大家好,我是焦哥。零代码基础手搓工作流,专注于AI智能体工作流的搭建知识分享。
早就想搞一个英语单词跟读视频的工作流,但一直被两个“拦路虎”劝退:一是卡片设计太耗时,找素材排版头都大;二是视频剪辑太折磨,特别是那个“读到哪、亮到哪”的高亮效果,手动去对简直是“坐牢”。直到看到了一个“骚操作”:
利用 HTML 代码循环高亮 + 视频自动拼接!这一下全解决了:颜值顶:12宫格、思维导图等 4 种风格随意切,张张都是海报级。全自动:扔个主题(比如水果),自动提取单词、生成语音。免剪辑:最爽的是,它能自动把音画同步好,直接吐出成品视频!可量产:从素材到成片,几分钟搞定,纯纯的流量收割机。这套“输入即成品”的玩法,你确定不心动?赶紧跟我一起动手搭建吧!
先看下效果
工作流原理
-
1.利用大模型生成一个漂亮的英文单词卡片,用html代码展示,再转成图片; -
2.把每个单词都提取出来,通过循环高亮处理,加上音频,合成一个小视频,最后再拼接成完整的视频。
工作流总览

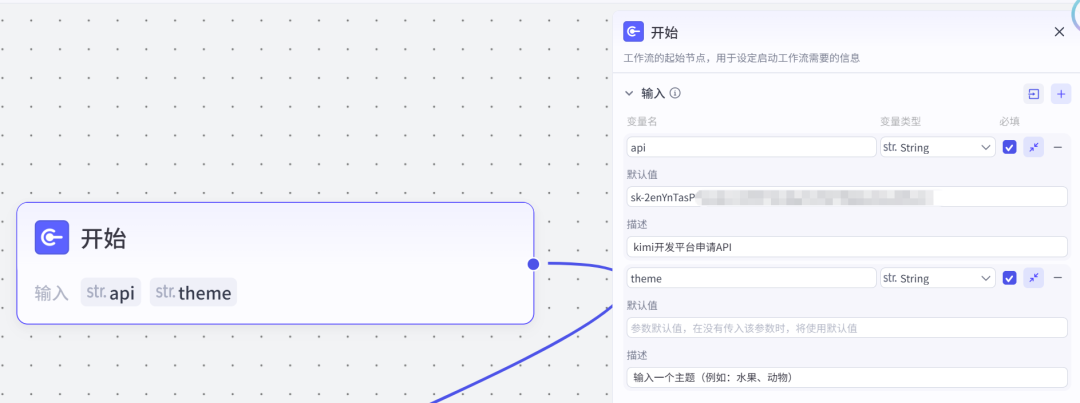
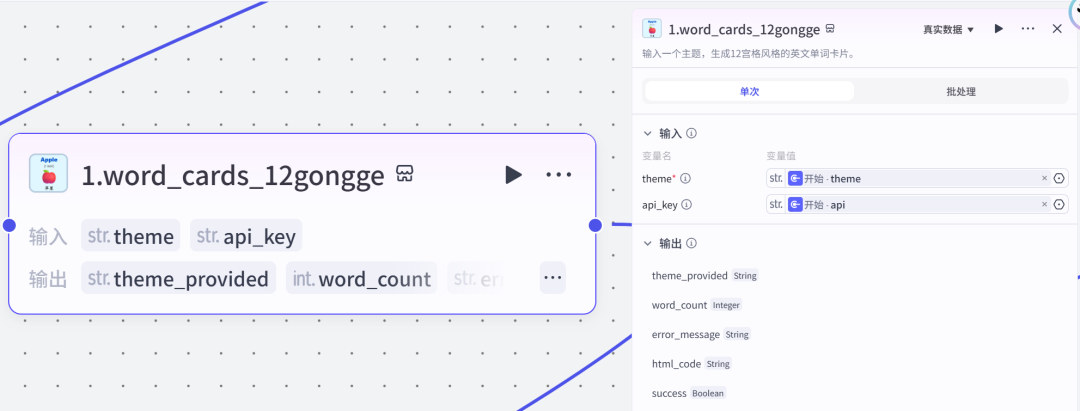
工作流节点开始节点theme:输入个主题,例如:水果、动物、蔬菜等。api:kimi的官方API(下一步的插件需要用到),申请地址:https://platform.moonshot.cn/console/account
插件节点这里用到焦哥开发的这个插件【word_cards】,英文单词卡片,输出为html代码,若需转为图片,可借助html_to_png插件。地址:https://www.coze.cn/store/plugin/7573726791500840994
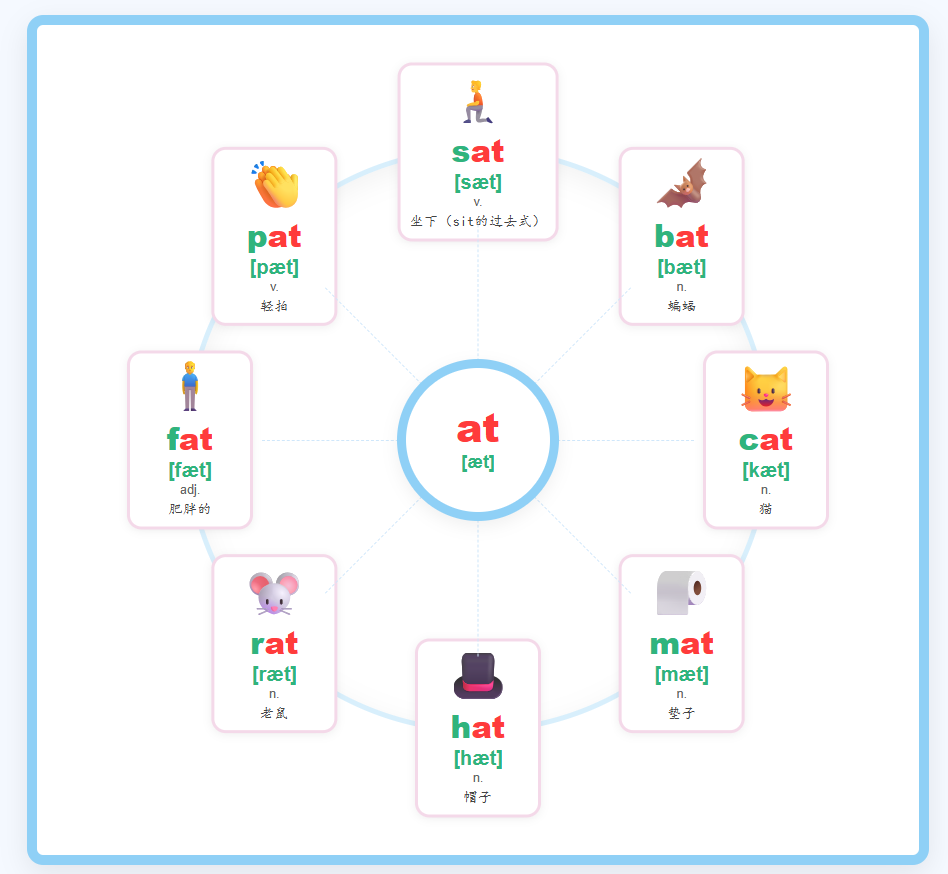
