
逛 GitHub 挖到宝了,这个叫UltraRAG 的开源项目是首个基于 MCP 的检索增强生成(RAG)框架,不写代码也能玩转。用 YAML 文件轻松构建复杂 RAG 系统。RAG 系统:简单来说,就是让 AI 模型能先检索相关信息,再生成答案,从而提高准确性。

UltraRAG 是由清华 THUNLP、东北大学 NEUIR、OpenBMB 等多方联合推出的开源项目。它能让你更容易构建和测试复杂的 RAG 系统。01开源项目简介
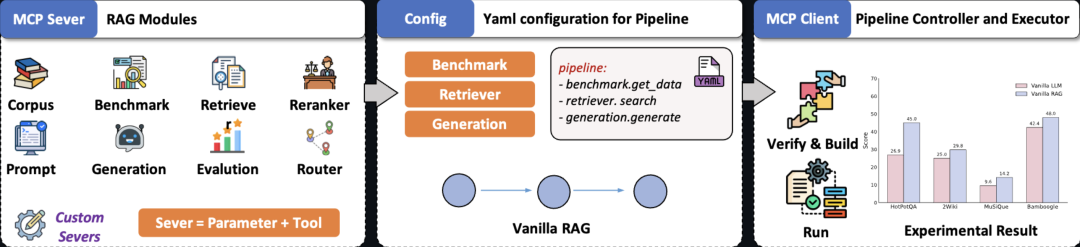
新版版本升级,最新的 2.1 版本主要围绕以下三大核心方向进行了全面升级:① 原生多模态统一框架支持文本、图像的检索与生成,新增 VisRAG Pipeline 实现PDF 到多模态问答的闭环。