DeepSeek R1 VS OpenAI o1,我真的要吹爆它

2008年起带领团队开展基于机器学习的全自动量化交易,并在2023年7月正式成立了DeepSeek,进军通用人工智能领域。值得注意的是,DeepSeek至今并未进行外部融资。这里有必要着重说一下量化交易。什么是量化交易

量化交易是一种通过数学模型和算法分析市场数据,自动执行买卖决策的交易方式。梁文锋带领团队利用机器学习等技术探索全自动量化交易,意味着他们通过计算机程序来预测市场走势并自动化执行交易决策。具体来说,量化交易将各种投资策略转化为数学公式,并将其编写成计算机程序。通过设定特定的条件,这些程序能够自动进行买入或卖出操作,比如当某一技术指标达到预设的阈值时,系统会立即执行交易。这种交易方式提高了效率,同时也减少了人为情绪对决策的干扰。量化交易不仅可以应用于股票市场,还可扩展到债券、外汇、期货以及衍生品市场等多个金融领域。其核心在于利用大量历史数据和复杂的统计模型,识别并利用市场中的微小定价偏差,从而实现稳定的收益增长。15年的历史数据训练加技术沉淀,deepseek的爆火可见并不是偶然的。咱们再直接的说一下它爆火的原因DeepSeek爆火原因主要归因于两大因素:性能和成本。DeepSeek-R1模型通过强化学习技术,在数据标注极少的情况下,显著提升了推理能力。出色的性能引发了科技界的高度关注,并吸引了投资者的目光,认为其具有巨大的商业潜力。以下是DeepSeek R1和OpenAI O1的对比(包含预训练成本和输入Tokens价格):
|
|
|
|
|---|---|---|
| 推理能力 |
|
|
| 联网搜索 |
|
|
| PDF阅读 |
|
|
| 过程公开性 |
|
|
| 开源情况 | 免费且开源 |
|
| 预训练成本 |
|
|
| 输入Tokens(每百万) |
|
|
总结:
-
DeepSeek R1在功能上更全面,支持联网搜索和PDF阅读,且过程全公开、免费开源,预训练成本低,输入Tokens价格也更优。 -
OpenAI O1虽然推理能力强,但不支持联网搜索和PDF阅读,过程未公开,预训练成本高,输入Tokens价格也较高,且不开源。
DeepSeek在预训练成本和部分API定价上具有显著优势,尤其是在缓存命中的情况下,输入Tokens的成本更低。约为OpenAI GPT-4运行成本的三十分之一。因此,DeepSeek被誉为AI行业的“拼多多”。技术原理对比DeepSeek R1DeepSeek R1的技术核心在于其创新的强化学习(RL)技术,这种技术使得模型在后训练阶段能够以极少的标注数据在数学、代码和自然语言推理等任务中表现出色。其训练过程包括纯强化学习训练、冷启动与多阶段训练以及模型蒸馏等几个关键环节。
-
纯强化学习训练:DeepSeek R1-Zero不依赖任何监督微调数据,仅通过强化学习实现推理能力的自主进化。采用Group Relative Policy Optimization(GRPO)算法,通过在组内进行奖励对比来优化策略,规避了传统强化学习对复杂价值模型的依赖。 -
冷启动与多阶段训练:为了克服纯RL训练可能带来的可读性不佳及多语言混杂问题,DeepSeek R1引入少量冷启动数据和多阶段训练流程。冷启动阶段通过高质量长推理链数据微调基础模型,提升输出可读性;强化学习阶段引入语言一致性奖励机制,优化数学、编程等任务表现。 -
模型蒸馏:支持将大模型的推理模式高效蒸馏至小模型,使得小模型在保持高效运行的同时具备强大推理能力,适用于资源有限的部署场景。
OpenAI o1OpenAI o1则通过增加思维链推理过程的长度,突破推理任务的瓶颈。在技术实现上,OpenAI o1高度依赖于监督微调和思维链推理(Chain-of-Thought, CoT)。