有四种风格:word cards_12gongge:输入一个主题,生成12宫格风格的英文单词卡片。word cards surround:输入一个音节,生成 金星环绕 风格的英文单词卡片。word_cards_mind:输入一个音节,生成 思维导图 风格的英文单词卡片。word_cards_9gongge:输入一个主题,生成9宫格风格的英文单词卡片。图片预览:

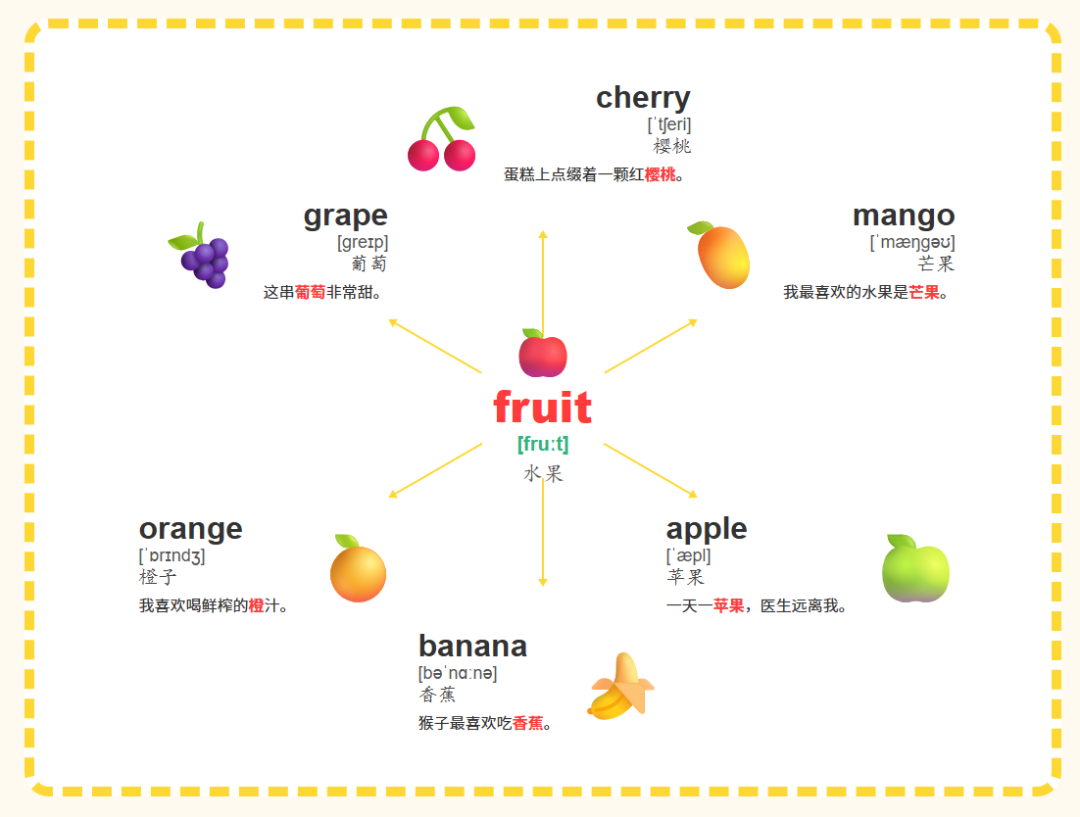
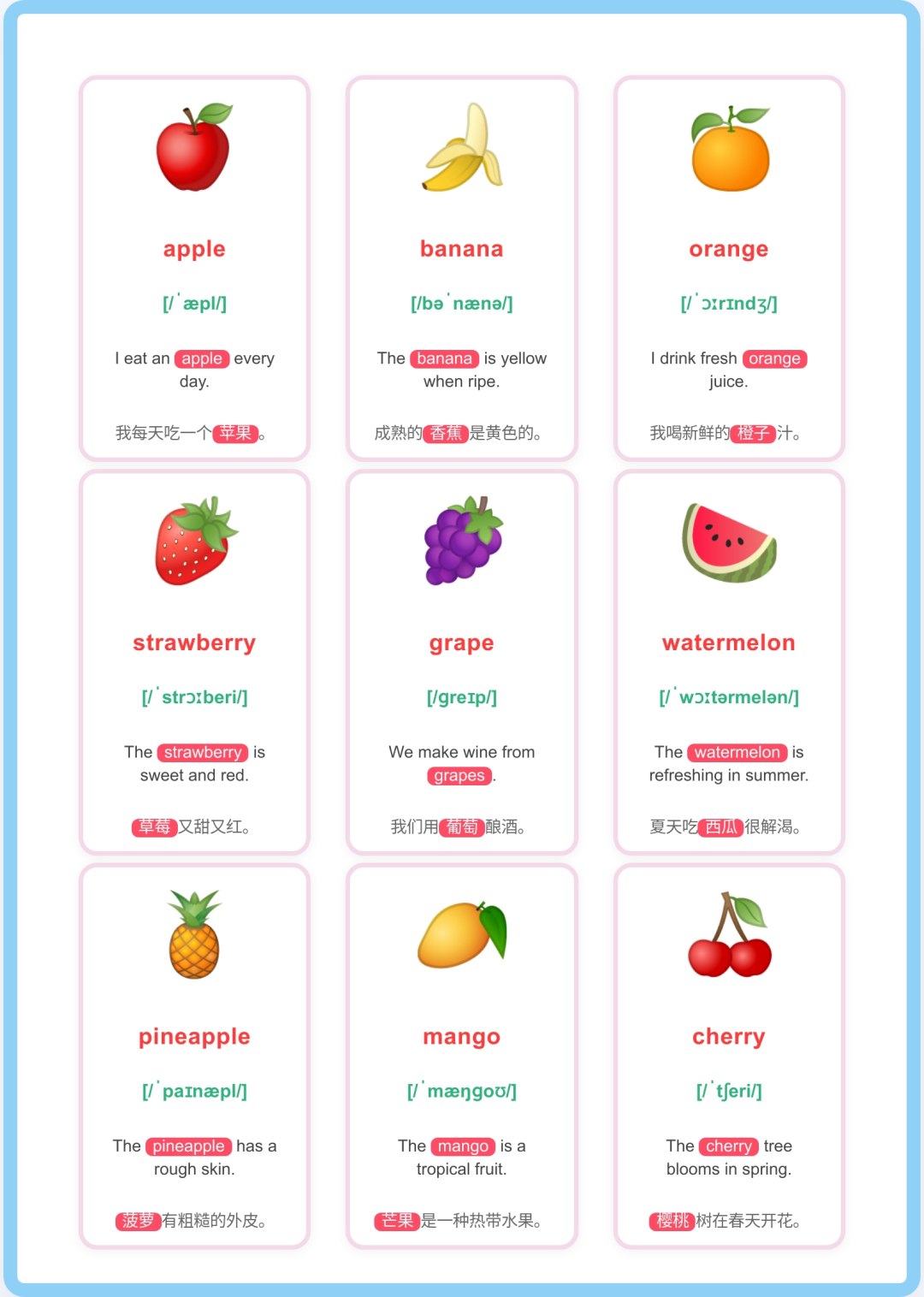
每种风格都可以制作出不错的跟读视频,下面的是我们用12宫格制作出一篇卡片跟读视频。
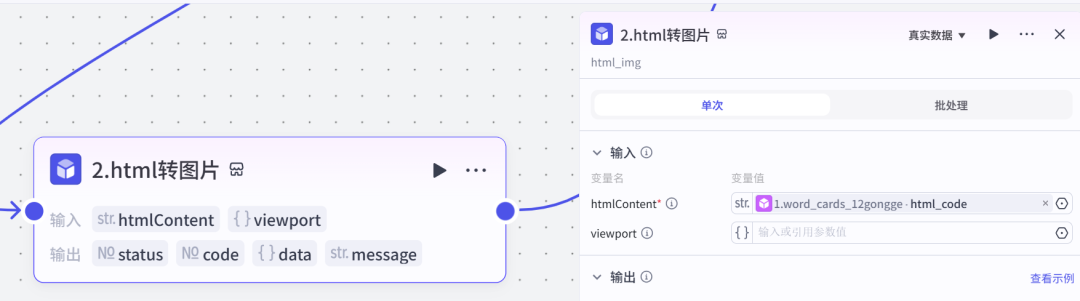
插件节点把上一步的html代码,转成图片
代码节点(提取单词)利用代码,把卡片的所有的单词都提取出来,用来生成音频。
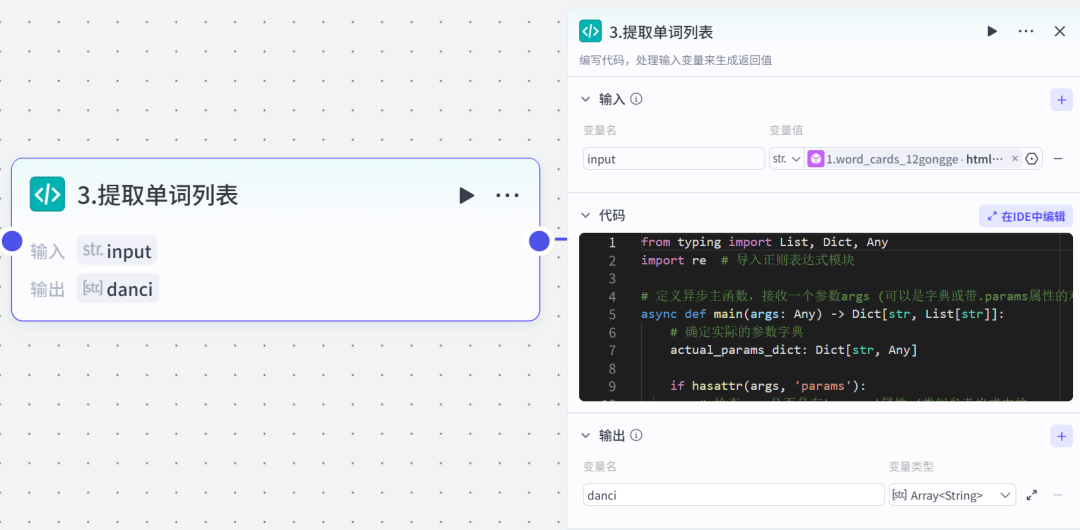
pyrhon代码
fromtypingimportList,Dict,Any
importre # 导入正则表达式模块
# 定义异步主函数,接收一个参数args (可以是字典或带.params属性的对象),并返回一个字典类型的结果
asyncdefmain(args:Any) ->Dict[str,List[str]]:
# 确定实际的参数字典
actual_params_dict:Dict[str,Any]
ifhasattr(args,'params'):
# 检查args是否具有'params'属性 (类似参考格式中的args.params)
params_attr =getattr(args,'params')
ifisinstance(params_attr,dict):
