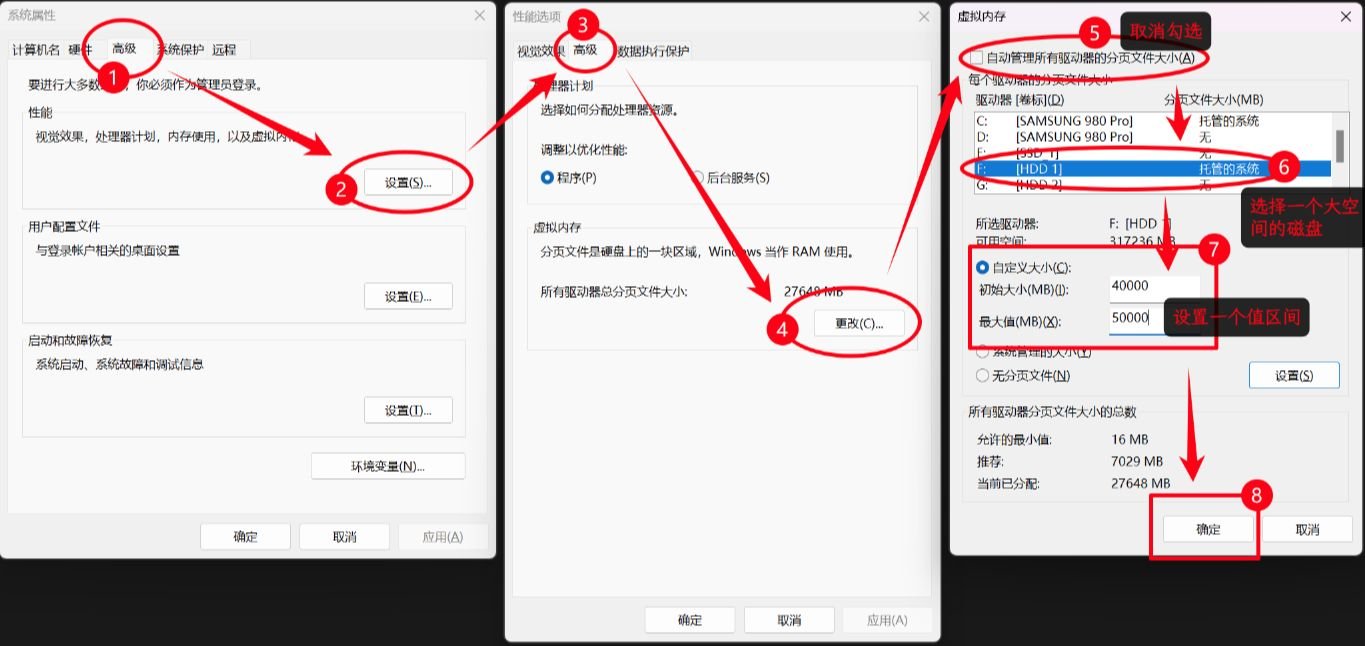
- GLM-4.6V:总参数量106B,单次推理激活参数约12B,视觉理解精度达到同参数SOTA,适合云端与高性能场景;
- GLM-4.6V-Flash:总参数量9B,更轻量,更快捷,适合本地部署;