-
监督微调(SFT):依靠大量人工标注的监督数据进行微调,提升模型在特定任务上的表现。这种方式的局限性在于标注数据的质量和数量对模型性能影响较大。 -
思维链推理:通过延长推理过程,模型能够将复杂问题逐步分解,通过多步骤的逻辑推理解决问题,在复杂任务中展现出更高的效率。
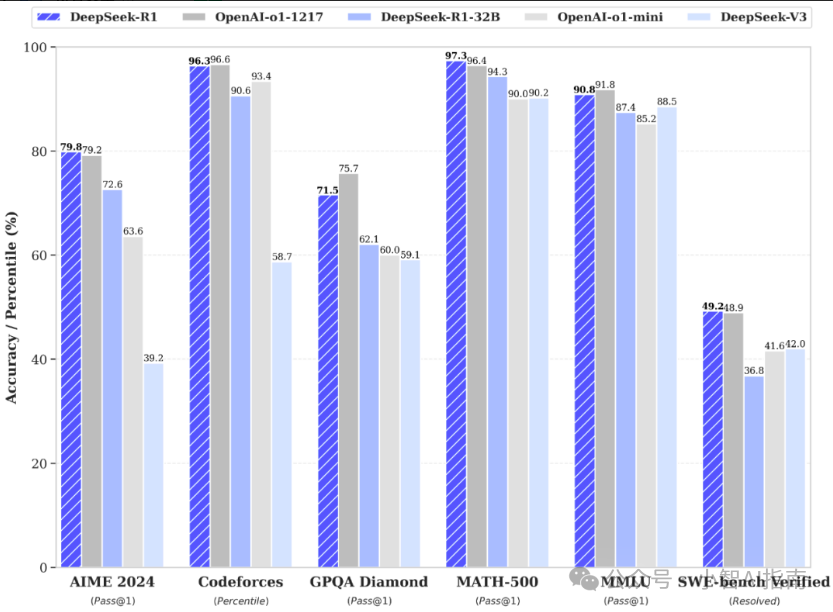
性能表现官方数据在后训练阶段,DeepSeek-R1大规模使用了强化学习技术,在极少标注数据的条件下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能与OpenAI o1正式版相当。
推理任务
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在数学任务中,DeepSeek R1在AIME 2024测试中以79.8%的Pass@1准确率超越OpenAI o1-1217的79.2%;在MATH-500任务中,DeepSeek R1达到97.3%的Pass@1准确率,与OpenAI o1-1217的96.8%相当。在编程任务中,DeepSeek R1在LiveCodeBench任务中取得65.9%的Pass@1准确率,高于OpenAI o1-1217的63.4%。知识密集型任务
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
在GPQA Diamond任务中,DeepSeek R1达到71.5%的Pass@1准确率,稍低于OpenAI o1-1217的75.7%。在SimpleQA任务中,DeepSeek R1的准确率为30.1%,低于OpenAI o1-1217的47.0%。通用能力
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
AlpacaEval 2.0任务中,DeepSeek R1达到87.6%的胜率,显著优于OpenAI o1-1217。在FRAMES任务中,DeepSeek R1的准确率达到82.5%,展现出强大的文档分析能力。价格对比
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|

-
问:DeepSeek R1预训练成本为什么这么低 -
DeepSeek R1支持将大模型的推理模式高效蒸馏至小模型,使得小模型在保持高效运行的同时具备强大推理能力。这种技术不仅提高了模型的部署效率,还进一步降低了运行成本。 -
DeepSeek R1的算法优化使其能够适配国产芯片架构,如华为昇腾。这种适配不仅降低了对进口高端芯片的依赖,还为模型的训练和部署提供了更多选择,进一步降低了成本。 -
问:在自然语言处理领域,DeepSeek R1和OpenAI o1有何不同? -
答:DeepSeek R1在自然语言理解、自动推理和语义分析等任务中表现突出,而OpenAI o1在自动问答和文本生成任务中表现优异。两者各有优势,适用场景有所不同。 -
问:DeepSeek开源对模型发展有何影响? -
答:开源策略使得开发者能够直接复现和改进模型,大大降低了技术创新的门槛。例如,DeepSeek R1开源了包括模型权重、训练细节和算法在内的全部内容,使得开发者可以直接在现有基础上进行二次开发。这种开放性促进了技术的快速迭代,例如开源模型在GitHub社区的贡献者数量和迭代速度均显著高于闭源模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。