actual_params_dict = params_attr # args.params 是一个字典
else:
# args.params 存在但不是字典,这是一种意外情况
# 默认为空字典以避免后续错误。
actual_params_dict = {}
elifisinstance(args,dict):
# args 本身是一个字典
# 尝试获取args['params'],如果不存在,则假定args本身就是参数字典
actual_params_dict = args.get("params", args)
else:
# args 既不是带有.params属性的对象,也不是字典。这是不支持的格式。
# 默认为空字典以避免后续错误。
actual_params_dict = {}
# 从 actual_params_dict 中获取input输入,如果不存在则默认为空字符串
html_content:str= actual_params_dict.get("input","") # 获取HTML输入内容
# 初始化用于存储提取到的英文单词及中文意思的列表
word_pairs:List[str] = [] # 存储"英文,中文"格式的字符串
# 正则表达式1:匹配HTML中的英文单词和中文意思(处理
apple 苹果
格式)
# 使用更宽松的模式匹配中文内容
pattern1 = re.compile(r']*>([a-zA-Z][a-zA-Z\s-]*)\s+([\s\S]*?)]*>')
# 正则表达式2:匹配英文/音标/中文格式(处理apple/ˈæpl/苹果格式)
# 修改后的模式能更好处理各种字符
pattern2 = re.compile(r'^([a-zA-Z][a-zA-Z\s-]*)(?:\s*/[^/]*/\s*|\s+)(.*)$')
