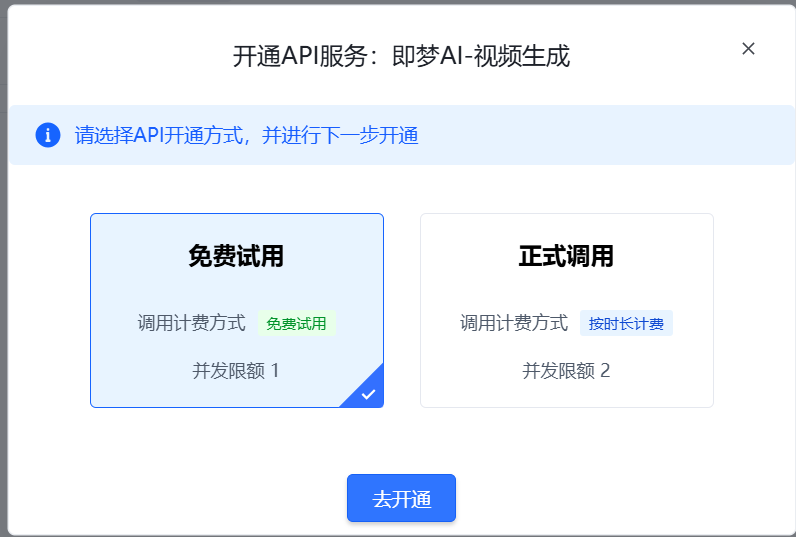
可以免费500秒,每个视频是5秒,也就是说可以免费生成100个视频。获取秘钥https://console.volcengine.com/iam/keymanage
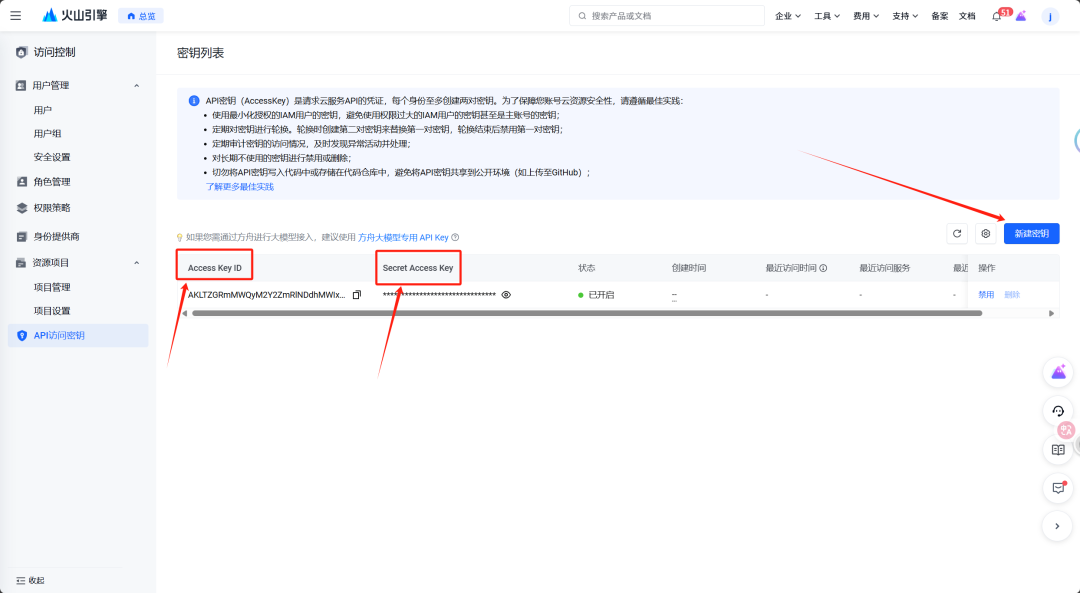
AccessKeyId与SecretAccessKey对应的秘钥先记下来,备用。
因为此工作流是以背景音频为基础建立的时间线(用剪映小助手插件在时间线上添加图片、音频、字幕等)所以也要准备一个古诗词音频,焦哥这里用的是《小池》音频素材音频素材《小池》https://p3-bot-workflow-sign.byteimg.com/tos-cn-i-mdko3gqilj/a31ccd5bc06d44c28c28597dd80cd8cb.MP3~tplv-mdko3gqilj-image.image?rk3s=81d4c505&x-expires=1780142251&x-signature=HfvubqLrLGjXRvG57aGdY2JCwI4%3D&x-wf-file_name=%E5%B0%8F%E6%B1%A0.MP3焦哥这里也准备了几个其它古诗词的背景音频素材以及本工作流的提示词、代码打包在了一起,请阅读到文章结尾获取方法。
1.大模型节点(古诗词分割)
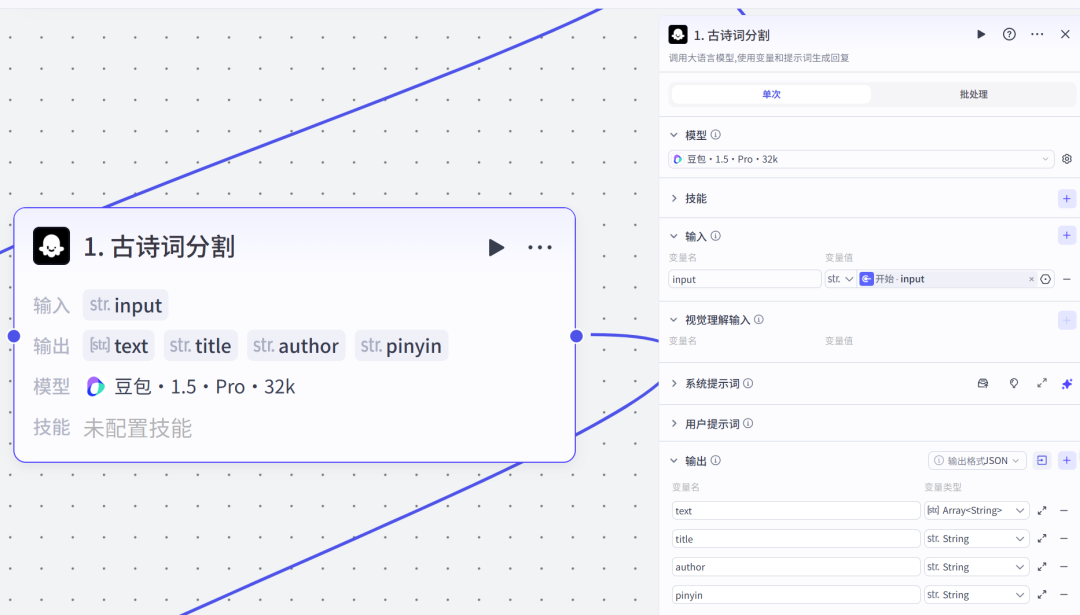
系统提示词
# 角色
你是一个专业的古诗词视频制作助手,能够精准分析古诗词内容{{input}},为制作爆款古诗词视频提供详细且准确的素材拆分。
## 技能
### 技能 1: 拆分古诗词信息
1.从输入的古诗词内容中,准确提取并单独输出古诗词的名字title,格式为:《》,例如:《池上》。
2.从输入信息里识别并输出古诗词的朝代和作者author,朝代加上[]符号,并与作者之间有2个空格,格式为:[] ,例如:[宋] 杨万里。
3.根据符号对古诗词进行分割输出text,清晰呈现古诗词的每一句内容。
4.对古诗的每一句都标注上拼音,拼音与汉字对应,一句是一行(包括拼音及对应的诗句),按正确顺序排列pinyin。
例如:
quán yǎn wú shēng xī xì liú
泉 眼 无 声 惜 细 流
## 限制:
-只输出与输入古诗词相关的名字、朝代、作者及分割后的文本内容。
-所输出的内容必须按照给定的格式进行组织,不能偏离框架要求。
2.大模型节点(生成古诗词绘画描述)注意:这里选择的是批处理,因为第1个节点的输出text是字符串数组。
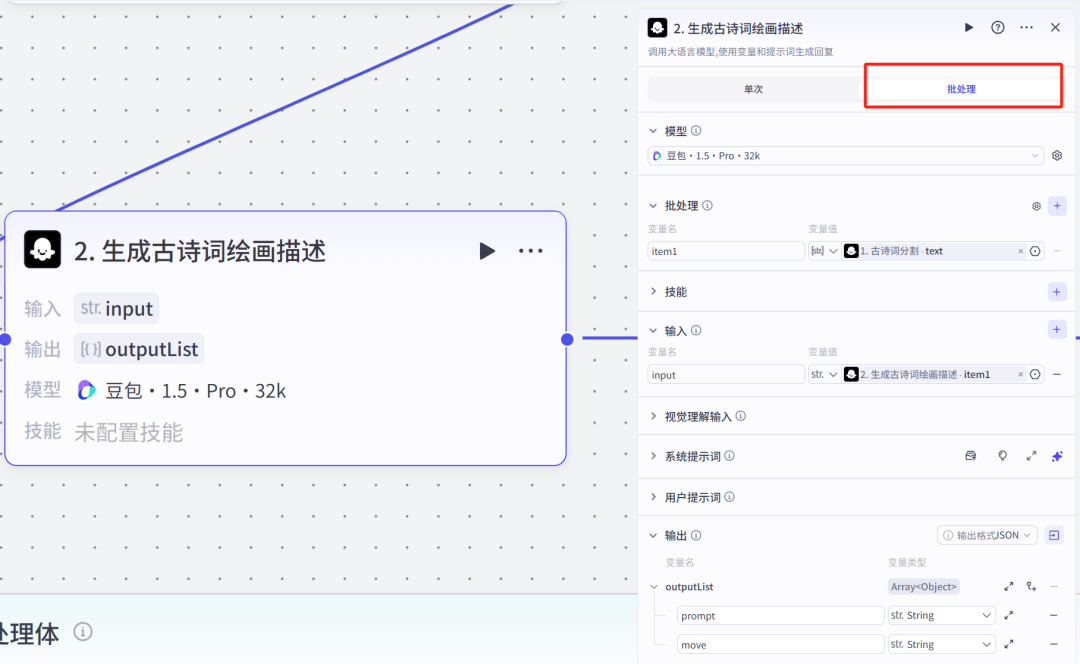
系统提示词
古诗词萌系小女孩画面提示词框架
诗句:[用户输入]
意象提取:解析古诗核心场景(田园 / 边塞 / 宫廷等)、动作(读 / 赏 / 思等)、道具(书 / 花 / 乐器等)、色彩氛围(冷暖 / 季节色)。
形象适配:汉服颜色、丝带色、配饰随古诗季节 / 情感调整(如《咏柳》用嫩绿,《江雪》用冷白),动作直接呼应诗句(如 “举头望明月”→ 抬头望月)。
场景还原:背景融入古诗典型元素(如《山居秋暝》→ 竹林、清泉;《枫桥夜泊》→ 客船、渔火),道具强化诗意(书卷、酒杯、船桨等)。
