Hugging Face CEO 回应“AI 泡沫说”:倒不如说现在是“大语言模型泡沫” 依照 Clem Delangue 的看法,目前被过度追捧的是驱动 ChatGPT、Gemini 等聊天机器人的大语言模型。不过,这种关注可能不会持续太久。 AI 新资讯行业资讯# AI泡沫# Hugging Face# 人工智能 9个月前5,949736
研究称 AI 在社交平台发的帖子仍易被识别,只因大模型不擅长情感表达 苏黎世大学、阿姆斯特丹大学、杜克大学和纽约大学的最新研究表明,各种大语言模型生成的社交媒体帖子都“容易被区分”,且准确率达到70%至80%,远高于随机猜测的结果。 AI 新资讯行业资讯# 大语言模型# 社交媒体 9个月前6,420637
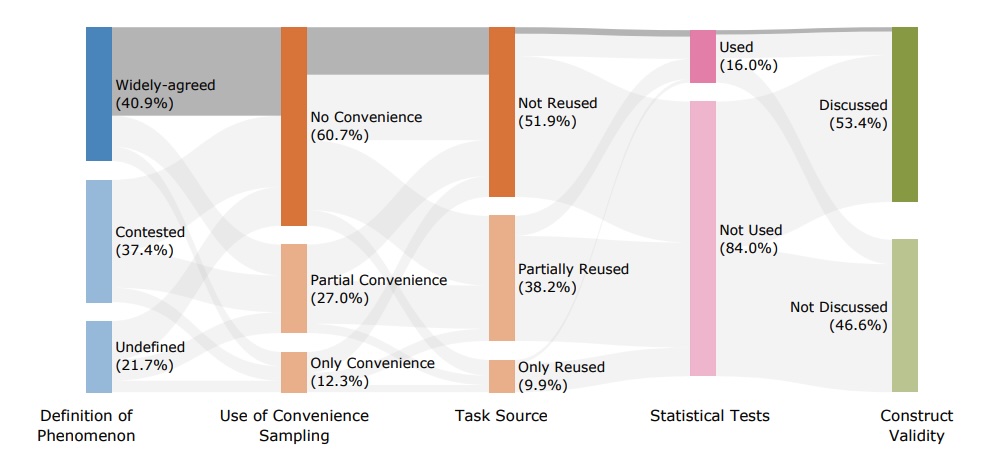
科学家发现多数大语言模型测试标准存在缺陷,无法客观给出评分 牛津大学等机构研究发现,多数大语言模型测试标准存在方法论缺陷,如术语模糊、数据采样不当等,导致AI进步难以客观衡量。研究建议明确定义目标、防止数据污染等改进措施。#AI测试标准##大语言模型# AI 新资讯行业资讯# 大语言模型 9个月前6,251149
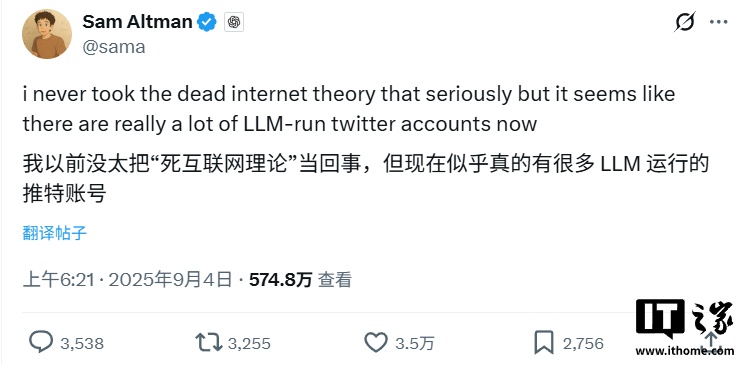
研究显示:低质数据可令 AI“大脑退化”,OpenAI 奥尔特曼担心的“死网论”正逐渐成真 康奈尔大学研究指出,大语言模型接触低质网络内容会“大脑退化”。以Llama 3和Qwen 2.5实验,低质训练让准确率等下降。多位科技人士担忧“死网论”,互联网正面临内容质量与真实性考验。 #AI大脑... AI 新资讯行业资讯# OpenAI# Sam Altman# 大语言模型 9个月前7,063950