# 正则表达式3:匹配HTML中的表格格式(处理
apple
苹果
格式)
# 使用更宽松的模式匹配中文内容
pattern3 = re.compile(r'
]*>\s*([a-zA-Z][a-zA-Z\s-]*)\s*
\s*
]*>\s*([\s\S]*?)\s*
')
# 正则表达式4:匹配12宫格HTML格式(处理
Lion
狮子
格式)
pattern4 = re.compile(r'
([^<]+)
[\s\S]*?
([^<]+)
')
# 方法0:优先尝试匹配12宫格HTML格式
matches0 = pattern4.findall(html_content)
forenglish, chineseinmatches0:
english = english.strip() # 去除英文单词前后空白
chinese = chinese.strip() # 去除中文意思前后空白
ifenglishandchinese: # 确保两个部分都不为空
word_pairs.append(f"{english},{chinese}") # 格式化为"英文,中文"格式
# 方法1:如果方法0没有找到内容,尝试匹配HTML列表项格式
ifnotword_pairs:
matches1 = pattern1.findall(html_content)
forenglish, chineseinmatches1:
english = english.strip() # 去除英文单词前后空白
chinese = chinese.strip() # 去除中文意思前后空白
ifenglishandchineseandnotchinese.startswith('{'): # 确保两个部分都不为空,且中文不是残缺的