画面构图核心结构:
古风卡通3D渲染 + 萌系小女孩(固定造型) + 古诗意象解析(场景/动作/道具/色彩) + 视觉强化(光影/构图/质感)
古风卡通3D渲染,萌系小女孩为视觉核心。
-**形象固定**:大圆杏眼(睫毛卷翘,瞳光明亮),齐刘海,双丸子头系[丝带颜色(如古诗季节/意象色,例:春粉/秋黄)]丝带,脸颊腮红粉嫩,身着[汉服主色调(匹配古诗氛围,例:青绿/暖棕)]汉服([细节:如古诗相关花纹,例:梅纹/云纹],腰间[配饰,例:蝴蝶结/玉佩],下裙[材质,例:纱裙/锦缎]),[动作(贴合古诗,例:捧书/采菊/望月)]。
-**场景构建**:背景[古诗场景(例:室内+山水/田园+花海/边塞+大漠)],搭配[道具(例:书卷/花篮/胡琴)],[自然元素(例:花瓣飘落/月光倾洒/雪花纷飞)]。
-**视觉强化**:[光影(例:柔光/暖光/冷光,烘托古诗意境)],中心构图,浅景深(人物清晰,背景虚化)。色彩[主色调(如古诗情感,例:清新绿/萧瑟灰)]搭配[辅助色(例:粉白/金黄)],柔和高饱和。3D卡通写实质感(皮肤光滑,衣料垂坠,发丝分明)。
-**技术参数**:超高清,光追渲染,突出小女孩萌态与古诗意境,一眼吸睛。
示例:
输入:举头望明月
prompt:古风卡通3D渲染,萌系小女孩为核心。大圆杏眼,齐刘海,双丸子头系银白丝带,身着月白色汉服(绣云纹,腰间玉坠),跪坐床沿,手托香腮望月。背景室内,木窗映冷月,床前铺霜(光影冷白柔光,营造孤寂感)。中心构图,浅景深(人物清晰,窗外月光虚化)。色彩冷蓝为主,搭配银白,柔和低饱和。3D卡通写实,皮肤如瓷,衣料轻透,发丝带月光银辉。超高清,光追渲染,突出“望月思亲”萌态,瞬间共情古诗意境。
move:[核心动作,≤10 字,例:小女孩抬头望月]
注意:
仅输出prompt及move,思考过程禁止输出。
用户提示词
用户输入的古诗词:{{input}}
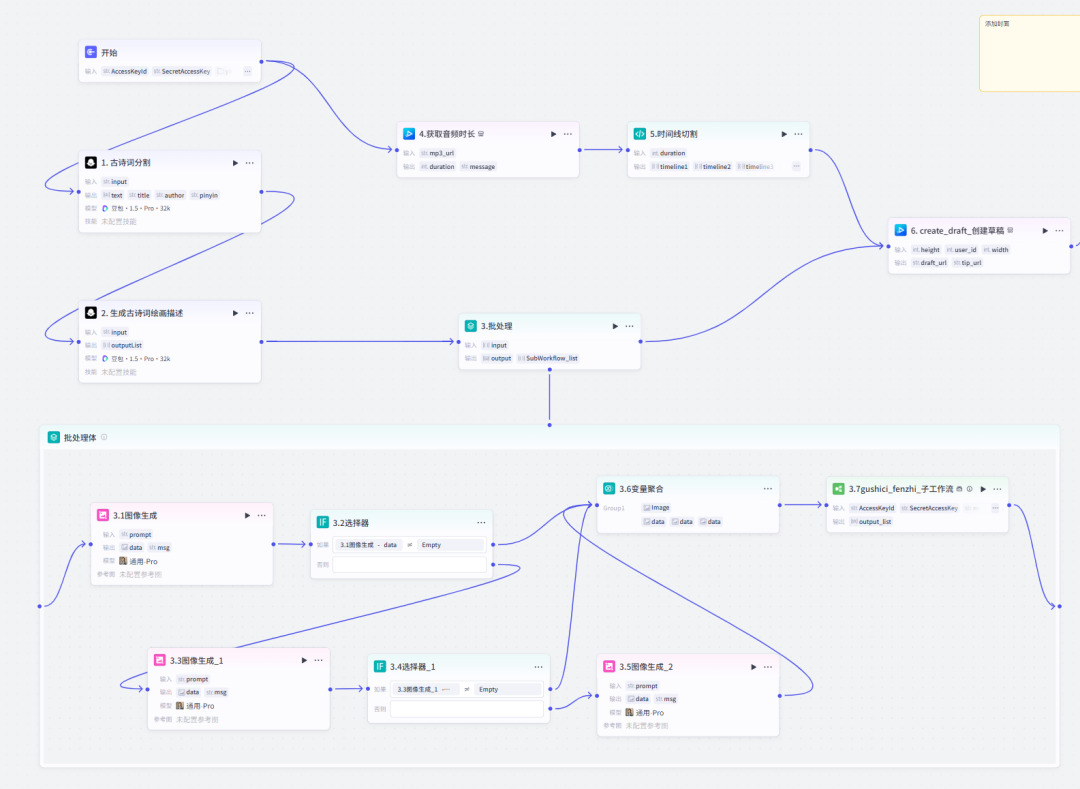
3.批处理(文生图、图生视频)
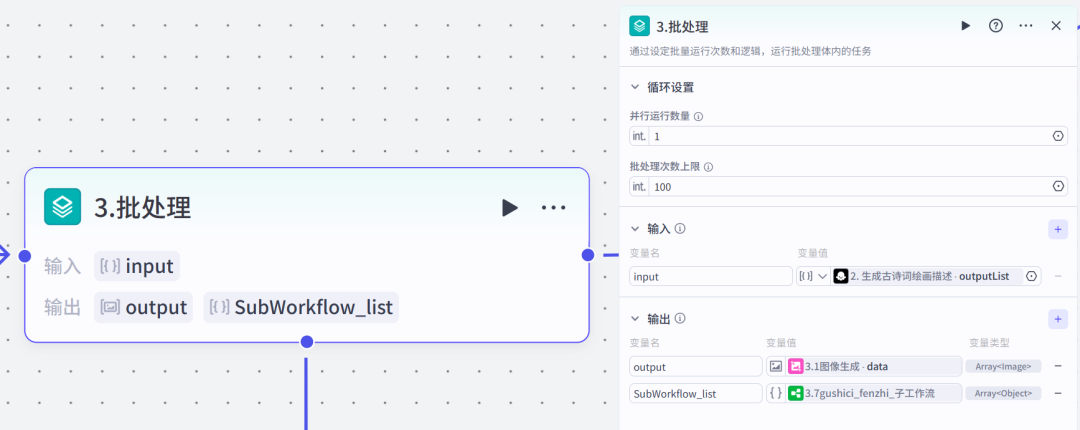
批处理体
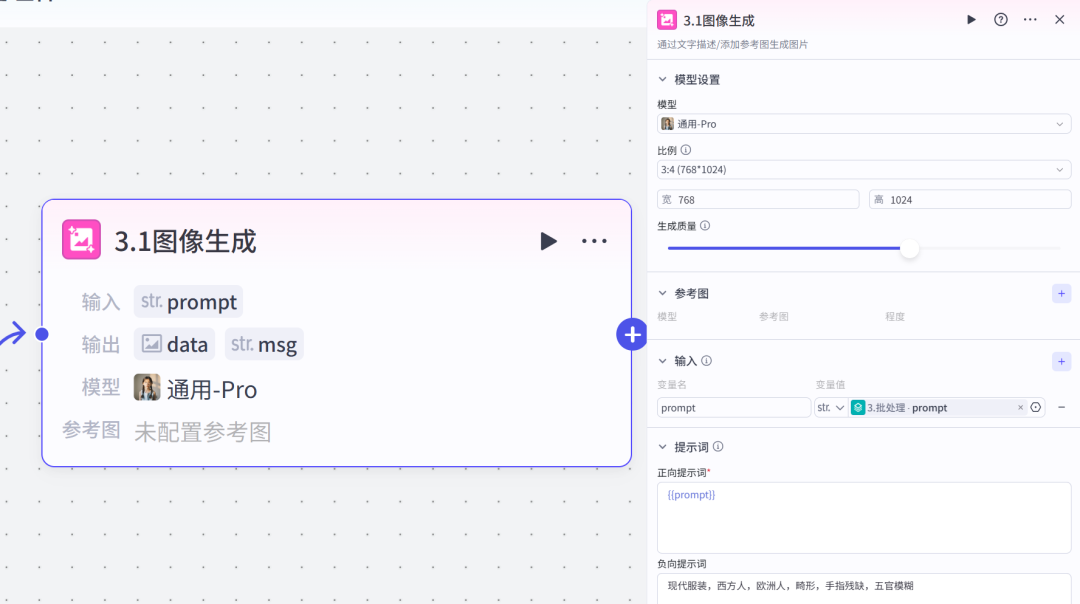
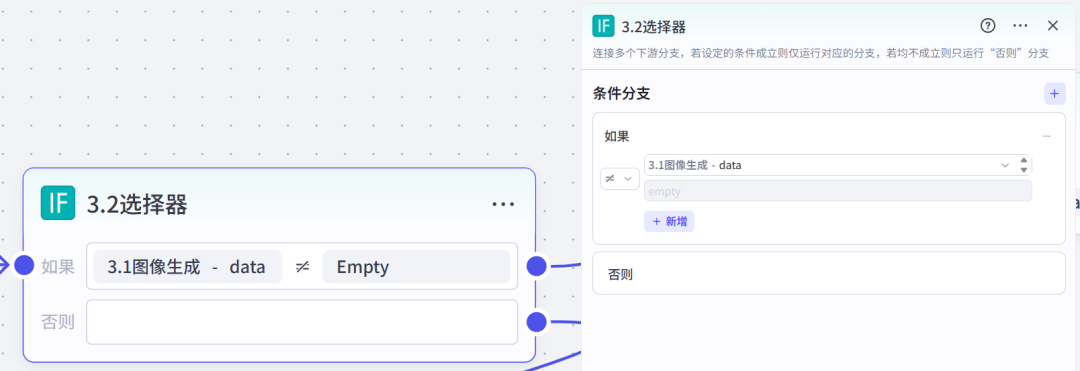
为什么这里添加选择器节点,重点说一下:最近扣子平台的图像生成节点很不稳定,经常不出图,大大影响了工作流的运行效率,为了让它返工,增加一个判断条件,如果图片是空值,就继续重复生图,如果是正常的就继续下一步。为此,我增加了两个选择器节点
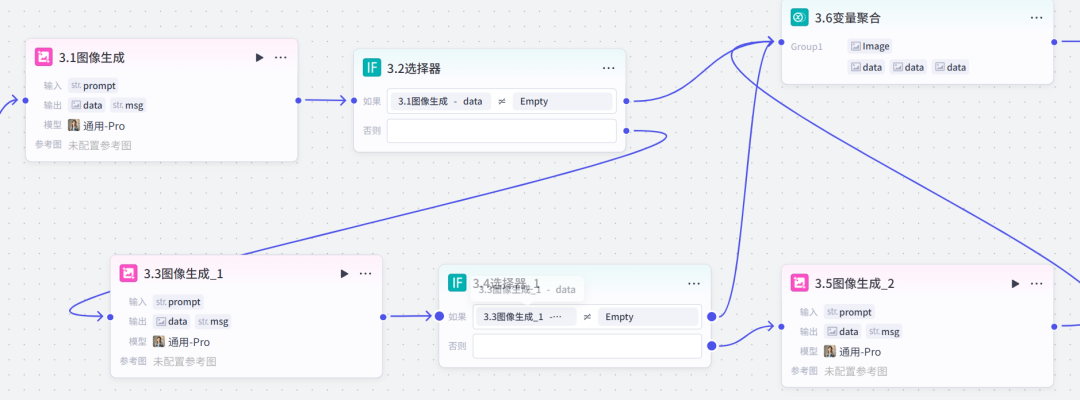
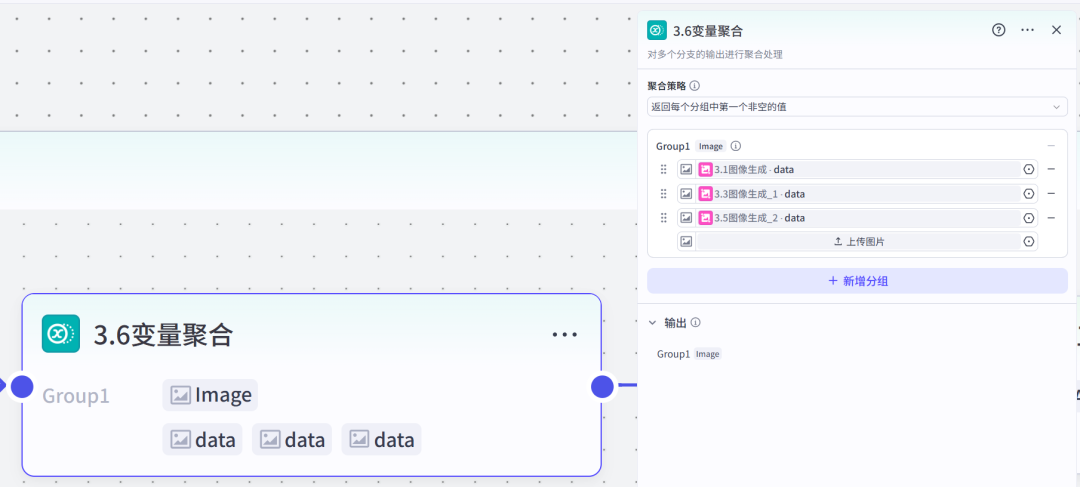
变量聚合节点,汇总图片数据。
第二部分3.7子工作流因为批处理节点中不允许再嵌套循环节点,所以图生视频的节点封装为一个子工作流。
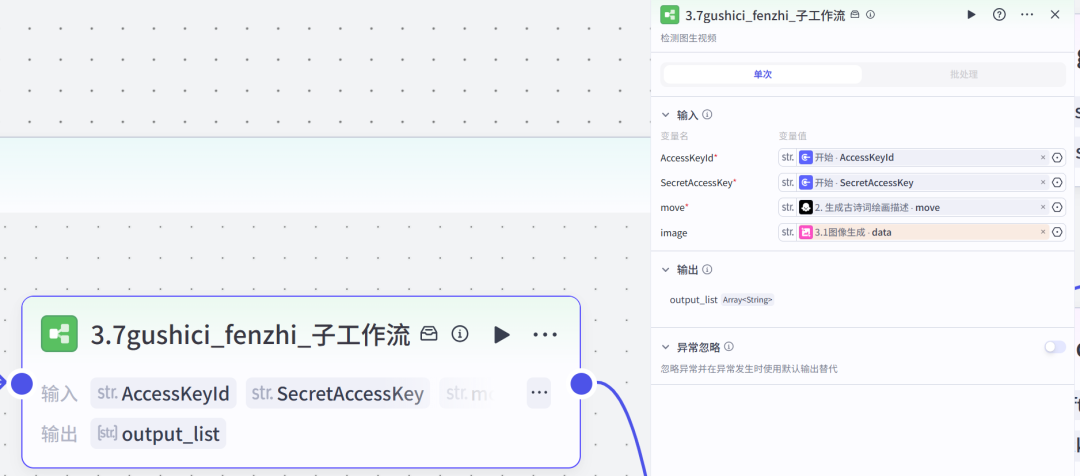
子工作流全览
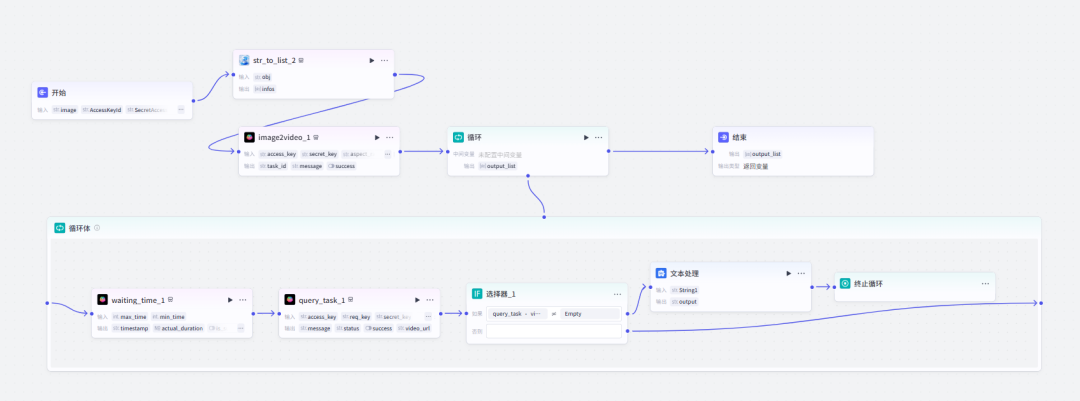
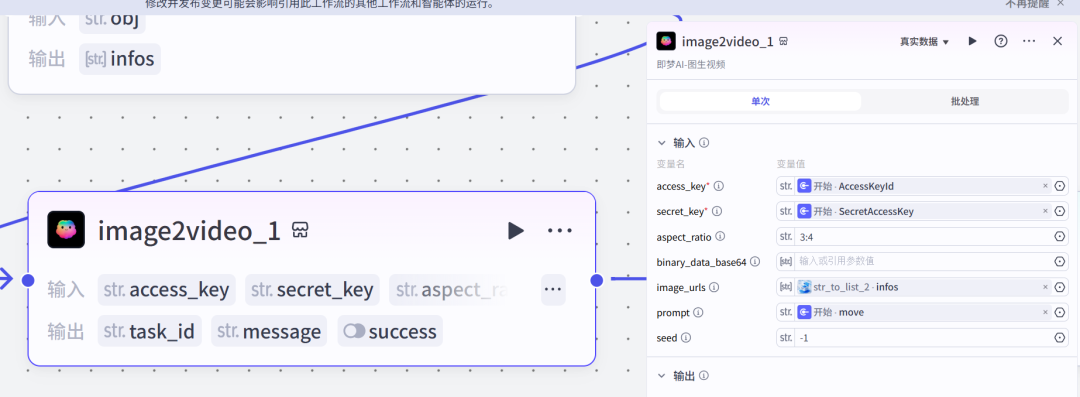
