
 从结果上看,GLM-4.6V 表现跟 Qwen3-VL-235B 持平,这个新系列也会同步智谱的Coding Plan里,API的调用价格比GLM-4.5V 降价 50%那就看看它可以完成多少类Gemini3级的多模态任务,这次测试包括前端复刻、图片信息提取、学术分析、长图文写作和视频理解。
从结果上看,GLM-4.6V 表现跟 Qwen3-VL-235B 持平,这个新系列也会同步智谱的Coding Plan里,API的调用价格比GLM-4.5V 降价 50%那就看看它可以完成多少类Gemini3级的多模态任务,这次测试包括前端复刻、图片信息提取、学术分析、长图文写作和视频理解。
先来做前端复刻好了,我直接截取某书的界面,把这张图片甩给了GLM-4.6V复刻
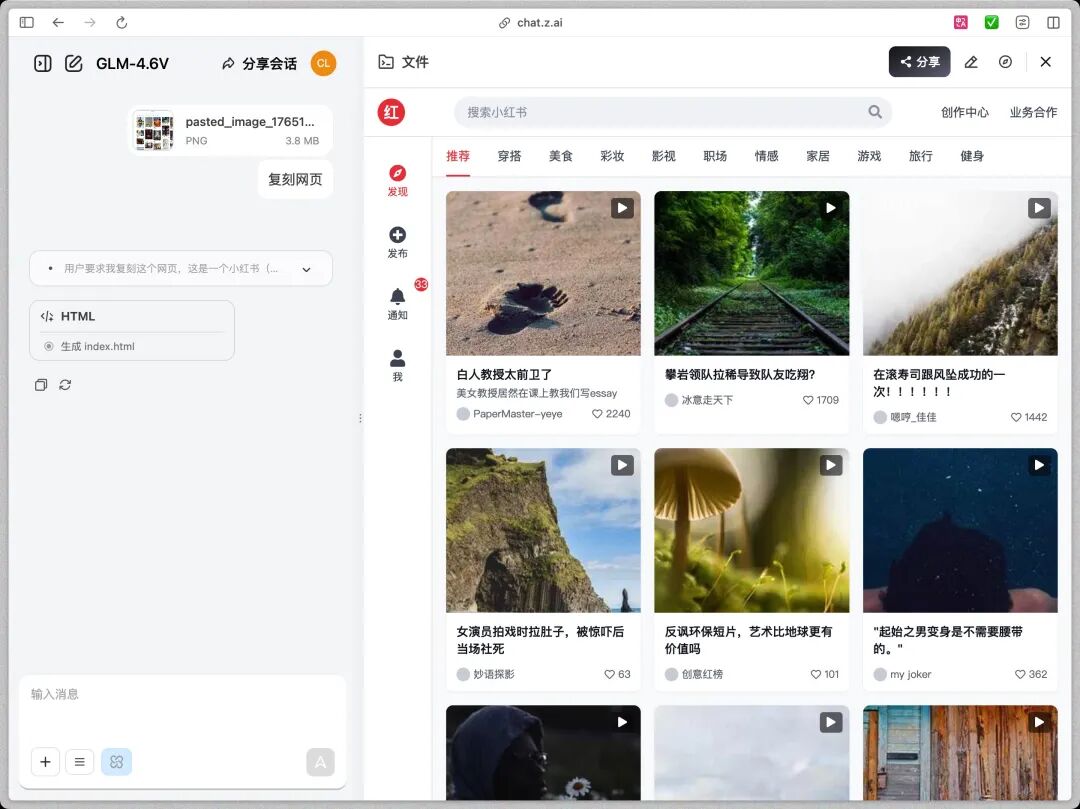
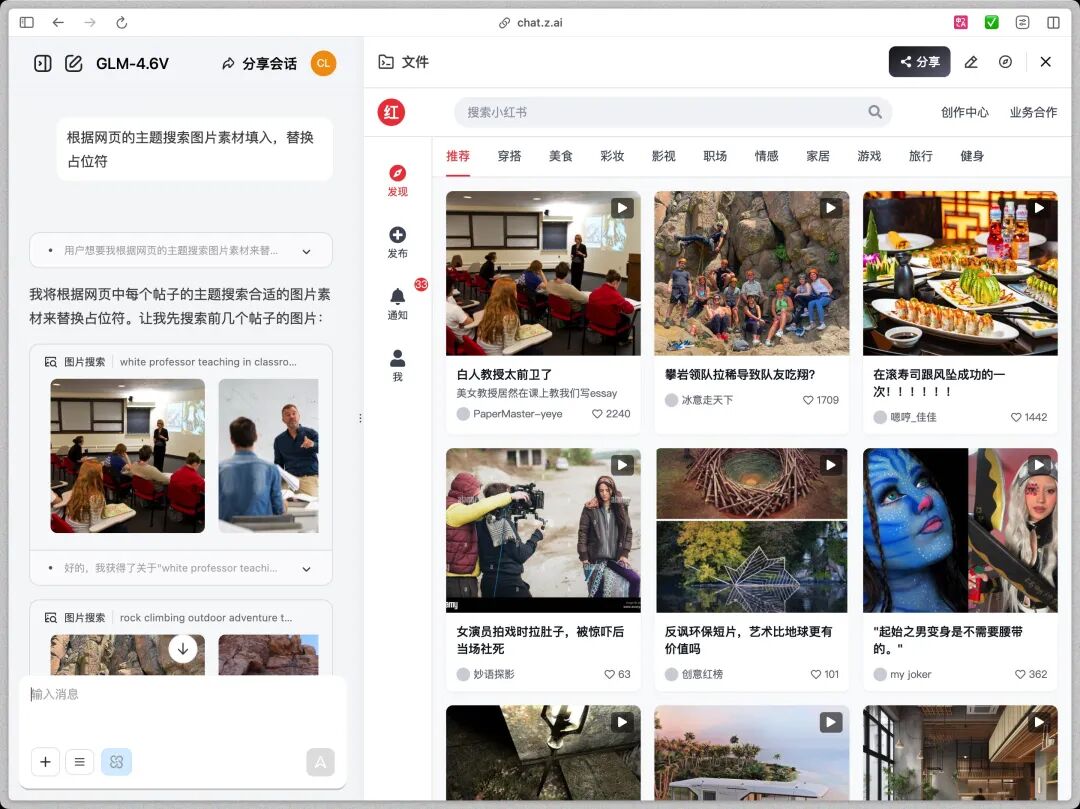
GLM-4.6V的反应很快。生成的代码识别了网页的布局结构,还原了CSS样式,图片的部分用了占位符,没有选择截图原图模糊局部。所以我追加了一个更刁钻的需求,根据每个帖子的主题搜索合适的图片素材填入代码里,
GLM-4.6V找图还找挺准的,那也不能只复刻UI吧,交互我也想复刻下来所以我把点开帖子后的详情页也发过去了,照样是按键,评论,视频进度条等都实现了。