而且内置的多模态 Benchmark 覆盖视觉问答等任务,并提供统一的评估体系,方便研究者快速对比实验效果。② 知识接入与语料构建自动化支持多格式文档,比如 Word、电子书、网页存档的自动解析与分块,不需要编写复杂脚本即可构建统一格式的知识库。而且在 PDF 解析方面,它集成了MinerU 工具,能高保真还原复杂版面与多栏结构,并支持将 PDF 按页转换为图像,保留视觉布局信息。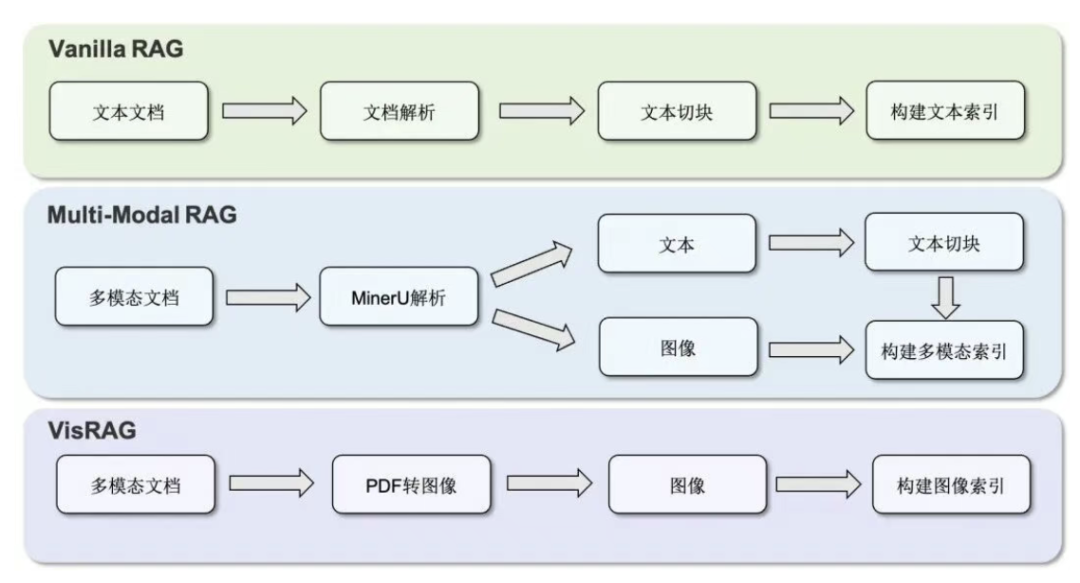
③ 统一工作流通过 YAML 配置驱动检索、生成、评估全流程,支持多种引擎与可视化分析,提升实验复现效率。
开源项目链接和相关教程如下:
代码仓库:https://github.com/OpenBMB/UltraRAG教程文档:https://ultrarag.openbmb.cn/数据集:https://modelscope.cn/datasets/UltraRAG/UltraRAG_Benchmark