主要用到的就是这个插件主要原理:接收用户上传的图片,通过秘钥及设置要求调用即梦AI_图生视频图生视频任务是异步进行,并且并发是1(不允许循环上传任务)所以,我必须先等待一段时间,查询生成的任务状态,如果任务完成则结束,如果未完成,则继续查询。
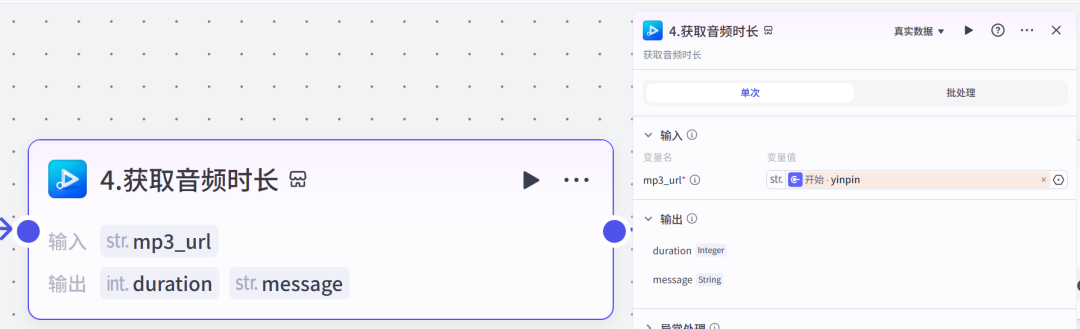
4.插件节点(获取音频时长)
5.代码节点(时间线切割)这里有四个时间线:timeline1:封面图占用的时间timeline2:视频(图生视频)占用的时间timeline3:结尾图片占用的时间timeline4:背景音频占用的总时间
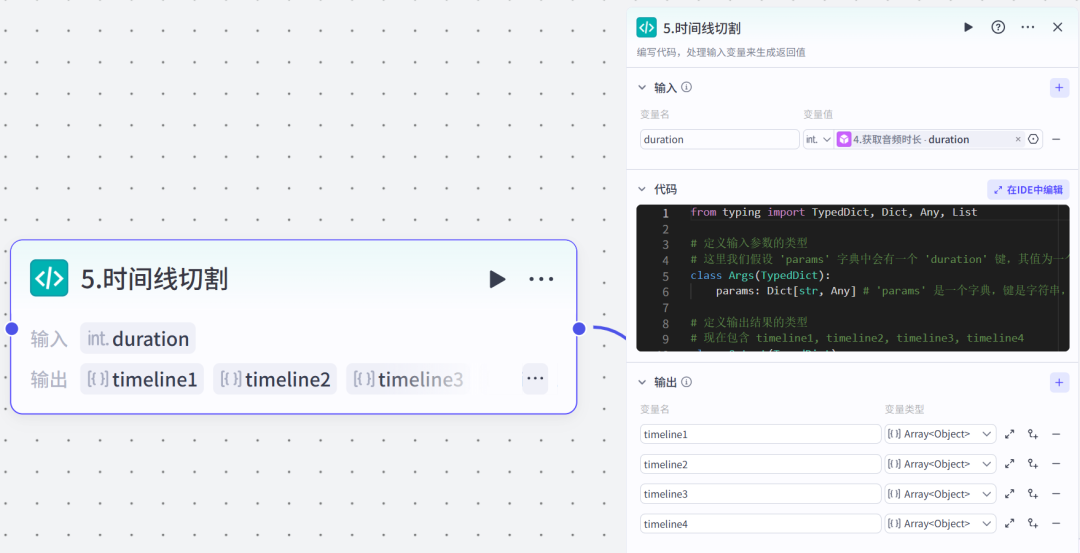
代码(python)
fromtypingimportTypedDict,Dict,Any,List
# 定义输入参数的类型
# 这里我们假设 'params' 字典中会有一个 'duration' 键,其值为一个整数。
classArgs(TypedDict):
params:Dict[str,Any]# 'params' 是一个字典,键是字符串,值可以是任何类型
# 定义输出结果的类型
# 现在包含 timeline1, timeline2, timeline3, timeline4
classOutput(TypedDict):
timeline1:List[dict]# timeline1 是一个包含字典的列表
timeline2:List[dict]# timeline2 是一个包含字典的列表
timeline3:List[dict]# timeline3 是一个包含字典的列表
timeline4:List[dict]# timeline4 是一个包含字典的列表 (新增)
asyncdefmain(args: Args) -> Output:
"""
主函数,用于根据输入的总持续时间计算四个时间线。
Args:
args (Args): 包含参数的字典,期望 args["params"]["duration"] 是总持续时间(微秒)。
Returns:
Output: 包含四个时间线数据的字典。
Raises:
ValueError: 如果输入的 duration 不合法(例如不足以生成 timeline1)。
KeyError: 如果 'params' 或 'duration' 键缺失。
Exception: 其他未预料到的错误。
"""
try:
# 从输入参数中获取 'params' 字典
params = args["params"]
# 从 'params' 字典中获取 'duration' 值,这是用户提供的总时间,单位微秒
duration:int= params["duration"]
# --- 1. 计算 timeline1 ---
# timeline1 的开始时间固定为 0
timeline1_start =0
# timeline1 的结束时间固定为 4,000,000 微秒
timeline1_end =4000000