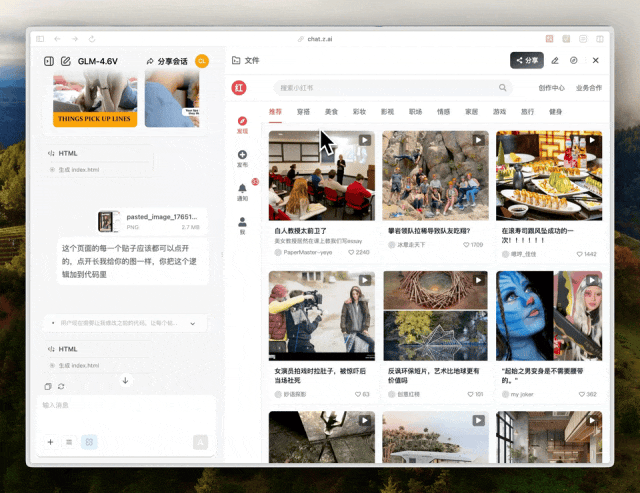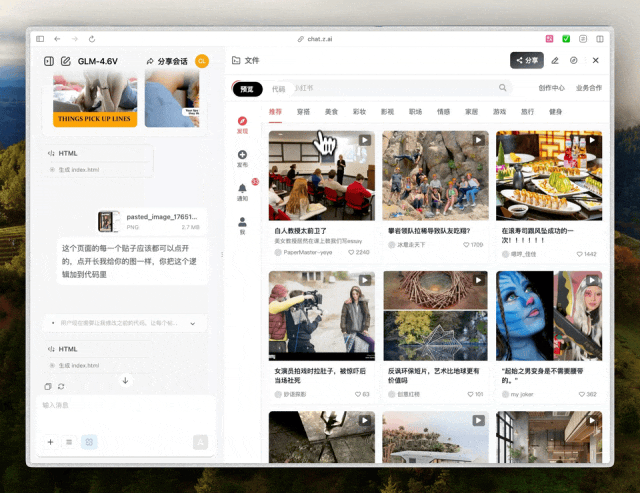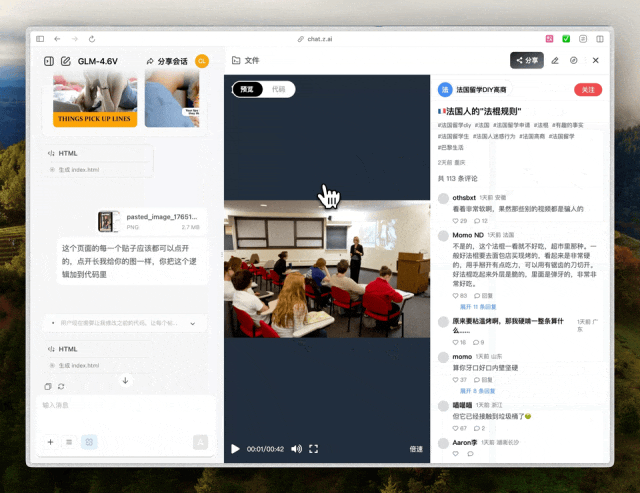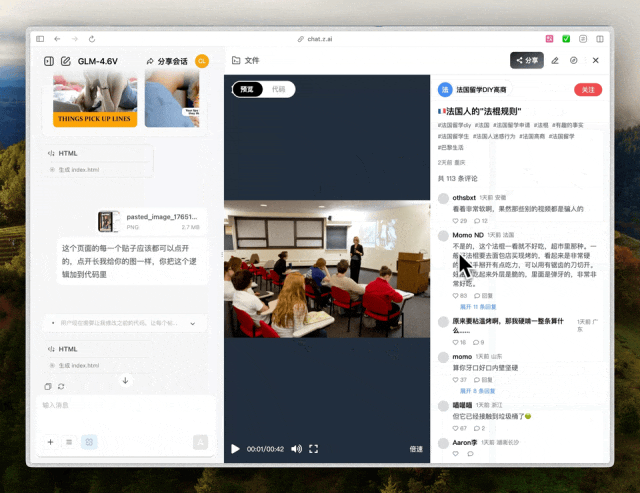
GLM-4.6V的表现蛮不错的,它没有胡堆div,也可以给出自己搜索后的图片,多轮对话叠加交互,给出了干净利落的修改方案。搞定了代码,再来做些枯燥的能丢给AI就绝不自己动手的多模态信息处理。我在一次对话里丢给了它手写表格,发票和手写简历的混合数据。提示语也是复合的,

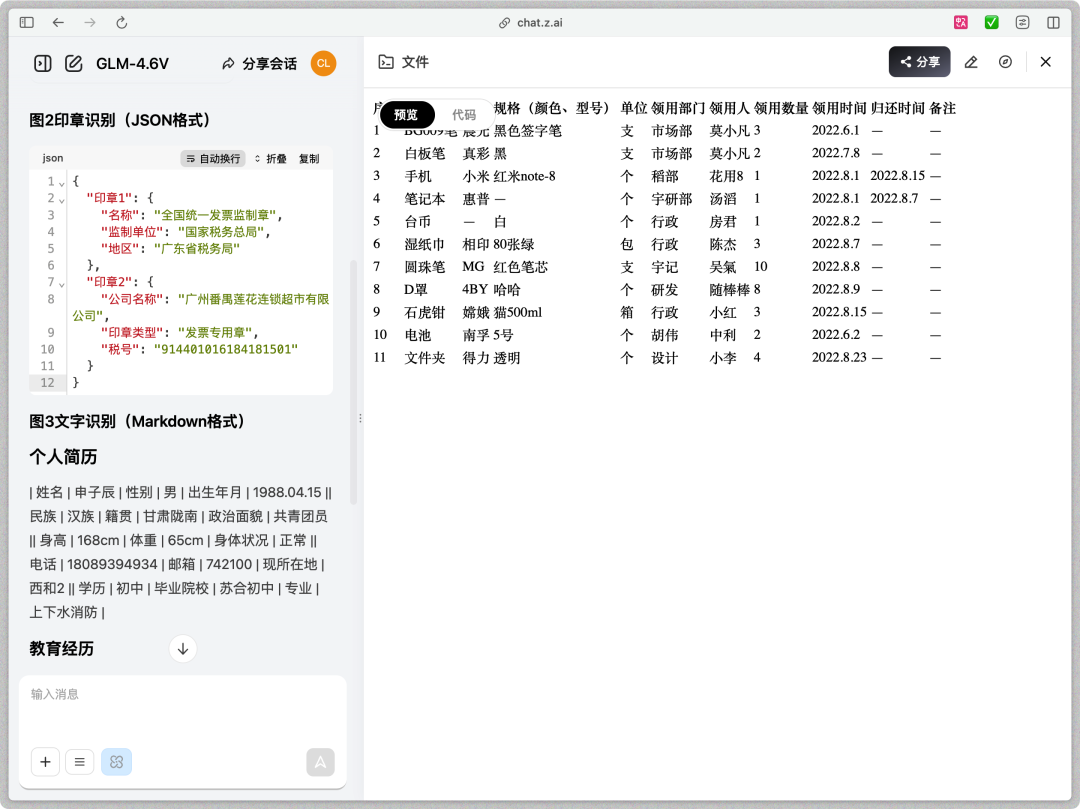
