分不清对不对!这个case我问了身边十几个朋友答案都是这个,但实际上,上面的镜头是GAGA-1用了不到五分钟就做出来的,而下面的镜头我用SoRa2跑了快半小时。跟Sora2每秒0.1刀的价格比起来,GAGA-1目前还是免费阶段。这价格成本和时间成本的区别一下子就出来了,关键表演这一块,GAGA-1也很有可圈可点之处。所以今天我就尝试用GAGA-1复刻经典镜头,并且从单人表演、多人表演以及多语种表演上一起看看GAGA-1的表现如何。
先来看看GAGA-1是怎么用的,其实和现在大家熟悉的用法一样,进入Gaga AI后,选择GAGA演员,直接上传图片,写好提示语就能可以生成了。目前是支持16:9尺寸的10s的图生视频,后续会上线更多。小提示,打开增强提示生成效果更好!
首先,来看单人表演,我先做了两个古装效果,这个配音、嘴形和动作很有古装片哪个味儿,嘴形也不夸张,没有张嘴180度之感,表情整体克制,不假大,尤其配音的停顿给我一种真的在思考的感觉,说是哪个古装片里截出来的一段我也是信的。
而且视频是包含完整的环境与动作音效一起生成的,音效不会抢拍不会非常突兀,直接就是一段完整可用的素材。然后我给了一些情绪的指示,呈现出来的效果声音和表情的情绪照样很对位,人物的微表情不会说有特别夸张或者让人很出戏的感觉,
再来看双人表演,这个是很厉害的一个地方,之前我们尝试过的要么是一个镜头只能有一个人说话,要么就是要靠剪辑才能让两个人进行对话,或者就是用S2,但现在GAGA-1也给我们提供了一个解决方案。下面这两个镜头,也是通过提示语描述人物说话的内容,就能直接做出两个人对话场景。而且人物是有世界逻辑的,他们知道在说到什么内容时做出什么动作,比如知道和对方说话要转头,两人的嘴型能在交谈点同步,不会一个人在说话时另一个嘴动,或者一个说完之后很久另一个人才开始说话,同时眼神互动、头部微转、沉默时停顿,都处理得有节奏,这就让整个人物看起来行为更有逻辑,也让画面更加真实。
现在,我只期待一个可以指定多个角色的音色,并且在多个视频中能够持续保持音色的一致性,这样离影视级的多集剧制作就更近了一步。目前GAGA-1支持多个语种,生成效果上可以说都能实现母语级的口型匹配与真实情感,我做了一个中、英、日、韩、法语的镜头合集,大家可以感受一下这个效果,我目前是觉得还比较自然,很有电视剧质感。
目前实测下来,偏写实风格和CG的风格的动态效果会更好,一些动画风格还需要等待后续工具迭代,不过我还是很期待GAGA-1这方面能力也提升之后的效果,那我不是直接可以手搓番剧了?
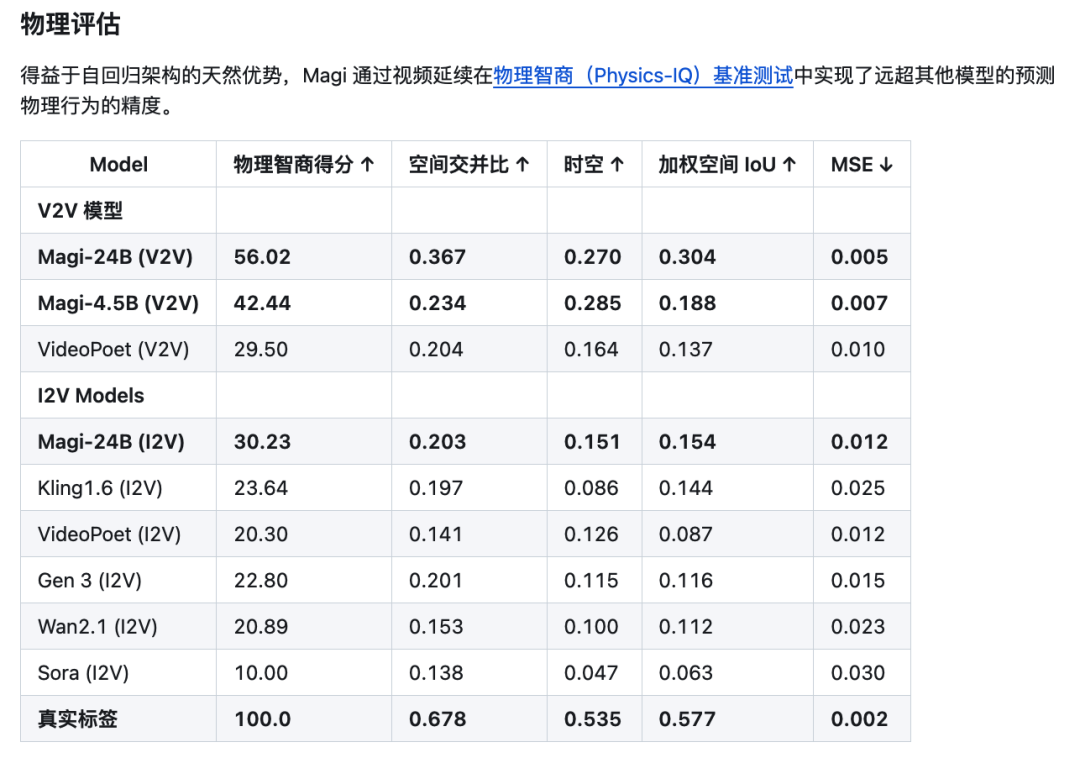
说了这么多,最后聊聊GAGA-1是哪个团队做的。半年前首个高质量自回归视频模型Magi-1就是他们做的,DiT 路线(比如之前的Sora),是一次性把整段视频并行跑出来的,没有明确的先后逻辑,时间感和因果就容易跑偏。而 Magi-1 它是把视频切成一小段一小段(比如 24 帧≈1 秒),上一段先出结果,下一段再基于它往下接,保证了时间顺序的因果关系。理论上没有时长上限,能一直续写,还可以“逐秒控制”,想让啥时候发生啥就啥时候发生。
创始人是曹越,经历有点过于豪华,清华特等奖学金、ICCV 马尔奖(Marr Prize)、Swin Transformer 共同一作、博士毕业后加入微软亚洲研究院,后任智源研究院视觉中心负责人。说对了说多了,321,视角拉回来这次的GAGA-1,我觉得以后看视频真的需要标注哪些是“真人出演”,哪些是“AI出演”,甚至哪些是“真人生成”, 甚至还有可能出现“真人演员”和“AI演员”的区分,现在好莱坞的AI演员今年不也出道第N次了。
演员缇丽·诺伍德(Tilly Norwood),由人工智能制作公司Particle6旗下的人才工作室Xicoia开发,是世界上第一个虚拟职业演员。真的每次看到这种领域上的大版本更新迭代,都非常兴奋,超级无敌炒鸡蛋想大喊一句,卷起来啊,S2白菜价,Veo3白菜价,GAGA-1白菜价,通通白菜价,我想在家看可互动实时渲染的全AI的超级电影,配上我新买的vision pro,美zizi。
@ 作者 / 卡尔 & 阿汤
© 版权声明
文章版权归作者所有,未经允许请勿转载。