# timeline1 的持续时间
# timeline1_duration = timeline1_end - timeline1_start # 即 4,000,000
# 创建 timeline1 的数据结构,它是一个列表,包含一个字典元素
timeline1:List[dict] = [{"start": timeline1_start,"end": timeline1_end}]
# --- 2. 计算 timeline2 ---
# 检查总时间 duration 是否足够分配给 timeline1
ifduration < timeline1_end:
# 如果总时间小于 timeline1 的结束时间,则无法继续生成 timeline2 和 timeline3, timeline4
raiseValueError(f"总持续时间 'duration' ({duration}μs) 不足以覆盖 timeline1 的结束时间 ({timeline1_end}μs)。")
# 计算 timeline2 可用的总时间:用总时间 duration 减去 timeline1 已经占用的时间
remaining_duration_for_timeline2 = duration - timeline1_end
# 将 timeline2 可用的总时间平均分成 4 份,得到每份的平均时间 'a'
# 使用整数除法 '//' 来确保时间 'a' 是整数,因为时间单位通常是整数
average_segment_duration_a = remaining_duration_for_timeline2 //4
# 初始化 timeline2 列表,用于存放它的各个时间段
timeline2:List[dict] = []
# timeline2 的第一个时间段的开始时间是 timeline1 的结束时间
current_timeline2_start = timeline1_end
# timeline2 有 4 个时间段。我们先计算前 3 个。
# 循环生成 timeline2 的前三个时间段
for_inrange(3):# 循环3次,对应前三个时间段
# 当前时间段的结束时间 = 当前开始时间 + 平均时间 'a'
current_timeline2_end = current_timeline2_start + average_segment_duration_a
# 将当前时间段(包含start和end)添加到 timeline2 列表中
timeline2.append({"start": current_timeline2_start,"end": current_timeline2_end})
# 下一个时间段的开始时间是当前时间段的结束时间
current_timeline2_start = current_timeline2_end
# 计算 timeline2 的第四个(也是最后一个)时间段
# 第四个时间段的开始时间是第三个时间段的结束时间 (即 current_timeline2_start 当前的值)
# 第四个时间段的结束时间必须是总的 duration,以确保 timeline2 的总结束点是 'duration'
timeline2.append({"start": current_timeline2_start,"end": duration})
