
智元自研机器人操作系统“灵渠 OS”开源上线
在 2025 年 7 月的世界人工智能大会主论坛上,智元机器人联合创始人彭志辉通过灵犀 X2,向全球揭晓了自研机器人操作系统“智元灵渠 OS”开源计划。
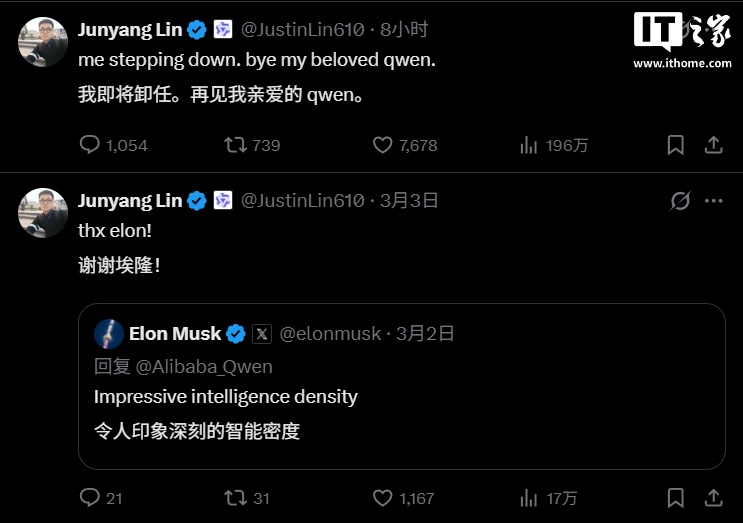
阿里千问技术负责人林俊旸宣布卸任
阿里千问 3 月 2 日晚间 4 款 Qwen3.5 小尺寸模型系列,分别是 Qwen3.5-0.8B/2B/4B/9B。小模型发布后,在海外社交媒体上获得了马斯克的关注。林俊旸则在 X 上感谢马斯克...
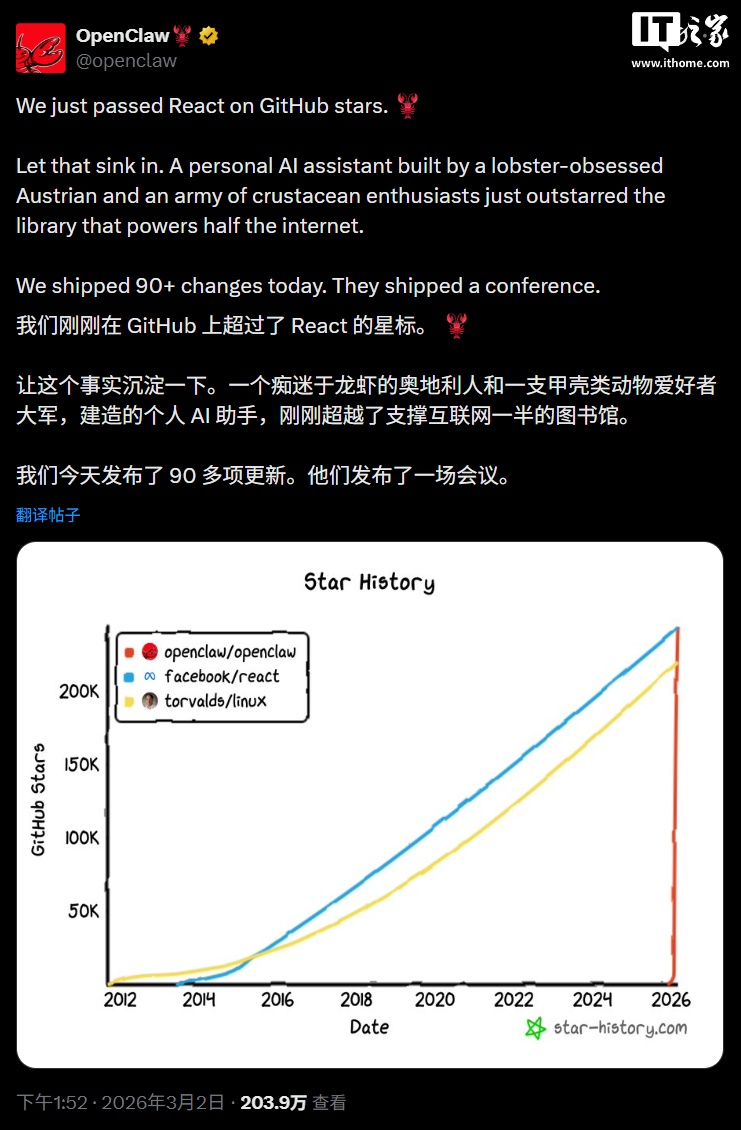
OpenClaw 超越 Linux 和 React 登顶 GitHub 软件星标榜,开通官方微博