这其实是一个非常考验模型Grounding,也就是定位能力的任务。传统的OCR往往只能把字读出来,但不知道字在哪,也不知道字之间的关系。
GLM-4.6V有原生多模态的优势,输出结果里,表格被完美还原成了HTML,行列对齐,数据无误。印章识别里没有把印章里的字混成一团,而是精准地将印章单位、名称,税号等分成了不同的Key-Value键值对,封装在JSON里。这种结构化的输出能力,也就是说后续我可以直接把GLM4.6V接入到MCP,实现自动化录入。
OK,难度升级!进入深水区,学术研究与复杂文档分析。我找来了两篇论文,要求它结合这两篇论文的图表对比前后有什么不同,


GLM-4.6V的分析结果是直接带论文细节截图的,表格,架构图,论文引用都可以识别下来的。
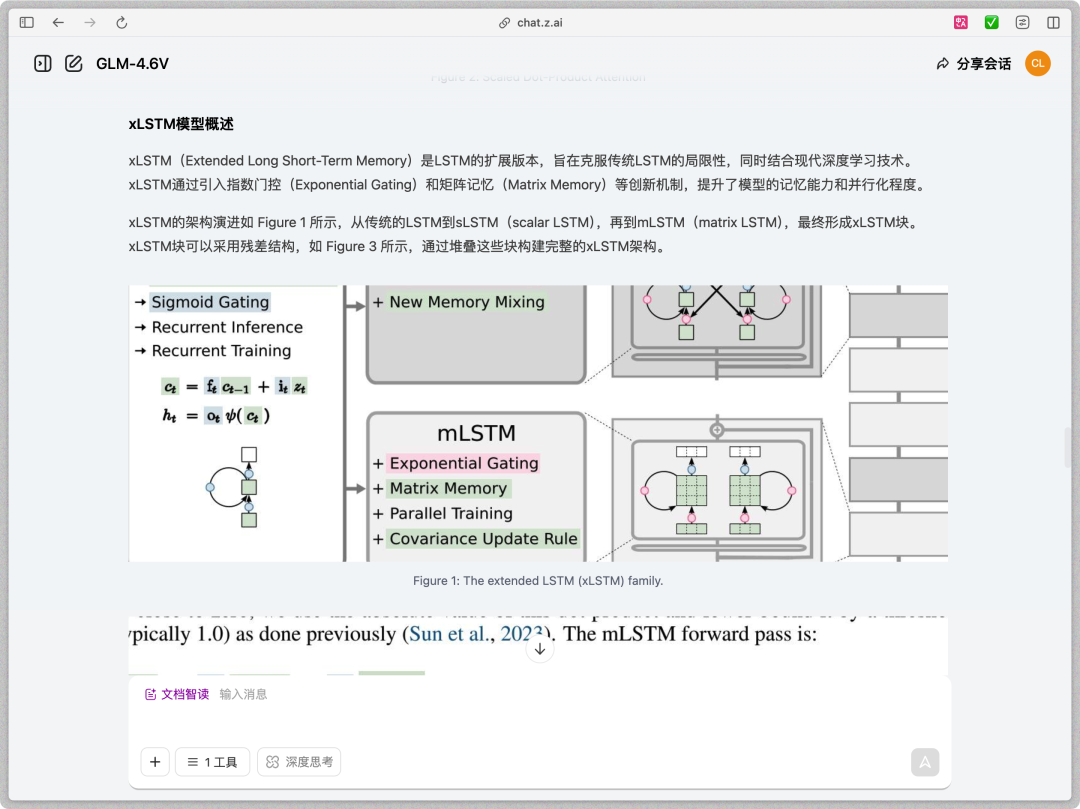
我还让它干了一件有趣的事,
它立刻切换了人格,从学者变成了自媒体,提取了论文的核心亮点,配上了夸张的标题,甚至还从原始文档中截取了关键图片,嵌入到文章的合适位置。那GLM-4.6V单次可以阅读多长的文档呢?为了测试GLM-4.6V的文档理解能力,我直接甩给它一份长达114页的文档,那是巴菲特历年的持仓报告。我的问题是故意为难它的,
典型的大海捞针任务,模型需要遍历长文档,提取三年的数据,进行计算比对,最后锁定目标。
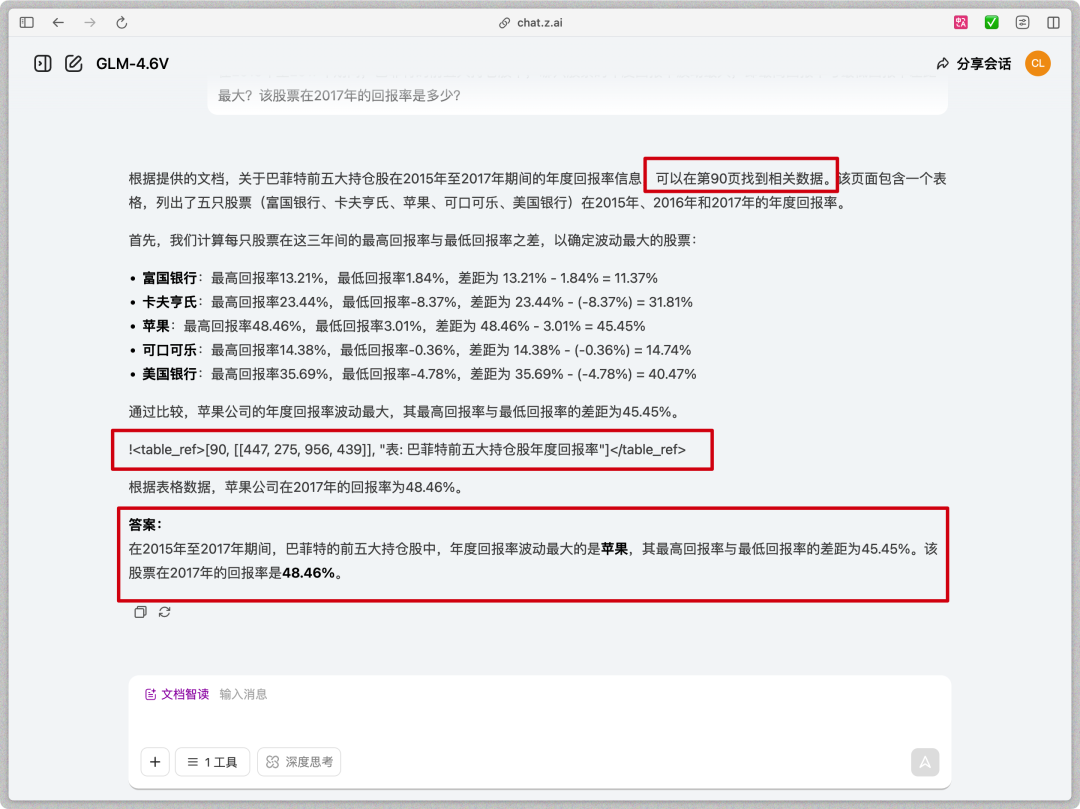