# --- 3. 计算 timeline3 ---
# timeline3 的开始时间是 timeline2 的最后一个时间段的结束时间,也就是总的 'duration'
timeline3_start = duration# timeline2 的最后一个 end 就是总 duration
# timeline3 的持续时间固定为 500,000 微秒
timeline3_duration =500000
# timeline3 的结束时间 = timeline3 的开始时间 + 其持续时间
timeline3_end = timeline3_start + timeline3_duration
# 创建 timeline3 的数据结构,它是一个列表,包含一个字典元素
timeline3:List[dict] = [{"start": timeline3_start,"end": timeline3_end}]
# --- 4. 计算 timeline4 (新增) ---
# timeline4 的开始时间固定为 0
timeline4_start =0
# timeline4 的结束时间是 timeline3 的最后一个 end 时间
# 由于 timeline3 只有一个元素,其 end 时间就是 timeline3_end
timeline4_end = timeline3_end# timeline3_end 的值是 duration + 500000
# 创建 timeline4 的数据结构,它是一个列表,包含一个字典元素
timeline4:List[dict] = [{"start": timeline4_start,"end": timeline4_end}]
# 构建最终的输出结果字典
ret: Output = {
"timeline1": timeline1,
"timeline2": timeline2,
"timeline3": timeline3,
"timeline4": timeline4# 添加 timeline4 到返回结果
}
# 返回计算得到的四个时间线数据
returnret
exceptKeyErrorase:
# 捕获当 'params' 或 'duration' 键不存在于输入参数中时发生的 KeyError
# 抛出一个 ValueError,提示哪个必需的键缺失了
raiseValueError(f"输入参数中缺少必需的键:{str(e)}")frome
exceptValueErrorase:
# 捕获上面代码中可能由我们主动抛出的 ValueError (例如 duration 不足)
# 重新抛出,以便上层调用者可以处理
raisee
exceptExceptionase:
# 捕获任何其他在主函数执行过程中发生的未知异常
# 抛出一个通用的 Exception,并附带原始错误信息
raiseException(f"在 main 函数中发生错误:{str(e)}")frome
第三部分接下来就是剪映小助手插件的天下了(视频工作流的老朋友)
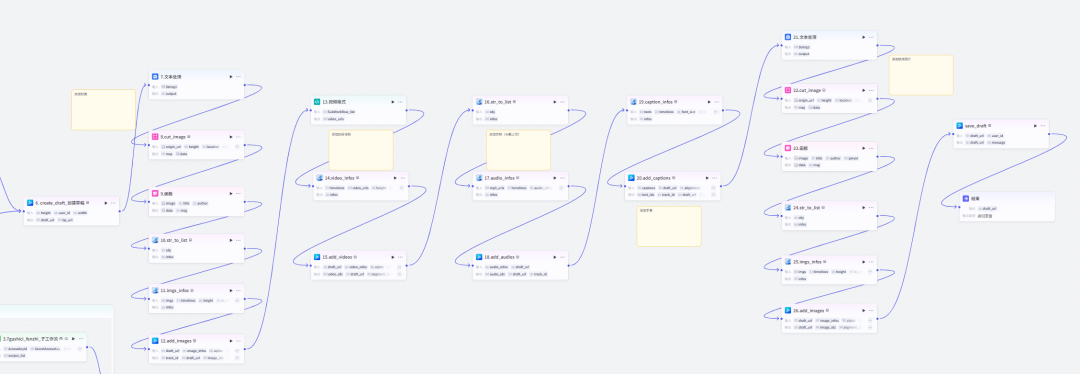
6.创建草稿
