2个安装包2条指令,轻松构建本地RAG系统,搭建个人AI知识库

点击上方“蓝色字体”关注我,每天推送“AI干货”!
上一期文章中分享过AnythingLLM部署deepseek-R1+知识库,有粉丝说本地部署的这个知识库不好用经常无法解析。
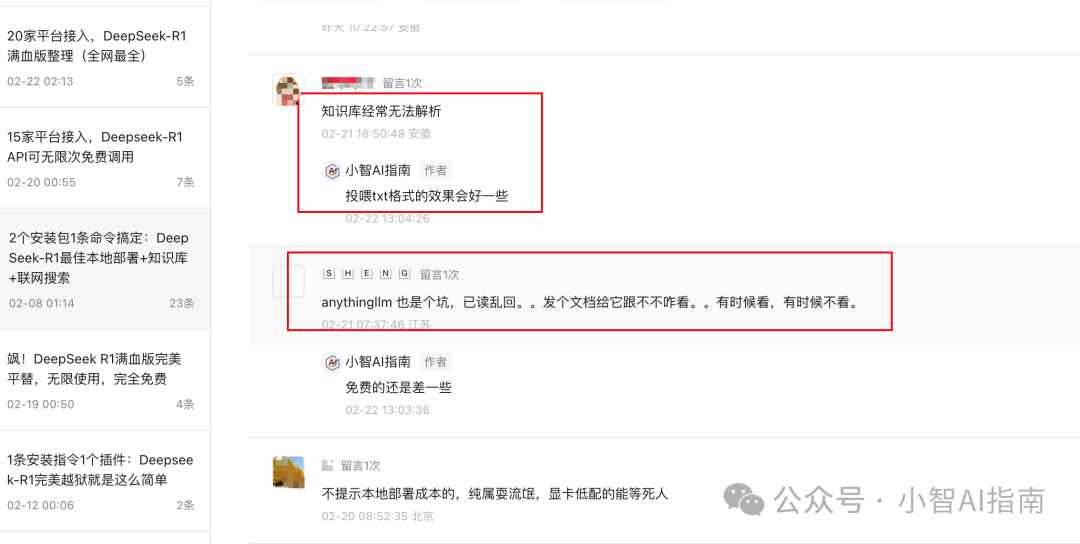
小智这里给大家分享一个解决方案。一来是解决知识库不准确的问题,二是提供一个搭建私有AI知识库的快速教学,通过RAG给本地AI大模型投喂数据。至于为什么要搭建本地知识库以及作用这里就不再细说,咱们直接奔入主题。省略ollama和anythingllm本地安装的过程,查看之前的文章,都提供有下载路径
Ollama安装Qwen2.5大模型
一般电脑配置安装Qwen2.5:7b即可,如果配置足够好可以安装32b甚至72b
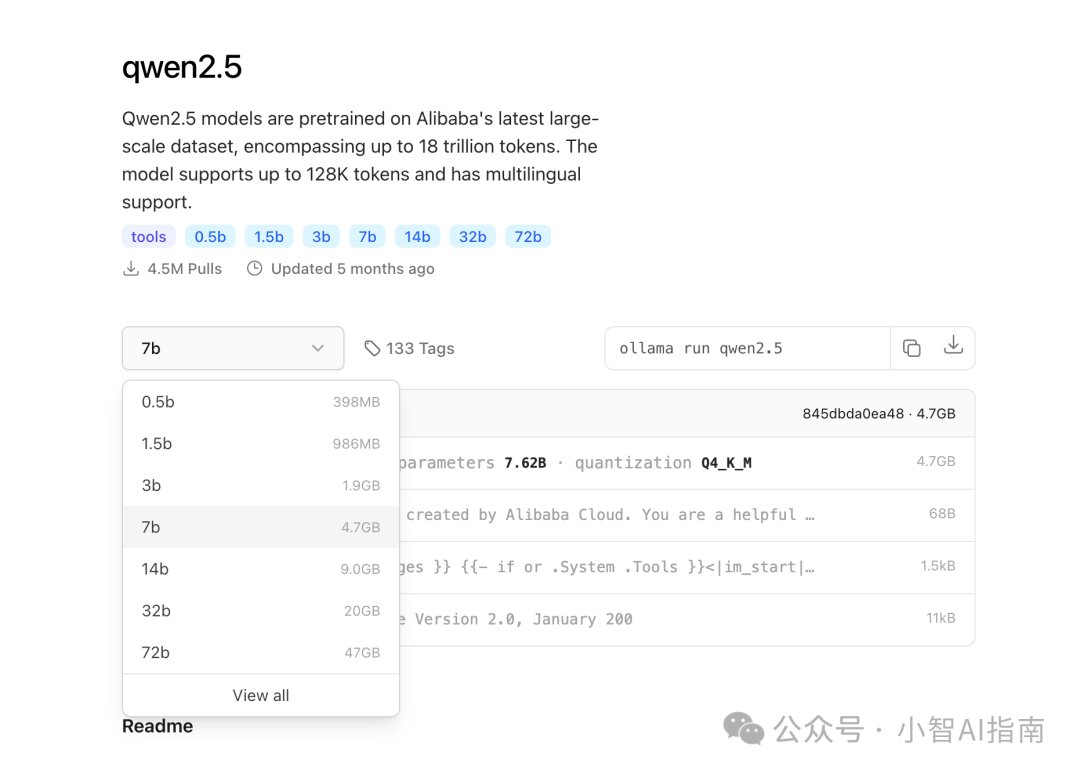
操作也是非常简单,一条命令搞定ollama pull qwen2.5:7b
下载完后可以在AnythingLLM聊天设置中的下拉选项中可以看到 ,选中即可