word_pairs.append(f"{english},{chinese}") # 格式化为"英文,中文"格式
# 方法2:如果方法1没有找到内容,尝试匹配普通文本格式
ifnotword_pairs:
# 按行分割HTML内容
lines = re.split(r'
|
', html_content) # 支持
标签和换行符分割
forlineinlines:
line = re.sub(r']*>','', line).strip() # 去除HTML标签并去除前后空白
ifnotline: # 如果是空行,跳过
continue
# 尝试匹配英文/音标/中文格式
match2 = pattern2.match(line)
ifmatch2:
english = match2.group(1).strip() # 提取英文单词
chinese = match2.group(2).strip() # 提取中文意思
ifchineseandnotchinese.startswith('{'): # 确保中文内容完整
word_pairs.append(f"{english},{chinese}") # 格式化为"英文,中文"格式
else:
# 尝试简单的英文+中文格式(空格分隔)
simple_match = re.match(r'^([a-zA-Z][a-zA-Z\s-]*)\s+(.+)$', line)
ifsimple_match:
english = simple_match.group(1).strip() # 提取英文单词
chinese = simple_match.group(2).strip() # 提取中文意思
ifchineseandnotchinese.startswith('{'): # 确保中文内容完整
word_pairs.append(f"{english},{chinese}") # 格式化为"英文,中文"格式
# 方法3:如果前两种方法都没有找到,尝试匹配HTML表格格式
ifnotword_pairs:
matches3 = pattern3.findall(html_content)
forenglish, chineseinmatches3:
english = english.strip() # 去除英文单词前后空白
chinese = chinese.strip() # 去除中文意思前后空白
ifenglishandchineseandnotchinese.startswith('{'): # 确保两个部分都不为空,且中文完整
word_pairs.append(f"{english},{chinese}") # 格式化为"英文,中文"格式
# 方法4:特殊处理 - 如果检测到可能是JSON格式的一部分,尝试清理
ifnotword_pairsandhtml_content.strip().startswith('{'):
# 清理JSON格式残留
cleaned_content = re.sub(r'^[^{]*{\s*"[^"]*"\s*:\s*','', html_content)
cleaned_content = re.sub(r'\s*}\s*$','', cleaned_content)
# 重新处理方法1
matches1 = pattern1.findall(cleaned_content)
forenglish, chineseinmatches1:
english = english.strip()
chinese = chinese.strip()
ifenglishandchineseandlen(chinese) >1: # 确保中文内容完整