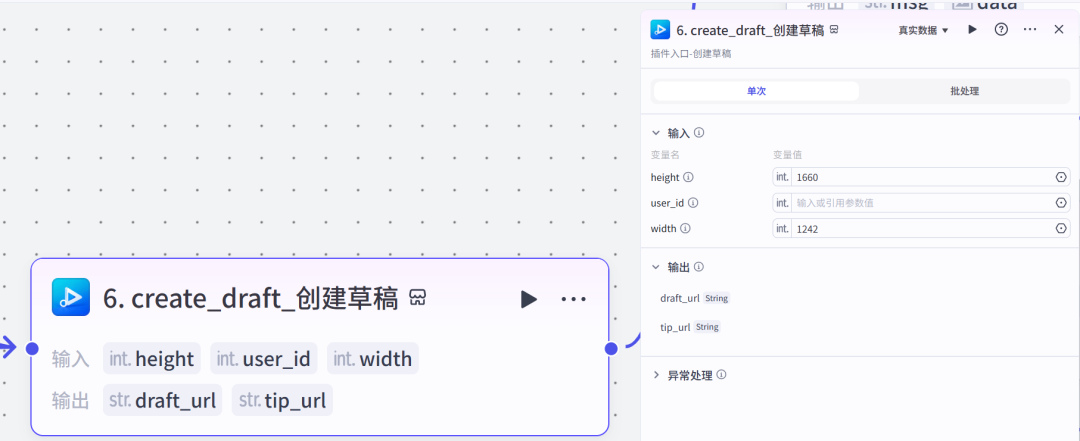
7~12添加封面图
其中的画板,焦哥是这样设置的
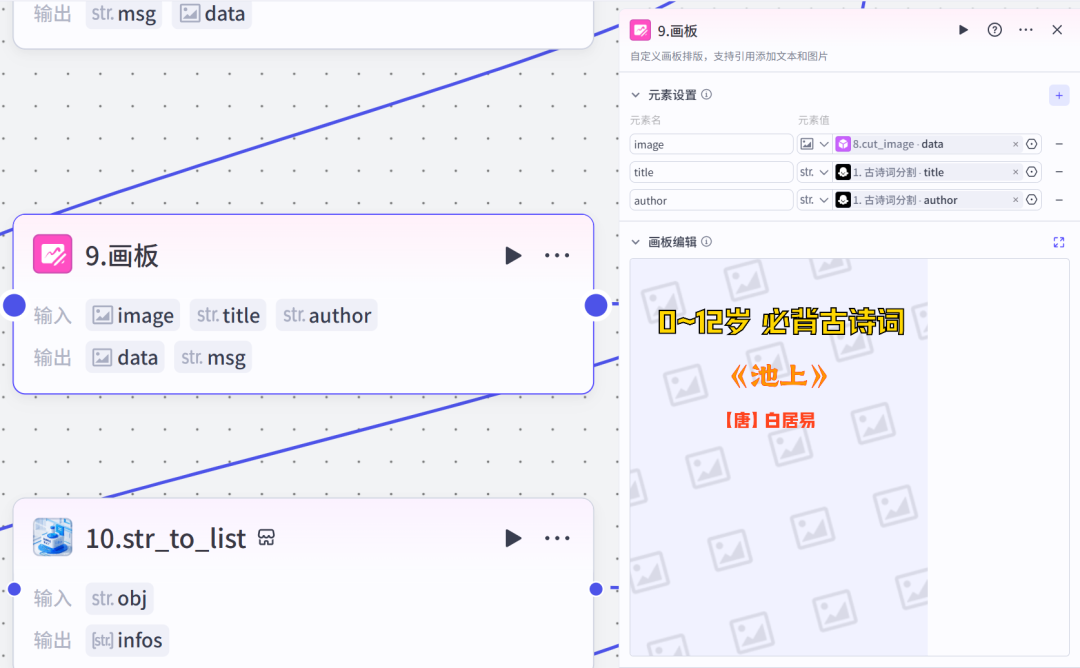
其它几个节点,前面的几篇文章反复都提到过,这里就不再唠叨了。
13~15添加视频
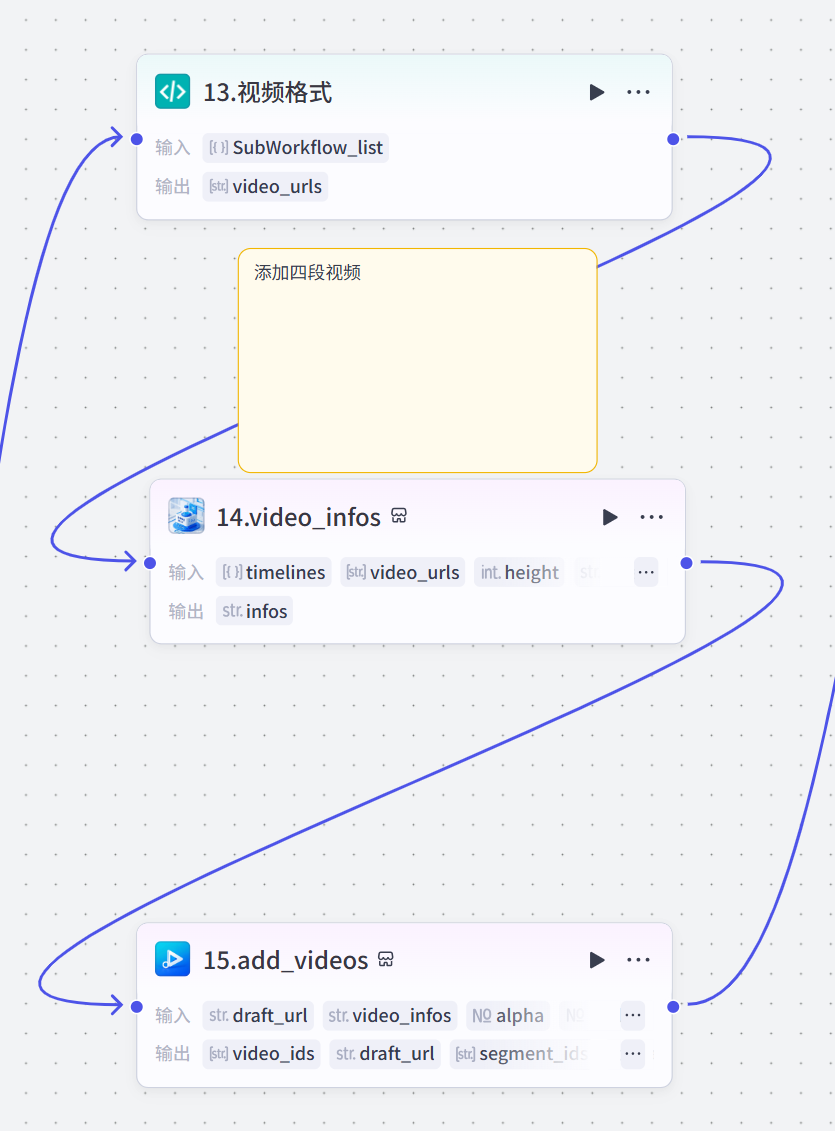
其中第13个代码节点的作用是从对象数组中提取视频,放到字符串数组中。
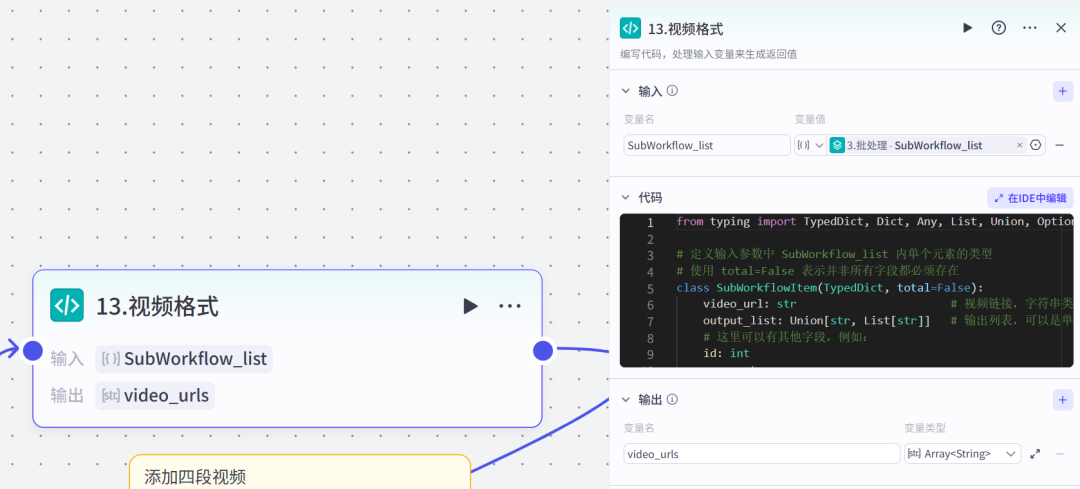
代码(python)
fromtypingimportTypedDict,Dict,Any,List,Union,Optional
# 定义输入参数中 SubWorkflow_list 内单个元素的类型
# 使用 total=False 表示并非所有字段都必须存在
classSubWorkflowItem(TypedDict, total=False):
video_url:str # 视频链接,字符串类型 (可选)
output_list:Union[str,List[str]] # 输出列表,可以是单个URL字符串或URL字符串列表 (可选)
# 这里可以有其他字段,例如:
id:int
name:str
# ... 等等
# 定义输入参数的类型
classArgs(TypedDict):
params:Dict[str,Any]# 'params' 是一个字典,键是字符串,值可以是任何类型
# 我们期望 params 中包含 "SubWorkflow_list"
# 定义输出结果的类型
classOutput(TypedDict):
video_urls:List[str]# video_urls 是一个包含字符串的列表
asyncdefmain(args: Args) -> Output:
"""
主函数,用于从 SubWorkflow_list 中提取所有视频链接。
它会优先查找 'video_url' 键,如果找不到或无效,则会查找 'output_list' 键。
Args:
args (Args): 包含参数的字典。
期望 args["params"]["SubWorkflow_list"] 是一个列表,
列表中的每个元素是一个字典。
Returns:
Output: 包含提取到的视频链接列表的字典。
Raises:
KeyError: 如果 'params' 或 'SubWorkflow_list' 顶层键缺失。
TypeError: 如果 'SubWorkflow_list' 不是列表,或其元素不是字典。
Exception: 其他未预料到的错误。
"""
try:
# 从输入参数中获取 'params' 字典
params = args["params"]
# 从 'params' 字典中获取 'SubWorkflow_list'
sub_workflow_list:List[SubWorkflowItem] = params["SubWorkflow_list"]# 类型提示更新
# 初始化一个空列表,用于存储提取到的视频链接
video_urls_list:List[str] = []