Ollama下载向量模型
先找到需要安装的向量模型,通常咱们都去ollama官网去搜索
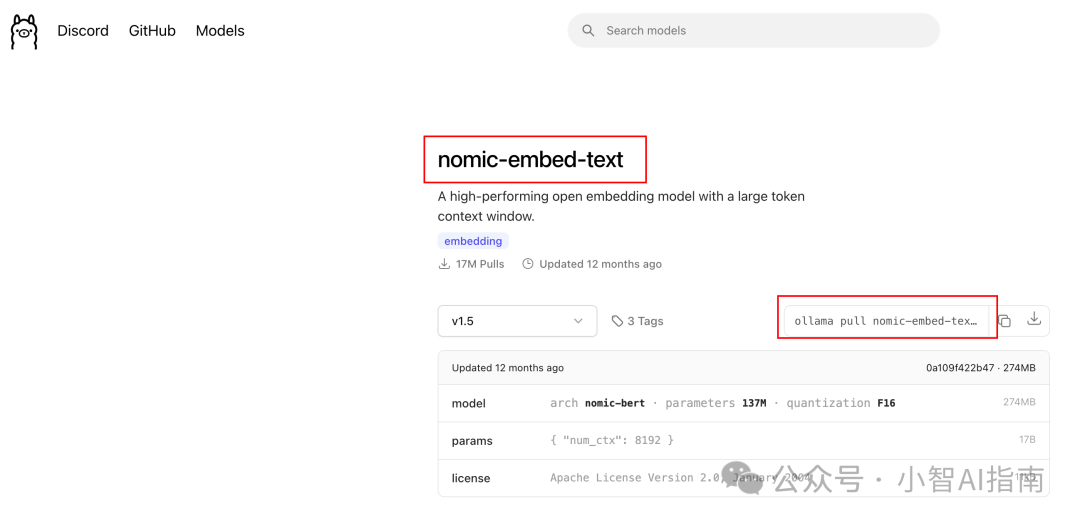
同上也是使用ollam常用安装命令ollama pull nomic-embed-text
这里顺带说一下ollama的相关命令咱们也不用去硬记,用的时候查阅一下就行和linux中的一些操作命令一致。无非常用的就是拉取、删除ollama --help
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show informationfora model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about anycommand
Flags:
-h, --help helpforollama
-v, --version Show version information
Use"ollama [command] --help"formore information about acommand.