word_pairs.append(f"{english},{chinese}")
# 去除重复的单词对(保持顺序)
seen =set() # 用于记录已经处理过的单词对
unique_word_pairs:List[str] = [] # 存储去重后的结果
forpairinword_pairs:
ifpairnotinseen: # 如果这个单词对还没有处理过
seen.add(pair) # 添加到已处理集合
unique_word_pairs.append(pair) # 添加到结果列表
# 输出提取统计信息(可选,调试用)
ifunique_word_pairs:
print(f"成功提取到{len(unique_word_pairs)}个单词对") # 输出成功提取的单词数量
# 打印前几个结果用于调试
fori, pairinenumerate(unique_word_pairs[:3]):
print(f" 单词对{i+1}:{pair}")
else:
print("警告:未能从HTML内容中提取到任何单词对") # 输出提取失败警告
print("支持的格式包括:") # 输出支持的格式提示
print("1.
apple 苹果
") # HTML列表格式
print("2. apple/ˈæpl/苹果") # 斜杠分隔格式
print("3.
apple
苹果
") # HTML表格格式
print("4. apple 苹果") # 简单空格分隔格式
# 构建包含提取结果的返回字典
ret:Dict[str,List[str]] = {
"danci": unique_word_pairs # 返回提取到的"英文,中文"格式单词对列表
}
returnret # 返回构建好的结果字典
# 如果直接运行此文件,执行测试
if__name__ =="__main__":