02实际效果


03如何使用UltraRAG 支持两种部署方式,第一种是使用 Conda 创建虚拟环境:
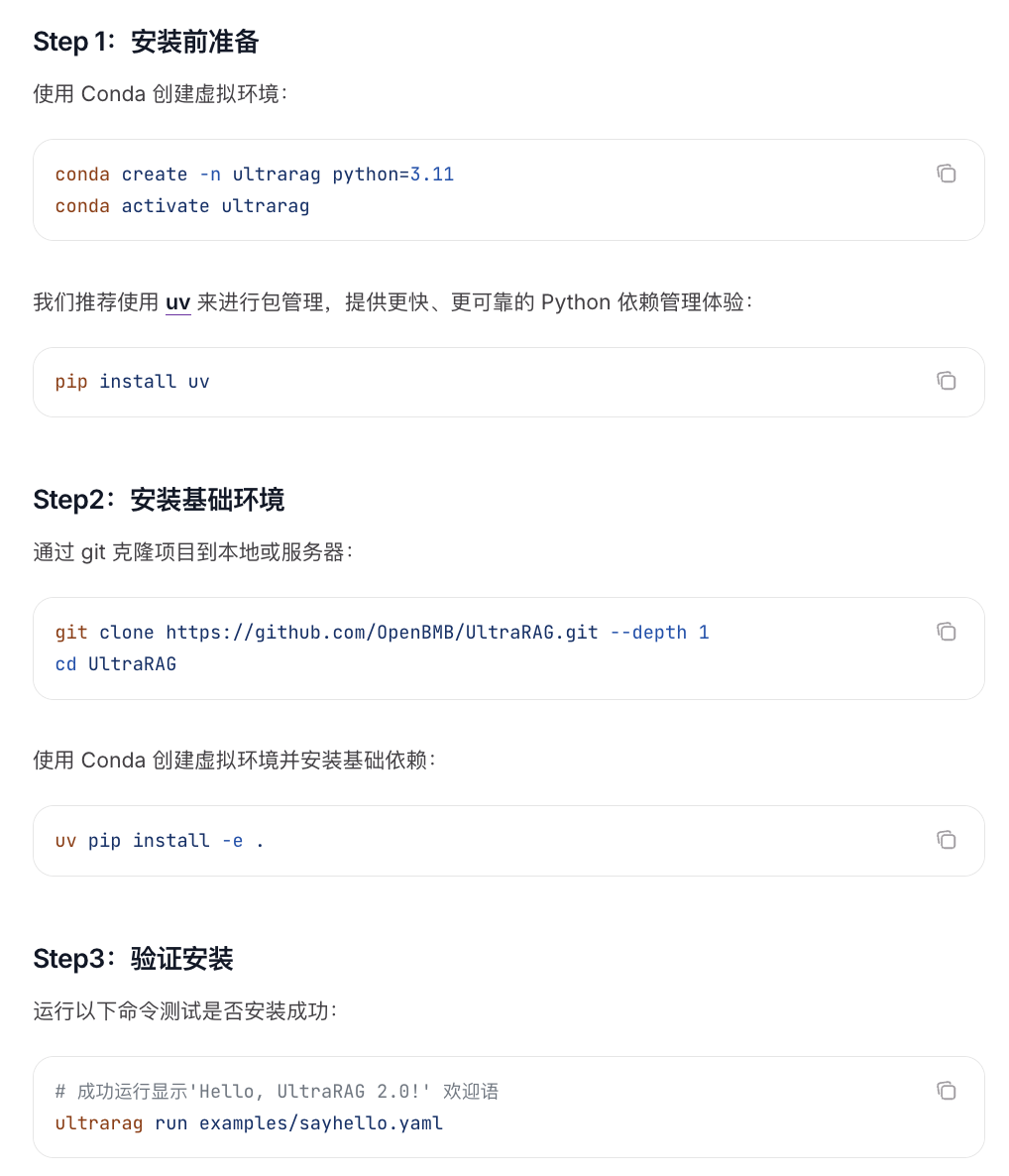

-
编写 Pipeline 配置文件 -
编译 Pipeline 并调整参数 -
运行 Pipeline
https://ultrarag.openbmb.cn/pages/cn/getting_started/quick_start
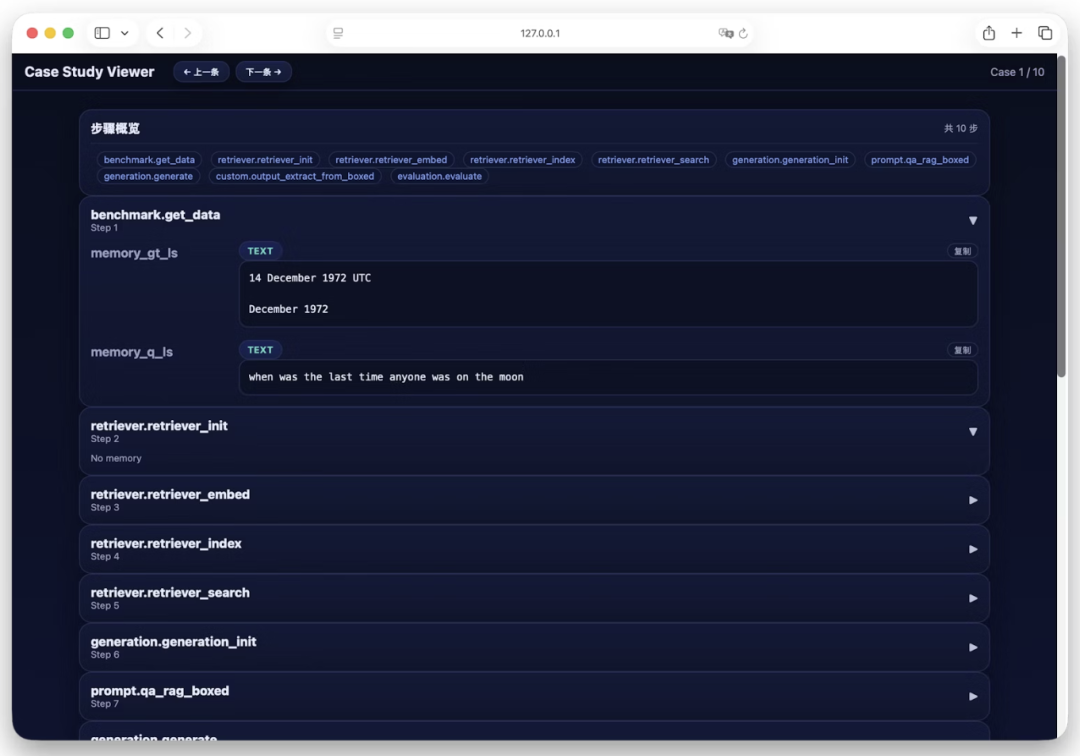
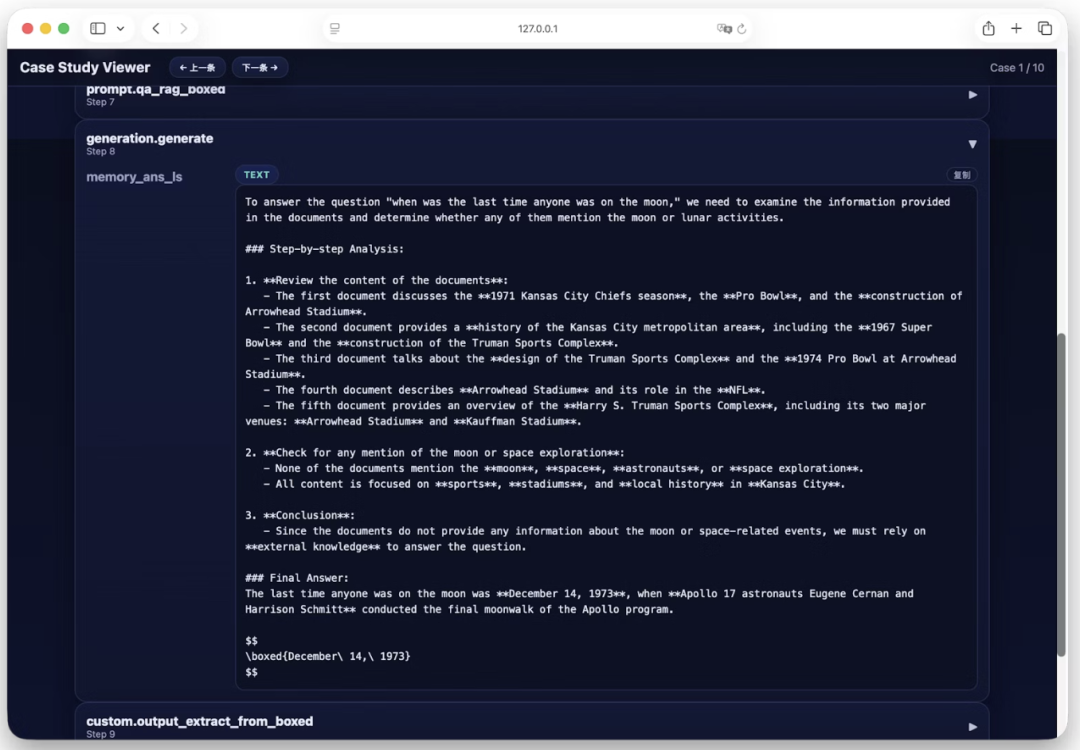
04点击下方卡片,关注逛逛 GitHub
© 版权声明
文章版权归作者所有,未经允许请勿转载。