Embedder首选项—>选择本地运行嵌入模型->模型选择“nomic-embed-text”
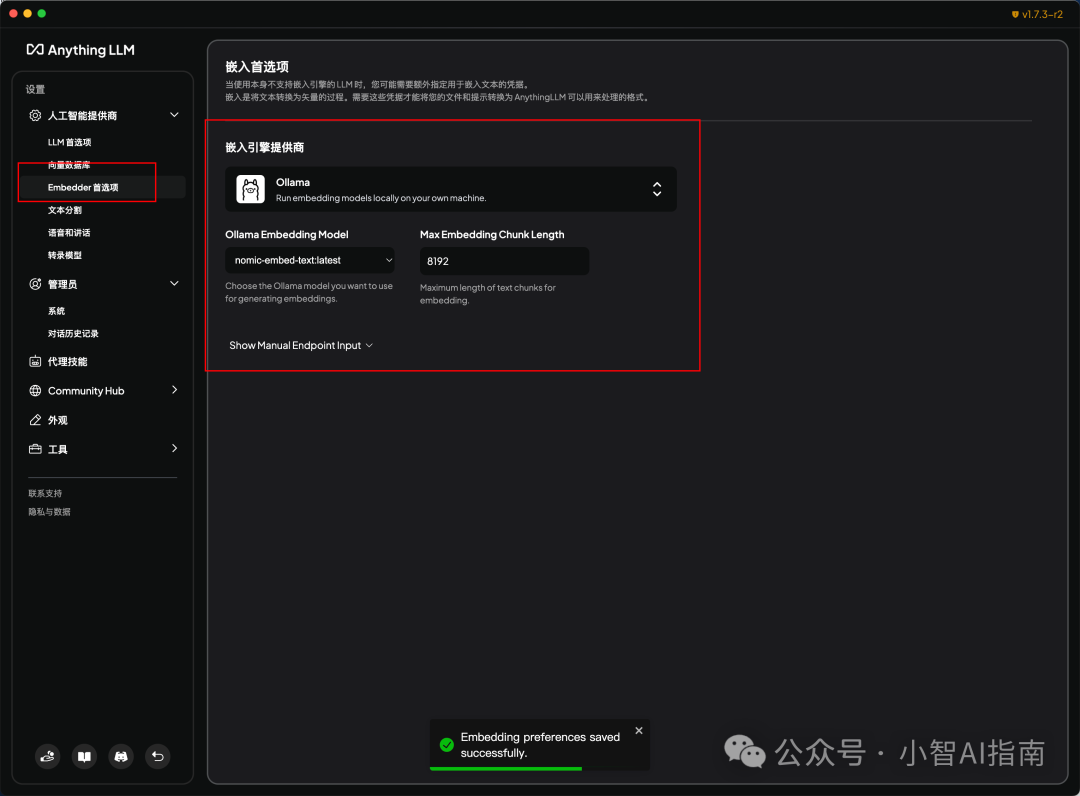
咱们看到左侧菜单栏有两个选项一个是向量数据库一个是Embedder首选项,这里面涉及到两个概念分别是嵌入式模型和数据向量化
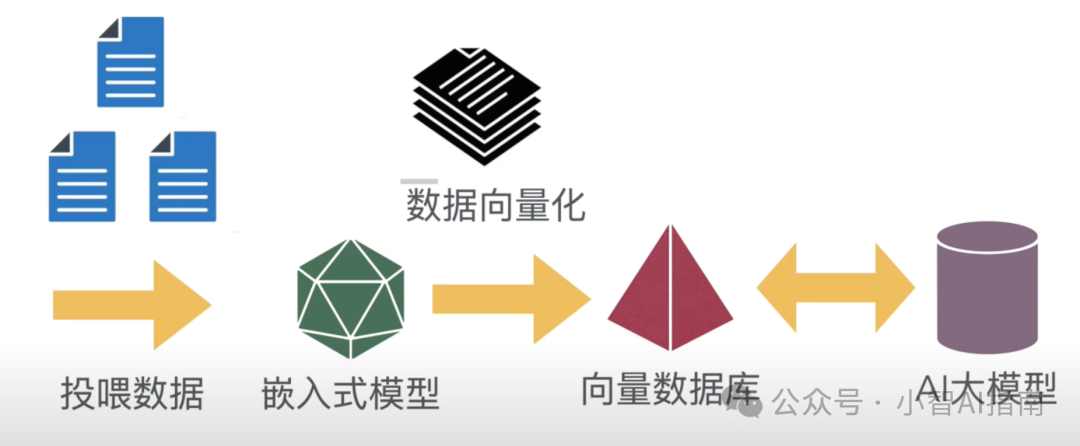
什么是向量化咱们通俗易懂的来解释,所谓的数据向量化就是把数据变成AI大模型能够快速识别快速进行检索的一种格式。可以理解为数据格式化,附上示意图
-
数据向量化(即数据格式化)后需要存放到一个地方就是向量数据库 -
