


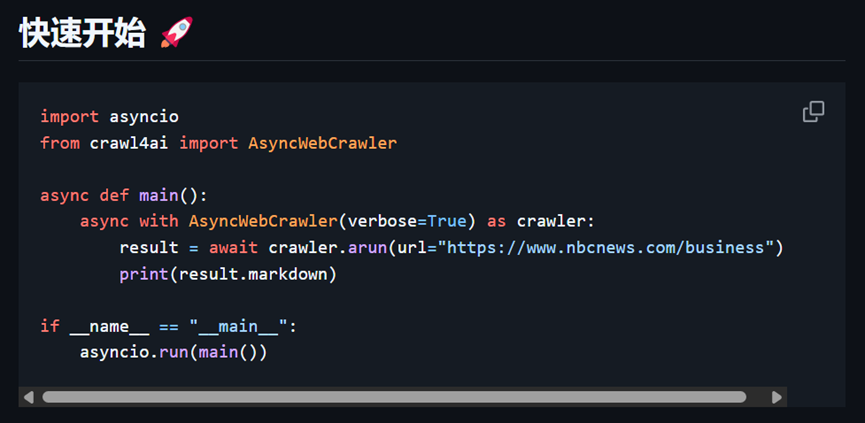


import jsonimport asynciofrom crawl4ai import AsyncWebCrawlerfrom crawl4ai.extraction_strategy import JsonCssExtractionStrategy
async def extract_ai_news_article(): print("
--- 使用 JsonCssExtractionStrategy 提取 AIbase 新闻文章数据 ---")
# 定义提取 schema schema = { "name": "AIbase News Article", "baseSelector": "div.pb-32", # 主容器的 CSS 选择器 "fields": [ { "name": "title", "selector": "h1", "type": "text", }, { "name": "publication_date", "selector": "div.flex.flex-col > div.flex.flex-wrap > span:nth-child(6)", "type": "text", }, { "name": "content", "selector": "div.post-content", "type": "text", }, ], }
# 创建提取策略 extraction_strategy = JsonCssExtractionStrategy(schema, verbose=True)
# 使用 AsyncWebCrawler 进行爬取 async with AsyncWebCrawler(verbose=True) as crawler: result = await crawler.arun( url="https://www.aibase.com/zh/news/12386", # 替换为实际的目标 URL extraction_strategy=extraction_strategy, bypass_cache=True, # 忽略缓存,确保获取最新内容 )
if not result.success: print("页面爬取失败") return
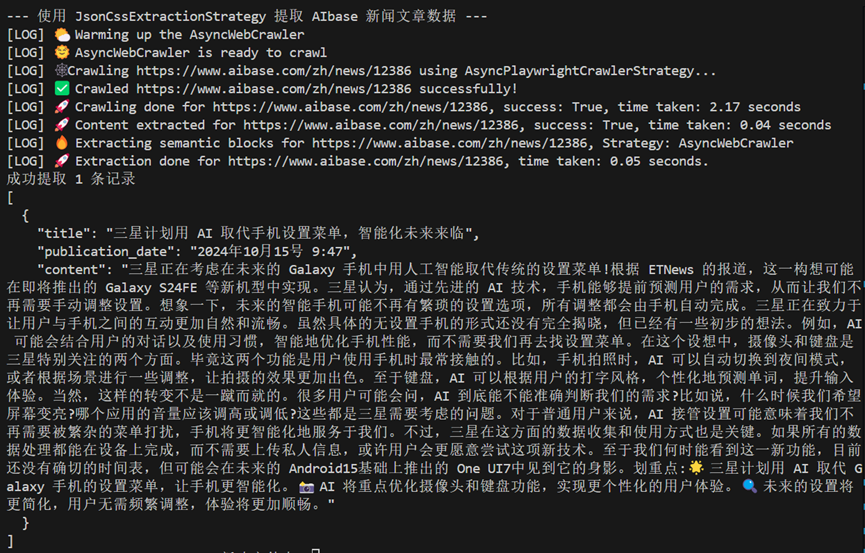
# 解析提取的内容 extracted_data = json.loads(result.extracted_content) print(f"成功提取 {len(extracted_data)} 条记录") print(json.dumps(extracted_data, indent=2, ensure_ascii=False))
return extracted_data
# 运行异步函数if __name__ == "__main__": asyncio.run(extract_ai_news_article())