# 检查 sub_workflow_list 是否确实是一个列表
ifnotisinstance(sub_workflow_list,list):
raiseTypeError(f"'SubWorkflow_list' 期望是一个列表,但得到了{type(sub_workflow_list).__name__}")
# 遍历 SubWorkflow_list 中的每一个对象(字典)
foritem_index, iteminenumerate(sub_workflow_list):
# 检查当前 item 是否是字典类型
ifnotisinstance(item,dict):
raiseTypeError(f"SubWorkflow_list 中的元素期望是字典,但在索引{item_index}处得到了{type(item).__name__}")
found_url_in_item_from_video_url_key =False# 标记是否已从 'video_url' 键成功获取URL
# 1. 优先尝试从 'video_url' 键获取
# 使用 item.get() 来安全地访问,如果键不存在则返回 None
video_url_candidate = item.get("video_url")
ifisinstance(video_url_candidate,str)andvideo_url_candidate.strip():# 确保是字符串且非空
video_urls_list.append(video_url_candidate)
found_url_in_item_from_video_url_key =True
# 如果 video_url_candidate 不是字符串或为空,则此路径不添加URL,found_url_in_item_from_video_url_key 保持 False
# 2. 如果没有从 'video_url' 键获取到有效的URL,则尝试从 'output_list' 键获取
ifnotfound_url_in_item_from_video_url_key:
output_list_candidate = item.get("output_list")
ifisinstance(output_list_candidate,str)andoutput_list_candidate.strip():
# 情况 A: output_list 本身就是一个字符串 URL
video_urls_list.append(output_list_candidate)
elifisinstance(output_list_candidate,list):
# 情况 B: output_list 是一个列表,可能包含多个 URL
forurl_in_listinoutput_list_candidate:
ifisinstance(url_in_list,str)andurl_in_list.strip():# 确保列表中的元素是字符串且非空
video_urls_list.append(url_in_list)
