
就在前不久,豆包的图像生成功能更新了「超能创意1.0」模式(CreationAgent v1.0)!
目前还处于内测阶段,打开一看居然获得了内测资格,于是我二话不说直接上手开测。
经过几天的深度体验,这款工具确实给我带来了不少惊喜。从出图效率到生成质量,我愿称之为国产版GPT-4O!
如何使用访问:https://www.doubao.com/chat/create-image即可立即体验全新的生图功能!
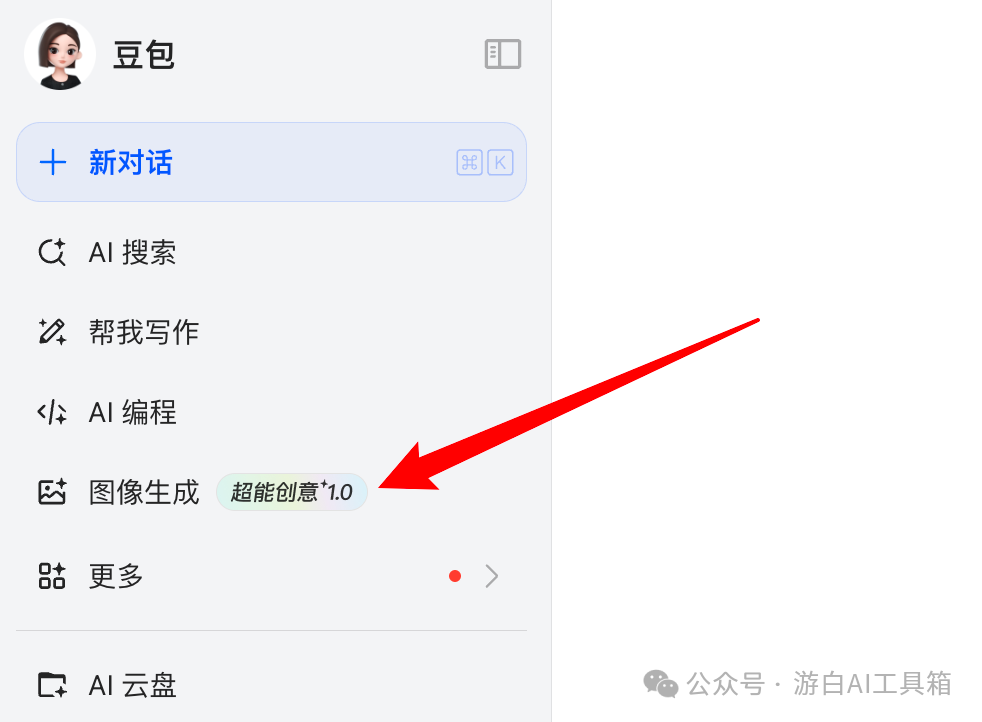
如果能看到「图像生成」右侧的”超能创意1.0″标识,那么恭喜你已经成功获得内测资格!
没有内测到的也不用担心,我给大家准备了官方的申请入口:https://bytedance.larkoffice.com/share/base/form/shrcnEjn2nIEZrQkWOiMfP1VxEc
点击链接,按照要求填写即可申请内测资格,一般几天内就会通过。
接下来让我们来看看豆包这次到底更新了什么,又有哪些新的玩法?
豆包这次更新的「超能创意1.0」大体上可以分为以下三个方面
-
1.智能增强:图像生成基于更智能的LLM模型,提示词不用写的很详细,AI就能自动联想并补全细节。 -
2.上下文理解:模型能记住上一次生成的结果,可以反复用提示词对图片进行修改。 -
3.批量生成:支持一次性生成多张不同风格,不同尺寸的图片,一次最多能生成20张。
下面是我这几天探索的一些玩法
理解意图使用简单的提示词即可完成图片的生成,AI会自动理解意图并帮忙补充细节。


可以看到,我的提示词中只提到了「宇航员头盔」「猫」「宇宙星辰」这三个关键词,豆包自己就开始了提示词的脑补,相当于把我的提示词用他自己的理解进行了优化,最终生成了一张还不错的细节丰富的猫咪照片。
批量生成可以同时生成多张不同风格的图片。






基本上完全满足了我的要求,中文文字的生成也很准确,只是在拼音的生成上略有缺憾。
比例适配可以同时生成多种比例的图片,甚至可以直接用「电脑壁纸」、「手机壁纸」、「头像」等关键词,AI会自动匹配合适的尺寸。



生成的图片尺寸完全正确,简直不要太方便。
风格参考可以根据提供图片的风格,生成类似风格的图片。





风格转换将图片转换为多种风格。



整个画面的主体建筑基本保持了一致,最后的摄影风格有点惊艳到我了。
局部修改替换人物背景,衣服,去掉图片中的文字,图片中添加物体
2. 去除背景3. 图片上方增加Q版文字:BEAR



故事创作通过指定故事情节一次性生成多张故事分镜。
请以三体人入侵地球这段情节给我生成6个分镜图片,每个分镜配上对应的文字,像素风格,比例 「16:9」






上述的部分灵感来自于官方的演示文档:
总体用下来的感受就是:模型的理解能力很强,生图效率嘎嘎高,有点AGI那味了。但是像人物一致性,部分局部修改,指令遵循上还有很大的提升空间。
结语豆包的这次更新,可以说进一步降低了AI创意生成的技术门槛,也让我更加坚信,未来一定会是一个技术门槛不断降低,各种创意百花齐放的时代!
当AI有能力处理繁琐的技术细节,我们将有更多精力专注于创意本身,在这个技术与艺术共舞的新时代,释放自己无限的创意潜能!
© 版权声明
文章版权归作者所有,未经允许请勿转载。