OpenClaw 今天还开通了官方微博账号,表示感谢各位开发者与网友的关注,后续将在微博同步 OpenClaw 的技术进展。

荣耀智能体基础模型 MagicAgent 面向全球开源,六项跑分领先 GPT‑5.2
MagicAgent 宣称是行业首个支持全场景泛化规划和异构任务编排的基础模型,也是 YOYO 智能体的“大脑”,专注任务规划与执行编排。
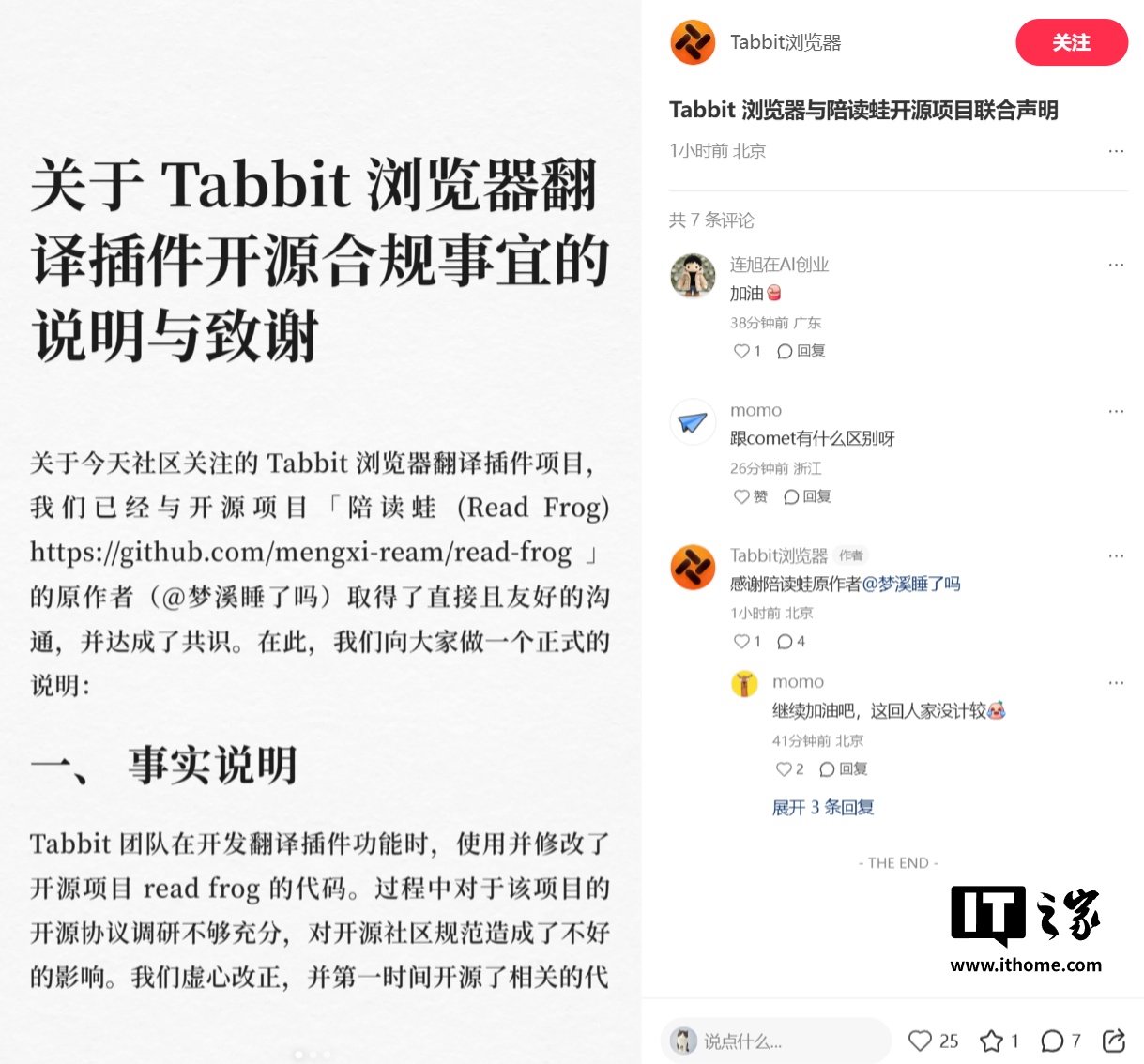
美团 AI 浏览器 Tabbit 代码争议事件原作者回应:确认问题并非出于主观恶意,进一步沟通后续事宜