# else: (可选)可以记录列表中非字符串或空字符串的元素
# print(f"警告: 项目索引 {item_index} 的 'output_list' 列表中的元素不是有效URL字符串: {url_in_list}")
# else: (可选)可以记录 'output_list' 存在但类型不符合预期的情况
# if output_list_candidate is not None:
# print(f"警告: 项目索引 {item_index} 的 'output_list' 类型不受支持: {type(output_list_candidate)}")
# (可选)如果在此 item 中完全没有找到任何 URL,可以根据需求记录
# if not video_urls_list or (len(video_urls_list) > 0 and video_urls_list[-1] not in item.values()): # 粗略检查
# if not found_url_in_item_from_video_url_key and not item.get("output_list"): # 更精确的检查
# print(f"信息: 项目索引 {item_index} 未通过 'video_url' 或 'output_list' 提供URL: {item}")
# 构建最终的输出结果字典
ret: Output = {
"video_urls": video_urls_list
}
# 返回包含视频链接列表的字典
returnret
exceptKeyErrorase:
# 捕获当 'params' 或 'SubWorkflow_list' 顶层键不存在于输入参数中时发生的 KeyError
raiseValueError(f"输入参数中缺少必需的顶层键:{str(e)}")frome
exceptTypeErrorase:
# 捕获上面代码中可能由我们主动抛出的 TypeError (例如类型不匹配)
raiseValueError(f"输入参数类型错误或结构不符合预期:{str(e)}")frome
exceptExceptionase:
# 捕获任何其他在主函数执行过程中发生的未知异常
raiseException(f"在 main 函数中发生错误:{str(e)}")frome
16~18添加背景音频
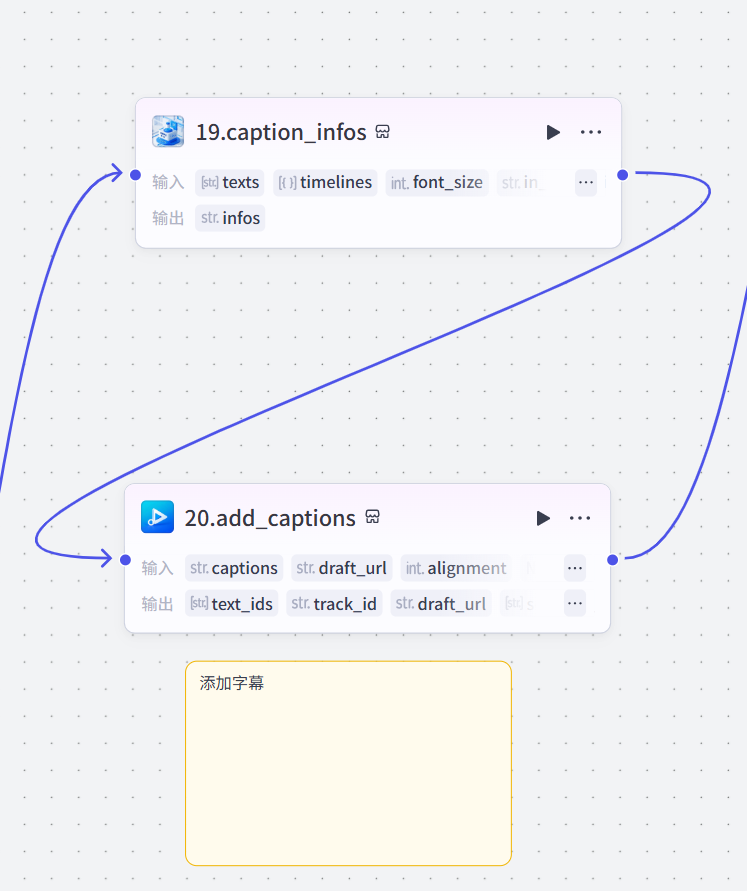
19~20添加字幕
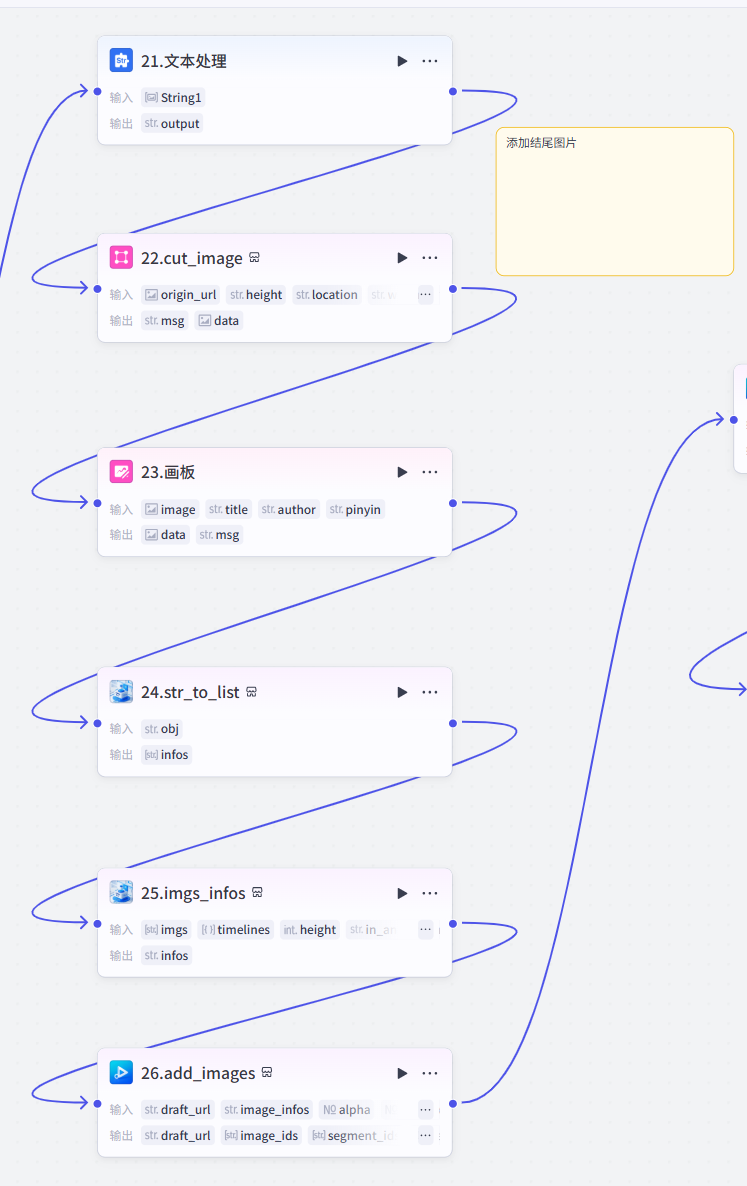
21~26添加结尾图片
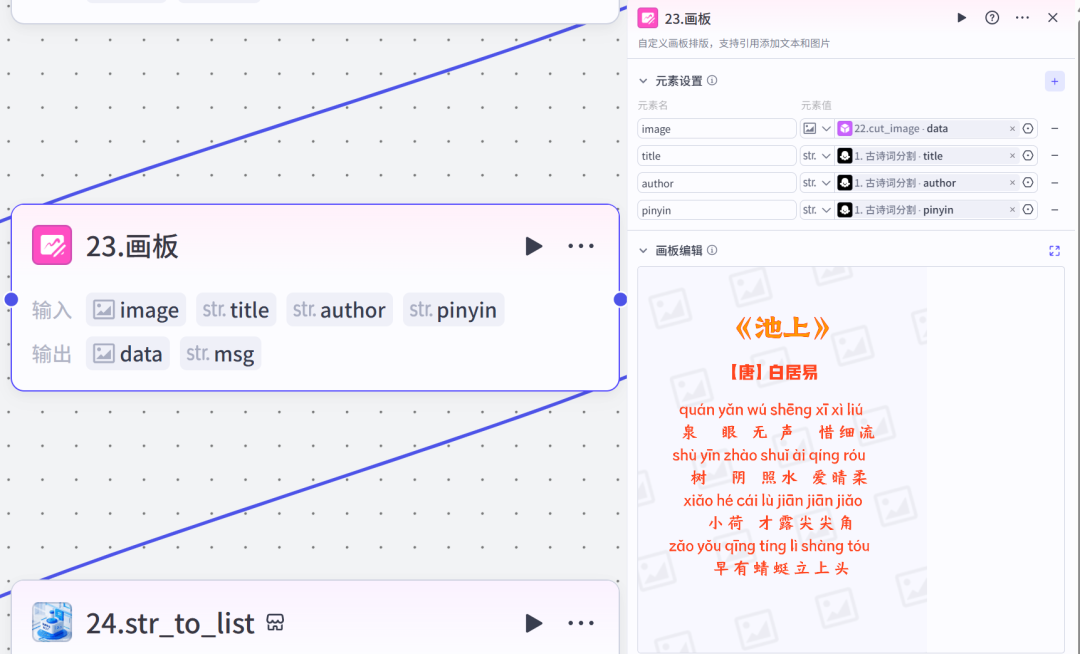
其中的画板,焦哥是这样设置的
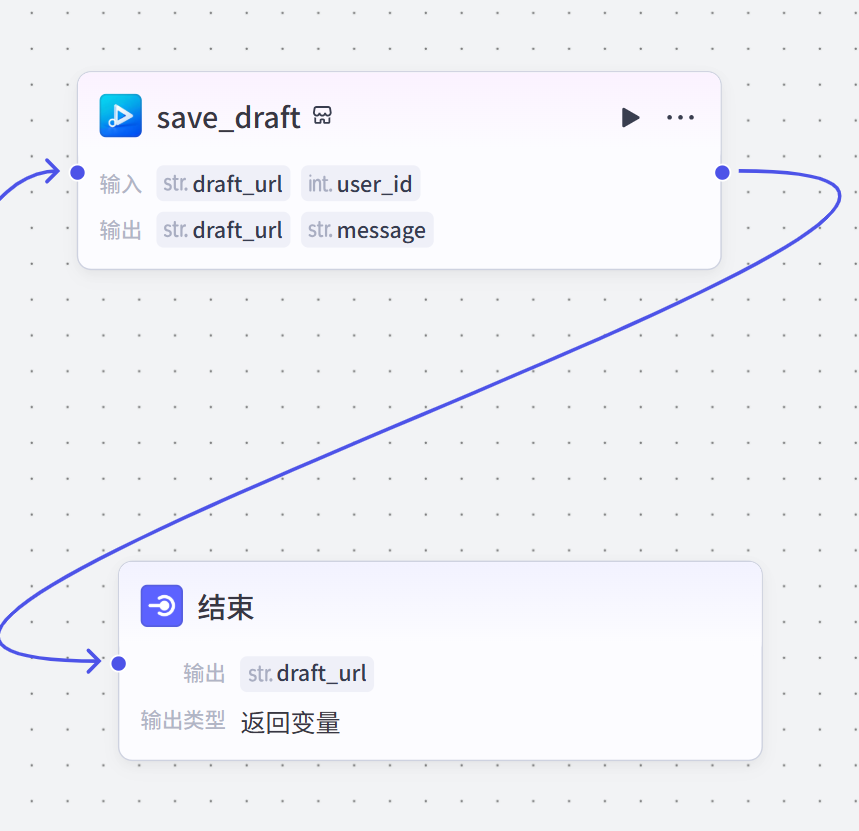
结束节点保存草稿并输出到结束节点
都已经看到这里了,如果觉得对你有帮助,记得点赞、在看、评论、转发哦!
获取完整的工作流飞书文档,麻烦您一键三连,评论区留言“古诗词”,加焦哥VX,邀请您加入交流群,免费领取飞书AI智能体知识库资料。
完整的工作流,我已经上传到Coze团队空间了,后期会逐步更新新的智能体,如果你也想一键复刻这样的工作流,欢迎加入我的团队空间,添加焦哥VX获取加入方法。



© 版权声明
文章版权归作者所有,未经允许请勿转载。