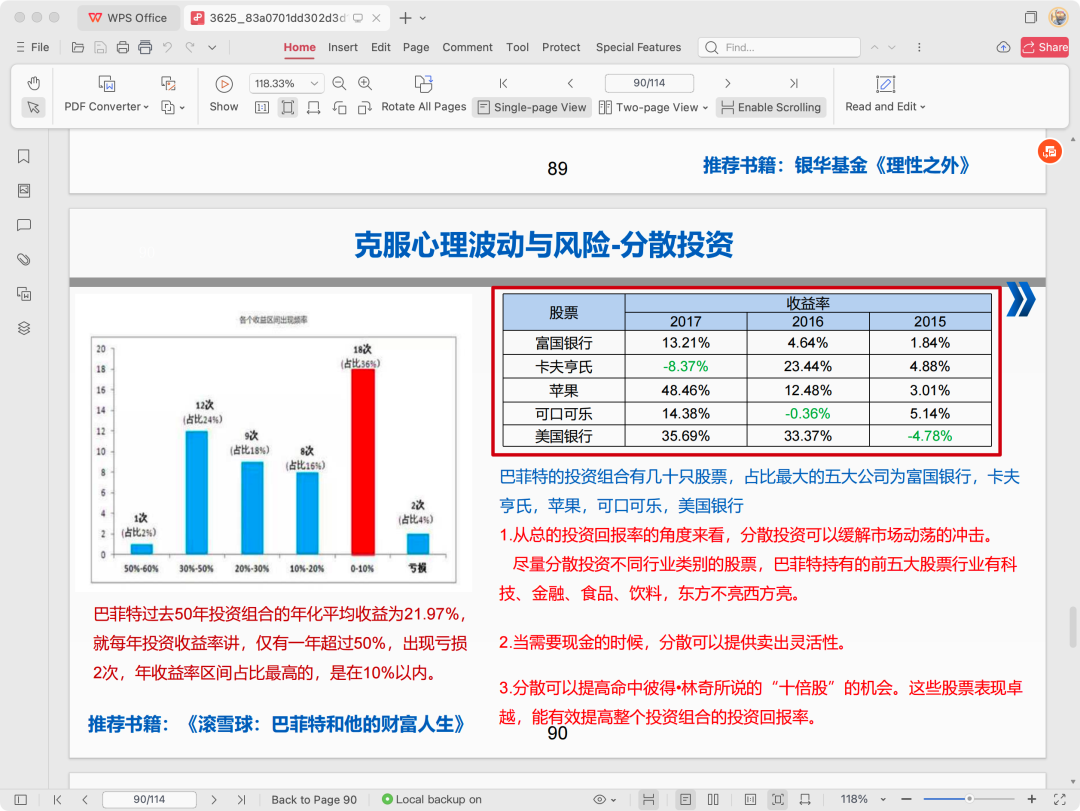
我是做了反复验证的,真的在90页找到了对应的表,验算之后跟GLM-4.6V算的也一样。
最后,模型对动态画面的理解同样至关重要。我给它看了一段视频,让它详细描述这个视频,而不是直接根据字幕给总结
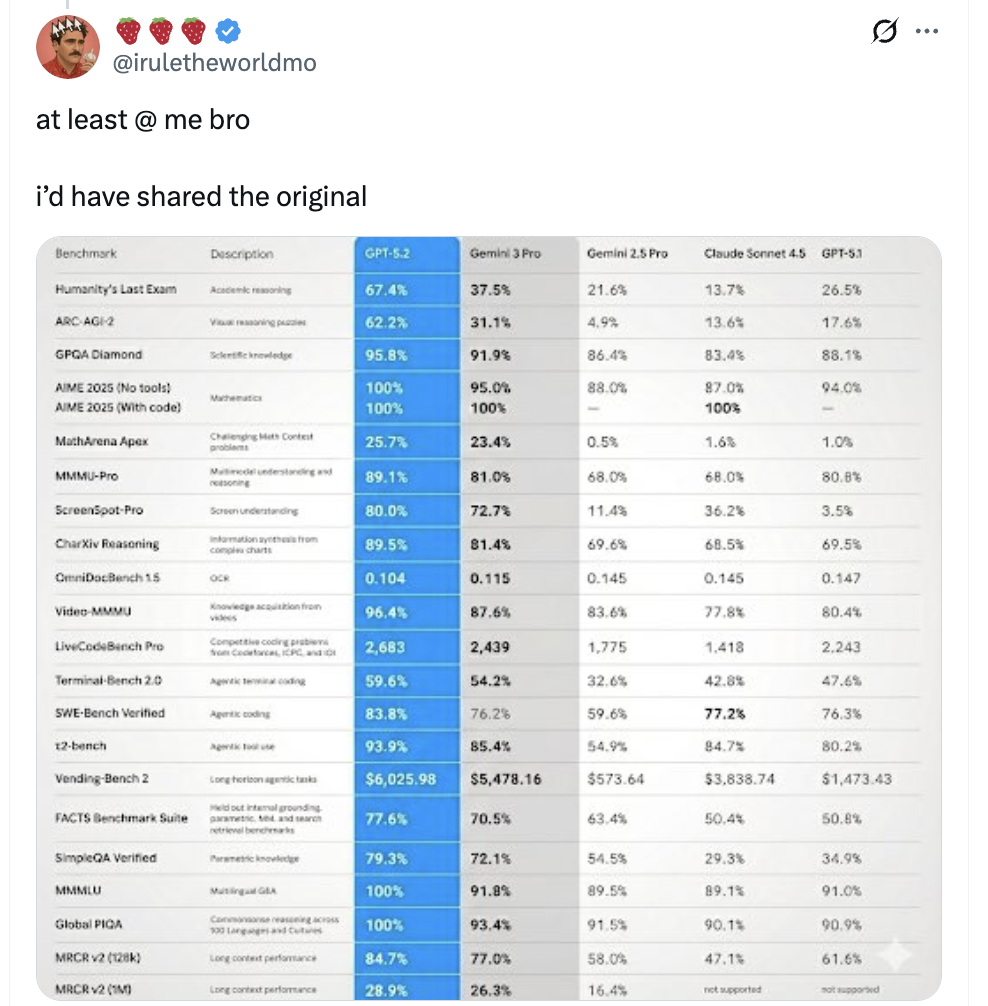
7分钟的视频,一刀没剪,33s完成上传读取和结果输出,我还是下载到本地没有字幕文件的状态的。看得出来GLM-4.6V对长视频的理解也上了一个台阶。它能概括视频的主旨,还能捕捉到画面中一闪而过的关键信息,比如爬行动物隐喻的部分,以及不同动物类比的人物角色。这种能力在视频内容的自动审核及检索上照样很好用。测试完这一圈,我的心情是挺复杂的。隔壁的OpenAI被Google的Gemini 3 Pro吓完了,这两天急着要发GPT-5.2来救场。指标传的太唬人了,全部指标都完胜,结果被发现这图还是Banana2做的。。。
有这空不如学学智谱吧,实打实做一个好用的模型。模型应该是在解决问题,而不是制造用量焦虑。当硅谷们把使用门槛提高提高又提高的时候,能有一个随叫随到真能干活的国产模型顶上来,本身就是我们最大的底气。少了一分对被封号的担忧,多了一分对工作流的掌控,这可能才是AI时代,我们最需要的技术护城河。
@ 作者 / 卡尔
© 版权声明
文章版权归作者所有,未经允许请勿转载。