今日下午,Tabbit 浏览器与“陪读蛙”开源项目发布联合声明,Tabbit 团队表示已经与“陪读蛙”的原作者取得了直接且友好的沟通,并达成了共识。
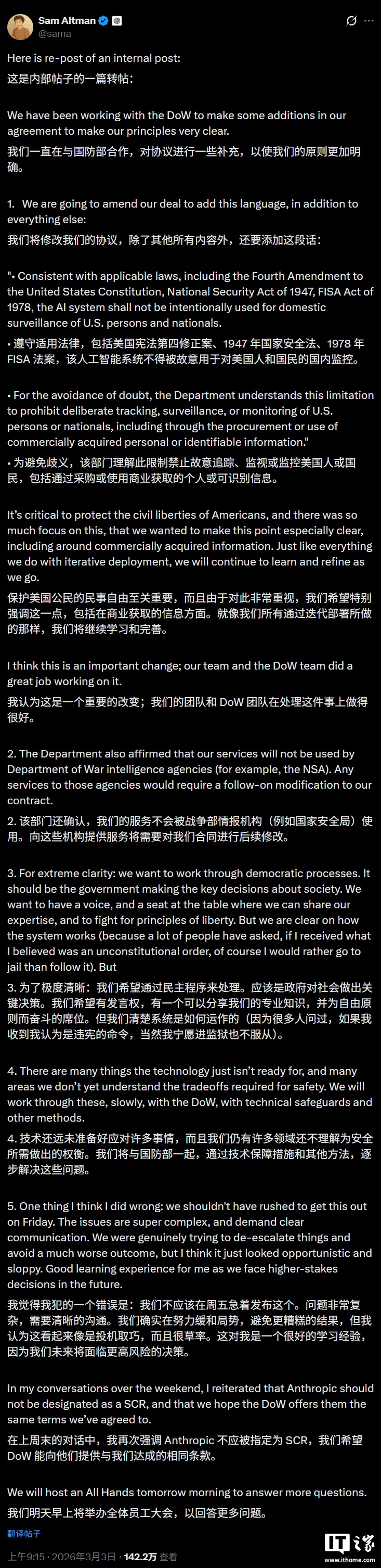
OpenAI 将修改与美国战争部的协议,明确禁止监视美国人
OpenAI 此前与美国战争部(国防部)达成的 AI 合作引发了众怒,ChatGPT 在美国的卸载量暴增,大量用户给出 1 星评价。
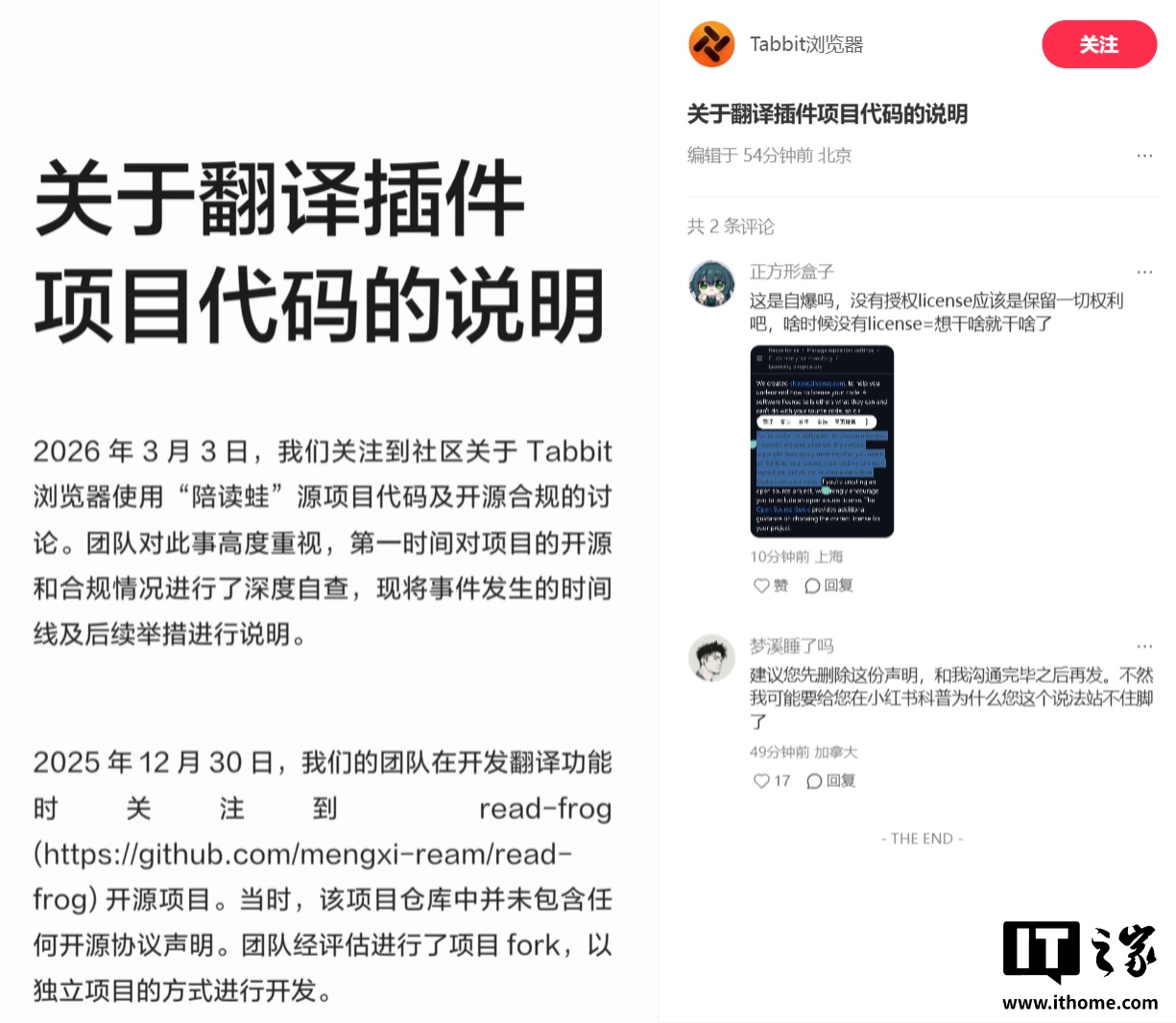
美团旗下 AI 浏览器 Tabbit 涉嫌抄袭代码?官方回应称充分尊重原作者,已移除相关项目
美团旗下光年之外团队推出的 AI 浏览器 —— Tabbit 浏览器今日发布《关于翻译插件项目代码的说明》。

时隔十年,韩国围棋棋手李世石将再度对决 AI
他曾在 2016 年与 AlphaGo 的人机大战中以 1:4 告负,不过他战胜 AlphaGo 的一局,被誉为人类有史以来第一次战胜 AI 棋手之局。

阿里千问 Qwen3.5 小模型开源获马斯克点赞:令人印象深刻
至此,千问 3.5 家族已开源 Qwen3.5-397B-A17B 的大尺寸模型,Qwen3.5-122-A10B、Qwen3.5-35B-A3B、Qwen3.5-27B 等 3 个中型尺寸模型,以及...

华为在 MWC 2026 发布 AI 数据平台,首创“3+1”架构
在本周的巴塞罗那 MWC 2026 世界移动通信大会期间,华为数据存储产品线总裁袁远在产品与解决方案发布会上正式发布 AI 数据平台。