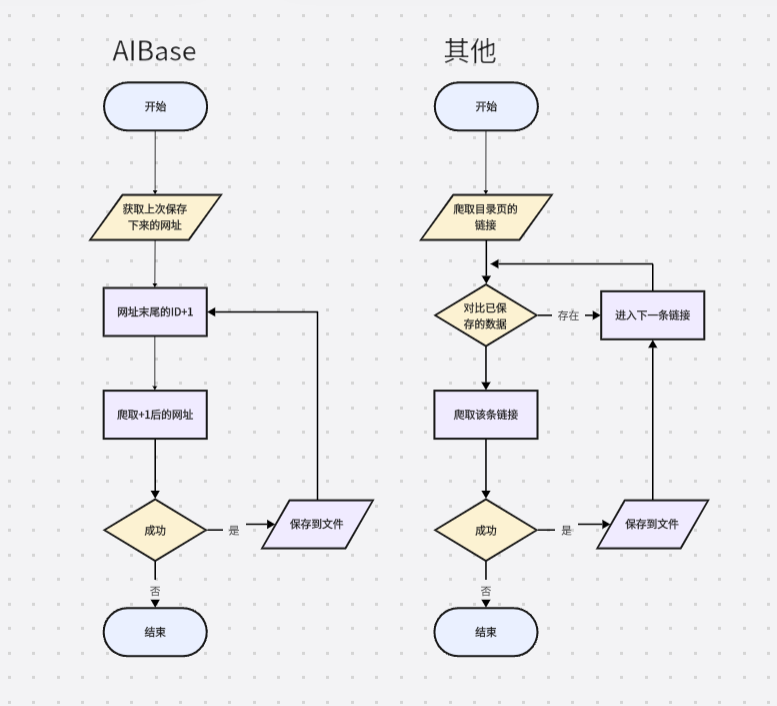

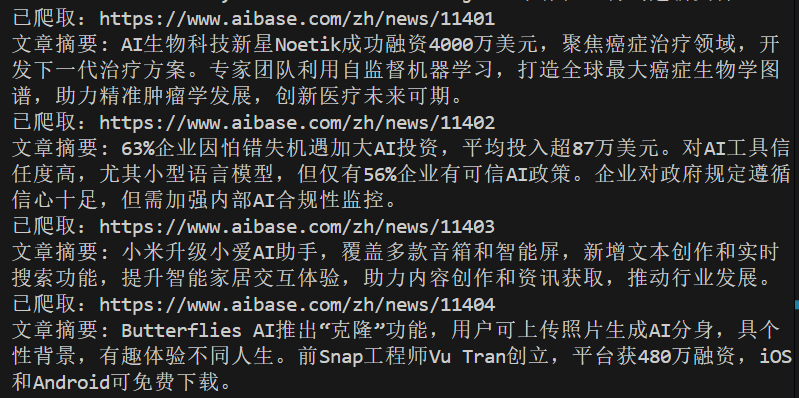

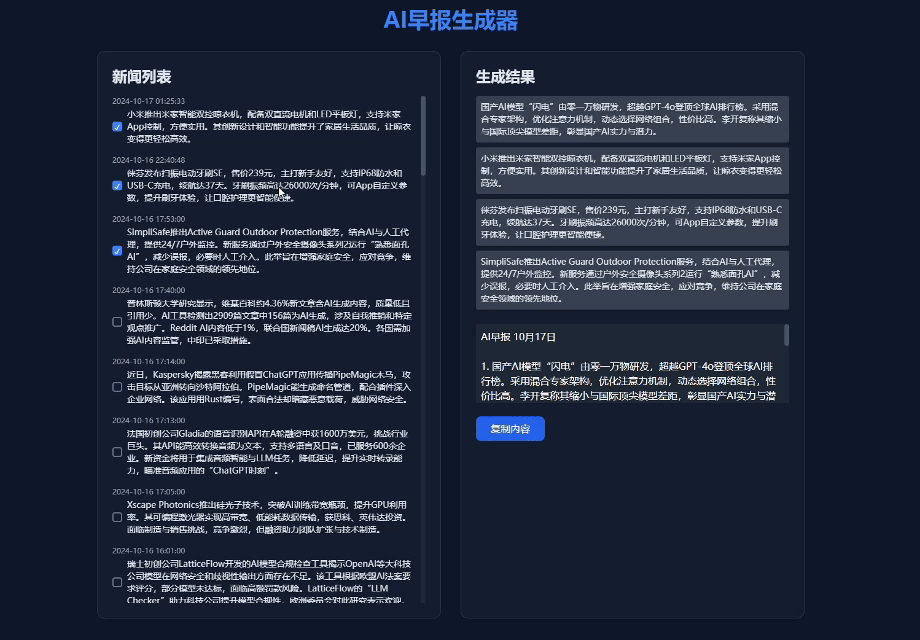