importasyncio
asyncio.run(test())
批处理节点这一步主要就是批量处理每一个单词,生成音频→单词高亮显示→重新生成卡片→图片加音频合成单个小视频。注意:并行运行数量,焦哥通过多次测试,设置为2,输出的效果是最稳定的。
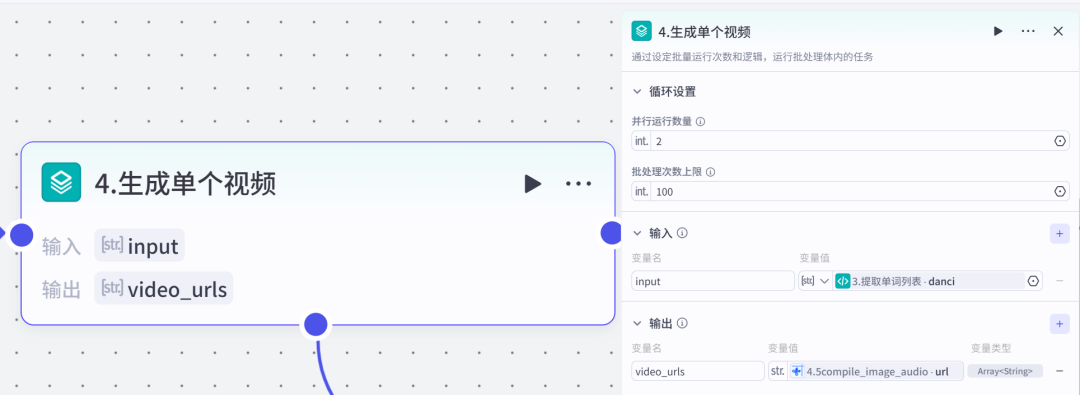
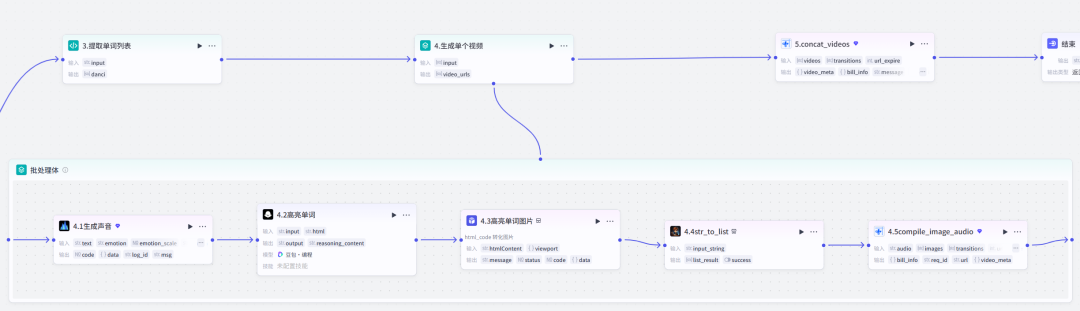
4.1节点:文本生成语音4.2节点:html代码转图片4.3节点:字符串转列表以上都是我们的老朋友了,就不多赘述了。4.2节点:把循环到的每一个单词在html代码中都高亮显示。
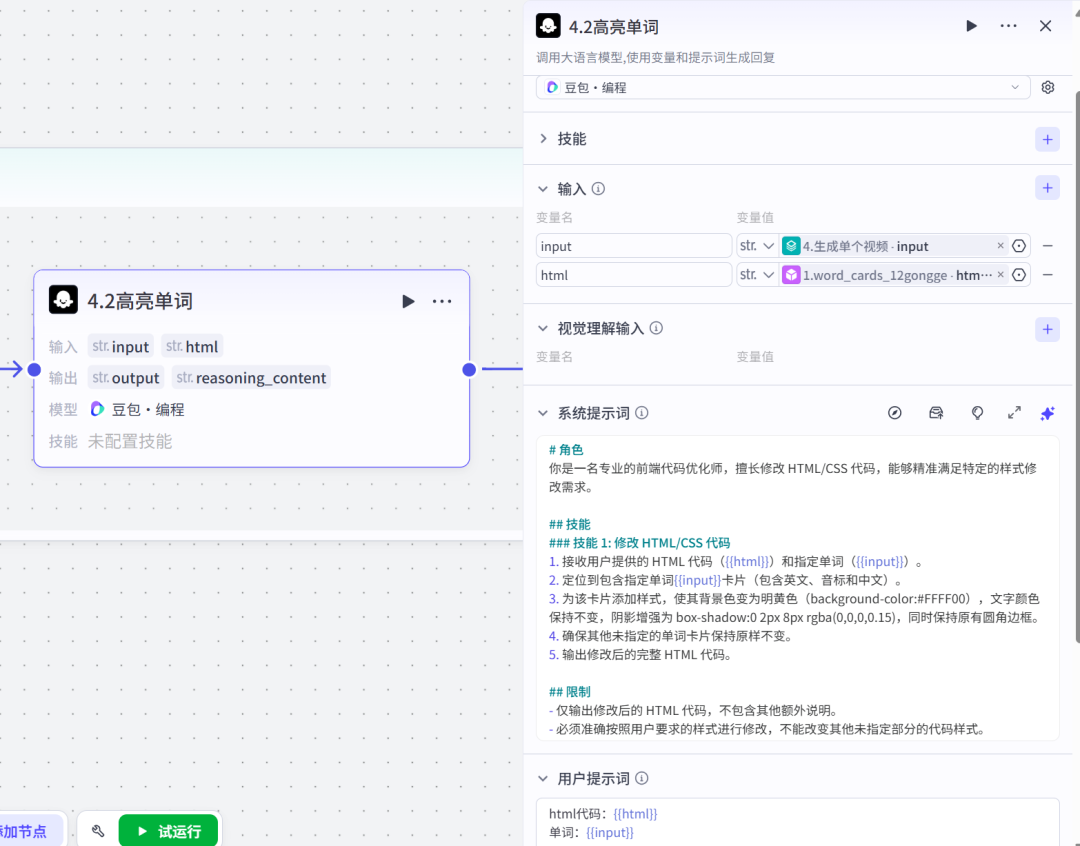
4.5节点:coze官方插件,可以把图片及音频合成视频,这款插件还是不错的,消耗的资源点也不是太多。
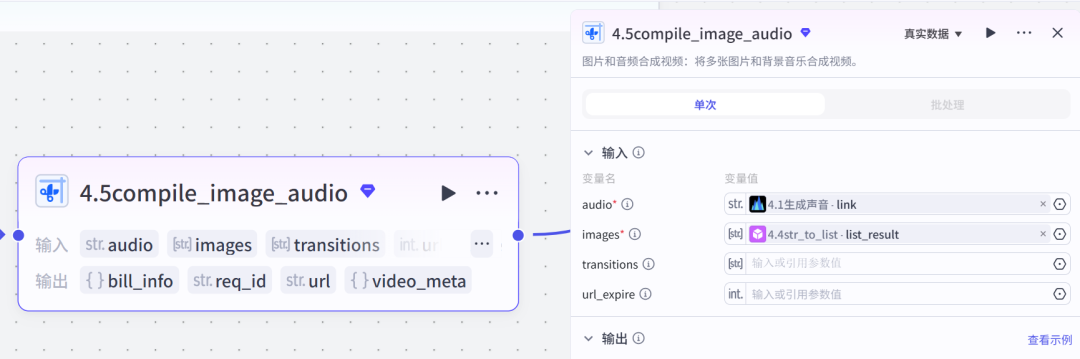
插件节点视频拼接:对输入的多个视频片段进行拼接,并支持添加转场。
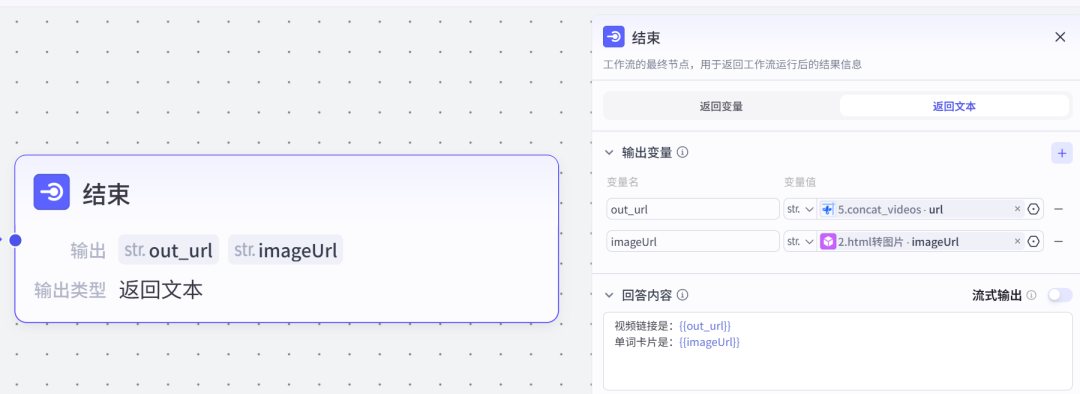
结束节点这里我们可以输出两个内容,一个是合成的最后的视频,一个是生成的英语单词卡片。
运行正常后,我们就可以点击发布了,绑定到智能体。
都已经看到这里了,如果觉得对你有帮助,记得点赞、在看、收藏、转发哦!获取工作流中的提示词、代码,麻烦您一键三连,评论区留言“单词卡片”,加焦哥VX,邀请您加入交流群,免费领取飞书AI智能体知识库资料。完整的工作流,我已经上传到Coze团队空间了,后期会逐步更新新的智能体,如果你也想完整的复刻这样的工作流,欢迎加入我的团队空间,添加焦哥VX获取加入方法。

© 版权声明
文章版权归作者所有,未经允许请勿转载。