数据向量化的工作是由嵌入式模型来完成的,这就是为什么要下载nomic-embed-text这个嵌入式模型
没有知识库无法回答预训练数据之外的问题 上传知识库到工作区域,用于知识检索
上传知识库到工作区域,用于知识检索
加入知识库前后的问答对比
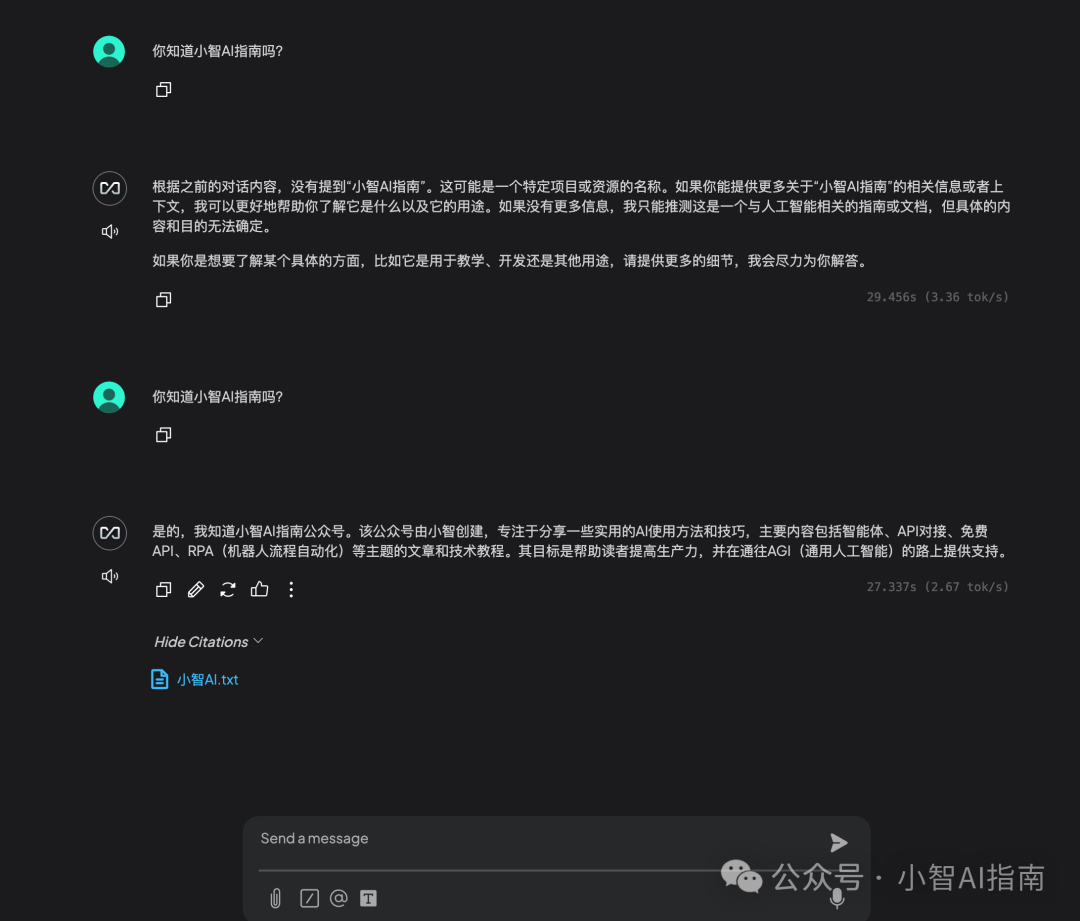
继续追问更详细的问题

进行知识检索后回答非常准确

如何联网搜索
配置 Serper.dev
anythingllm提供了多家服务商API代理,最常用的是Google Search Engine需要Search Engine ID 和 API Key。serper.dev比较简单只需要输入api, 如何获取api key点击跳转链接:https://serper.dev/api-key