- case1 万能识搜

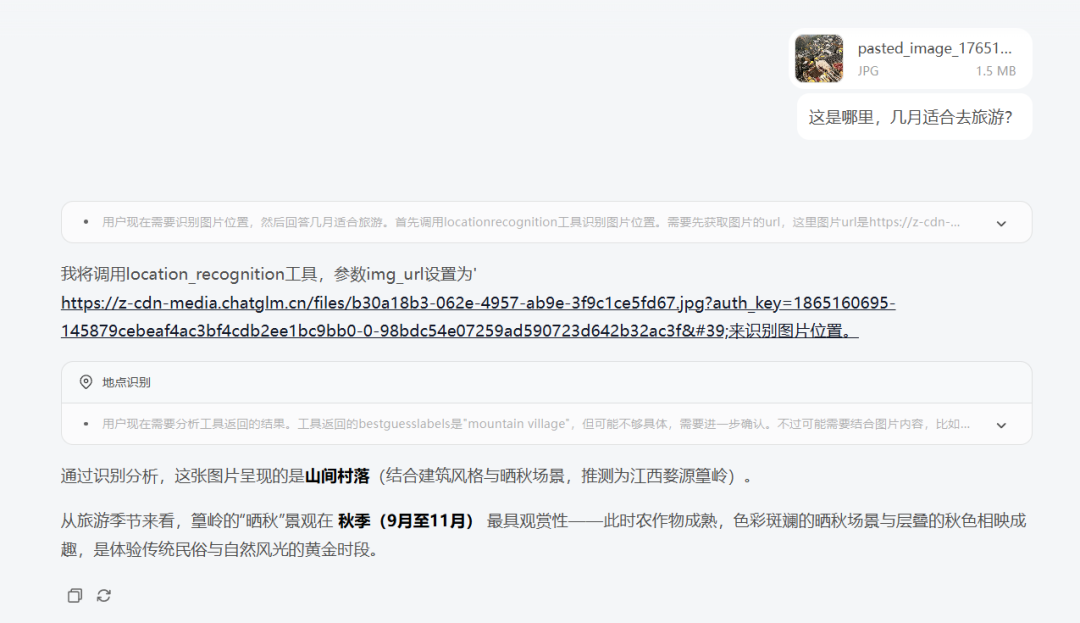
- case2 图文扫描

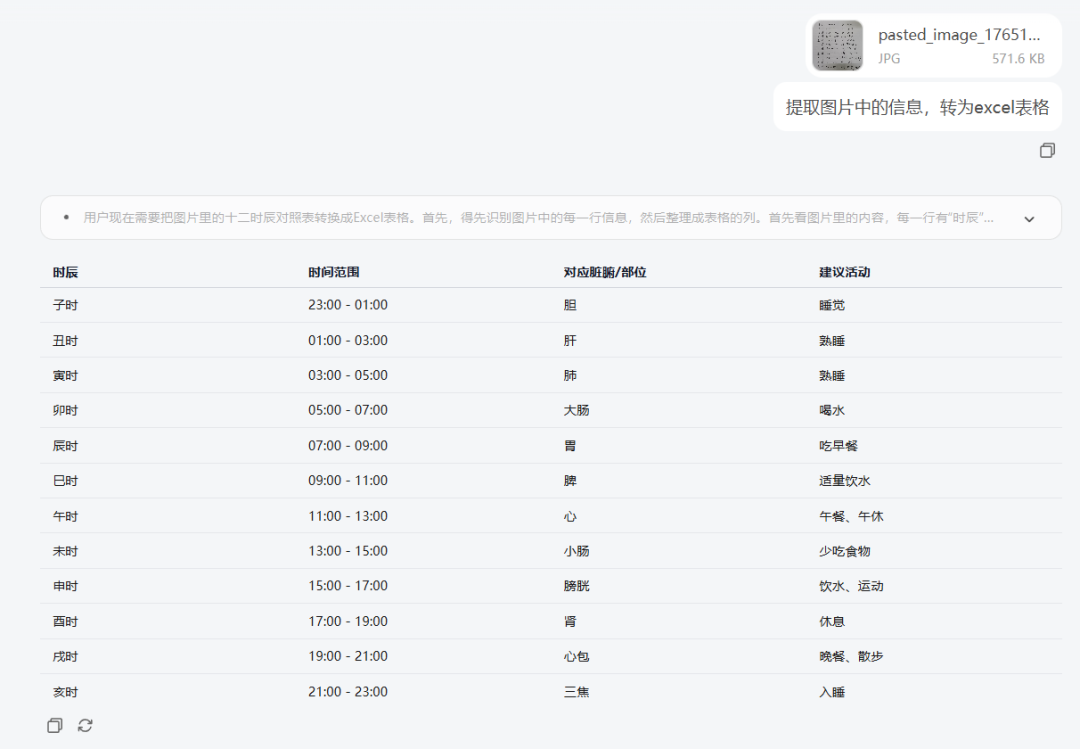

- case3 文档智读
GLM-4.6V 不仅能理解复杂的图表内容,还能把关键信息重新整理,用图文并茂的方式讲清楚。
- case4 视频理解
GLM-4.6V 给出的解读非常专业,整个视频讲述了什么内容,用了哪些镜头,这些镜头语言表达了什么情绪…比我理解的深刻多了。
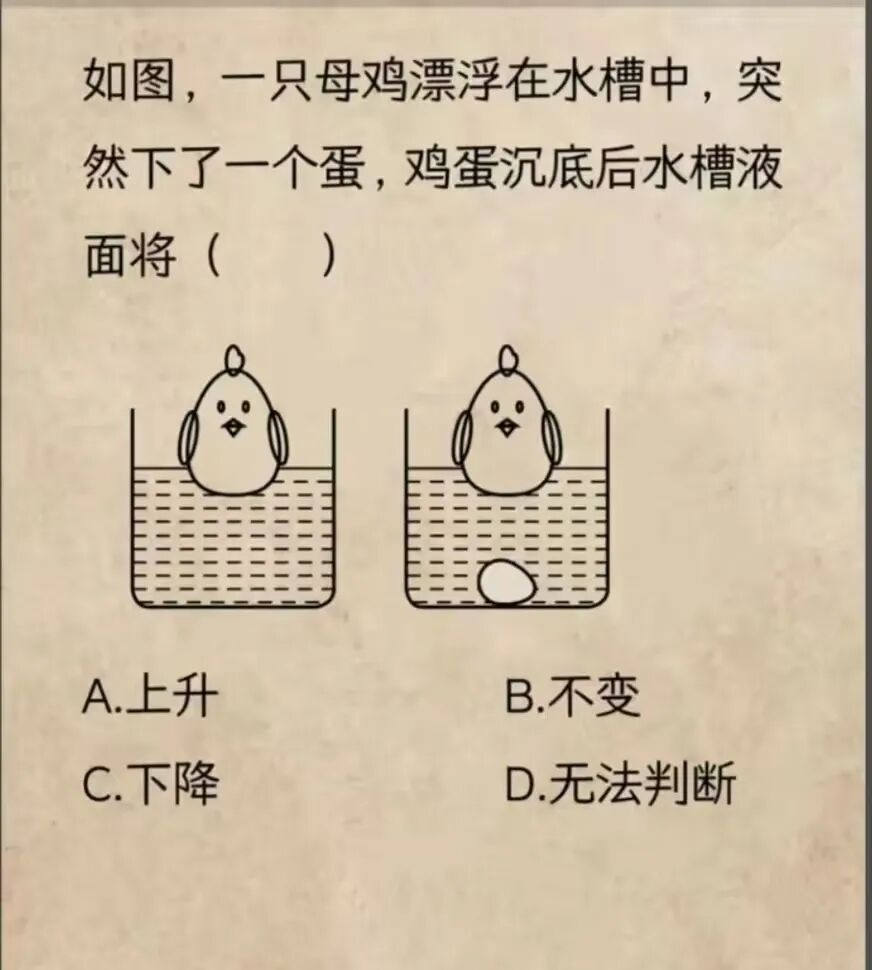
- case5 数理解题

- case6 智能比价


- case7 图文内容创作
- case 8 复刻前端网页

© 版权声明
文章版权归作者所有,未经允许请勿转载。