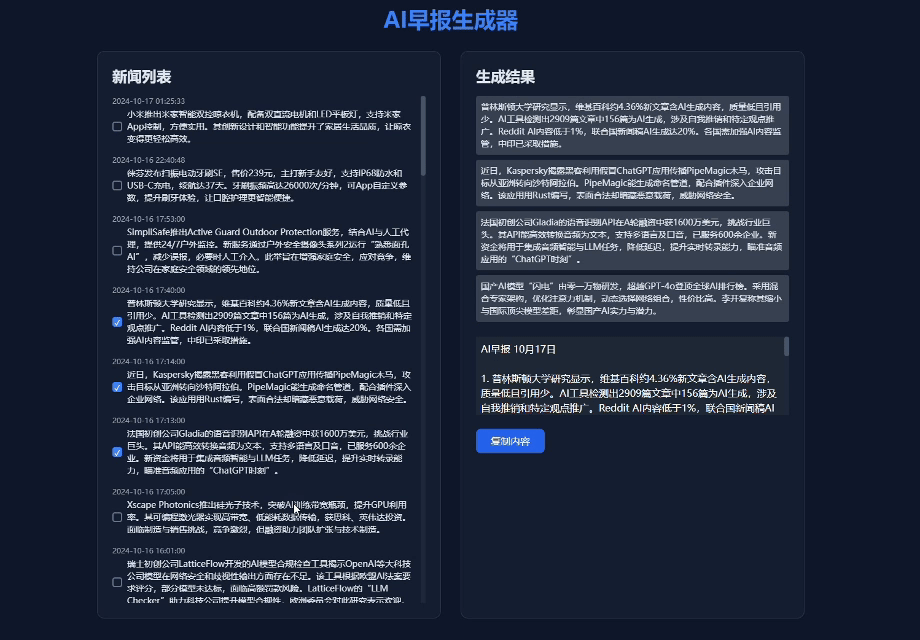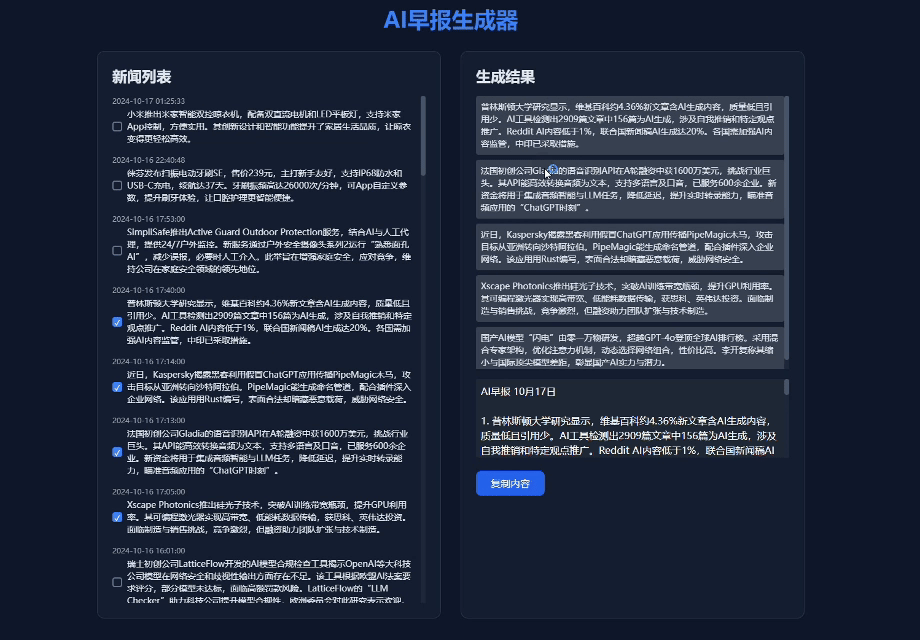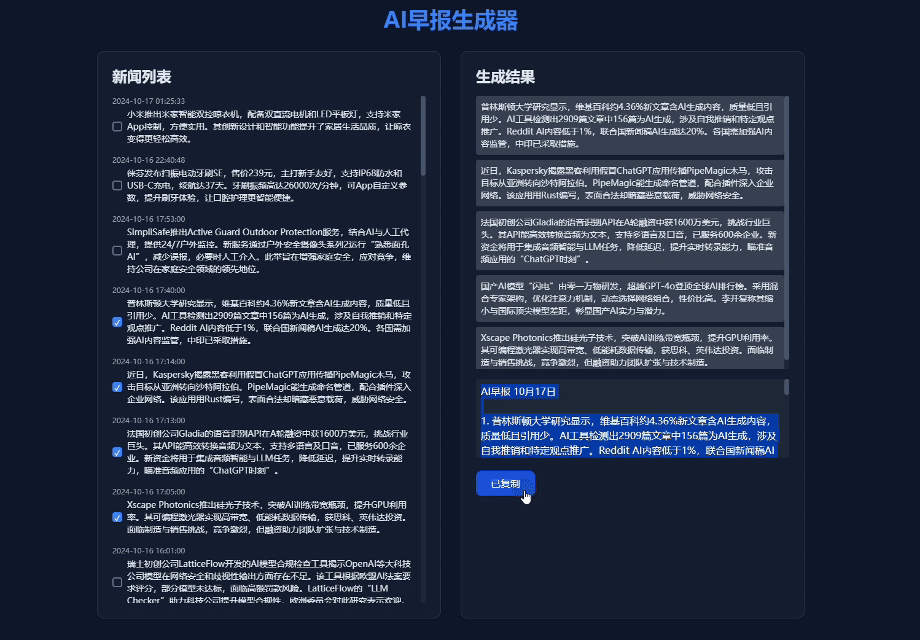
© 版权声明
文章版权归作者所有,未经允许请勿转载。