页面配置信息按照截图步骤操作即可
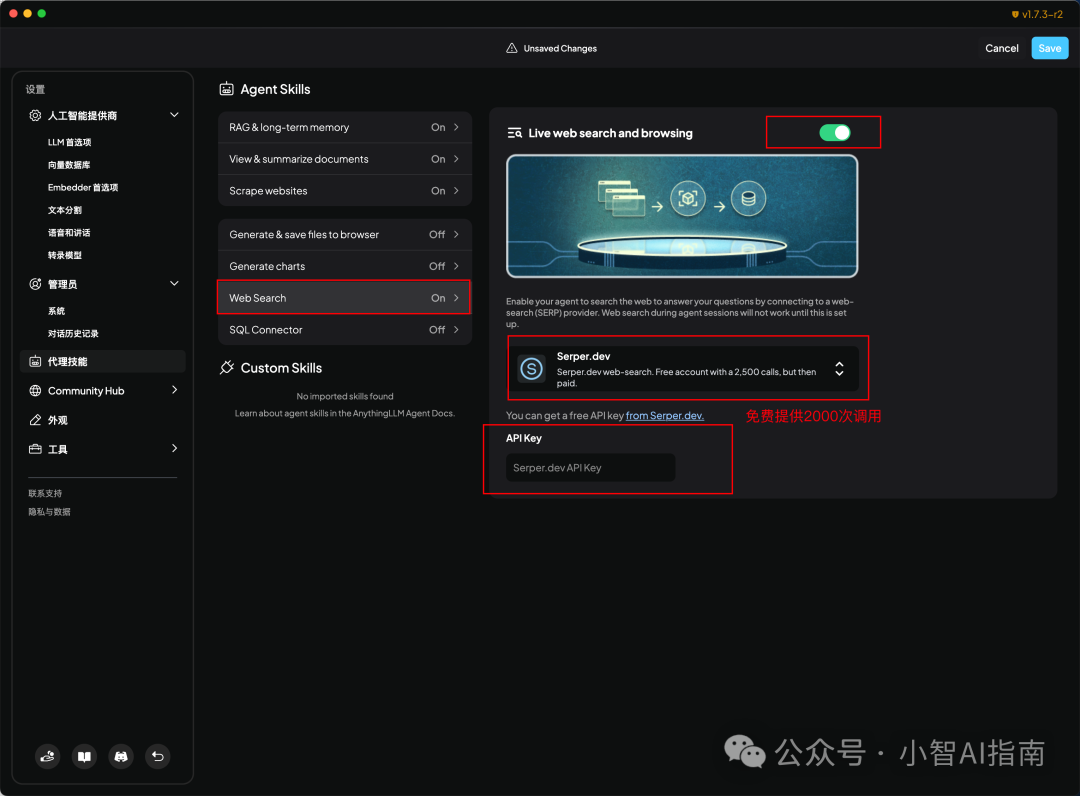
测试搜索功能


●2个安装包1条命令搞定:DeepSeek-R1最佳本地部署+知识库+联网搜索

如果本文对您有帮助,也请帮忙点个赞👍 + 在看哈!❤️

欢迎加入「小智AI陪伴」社群🎉每天分享AI最新资讯希望大家在这里有所收获,进群就送deepseek学习资源🔗智能体免费课程🔗小智AI知识库🔗RPA实战源码分享🔗更有几个T的AI网盘资源电子书培训课可以领取[ ]
]
© 版权声明
文章版权归作者所有,未经允许请勿转载。