

Google今天正式发布了开源模型Gemma 4,有4个型号,性能可以说是直接拉满了。
E2B和E4B这两个是我最关注的。
Google的博客里说:在边缘侧,我们的E2B和E4B模型重新定义了端侧实用性。
我第一时间打开手机实测,结果很明显,端侧AI的春天真的到了。
测第一遍的时候,生成速度那么快确实是很惊人的,是我没见过世面了,还特意把手机飞行模式试了下。
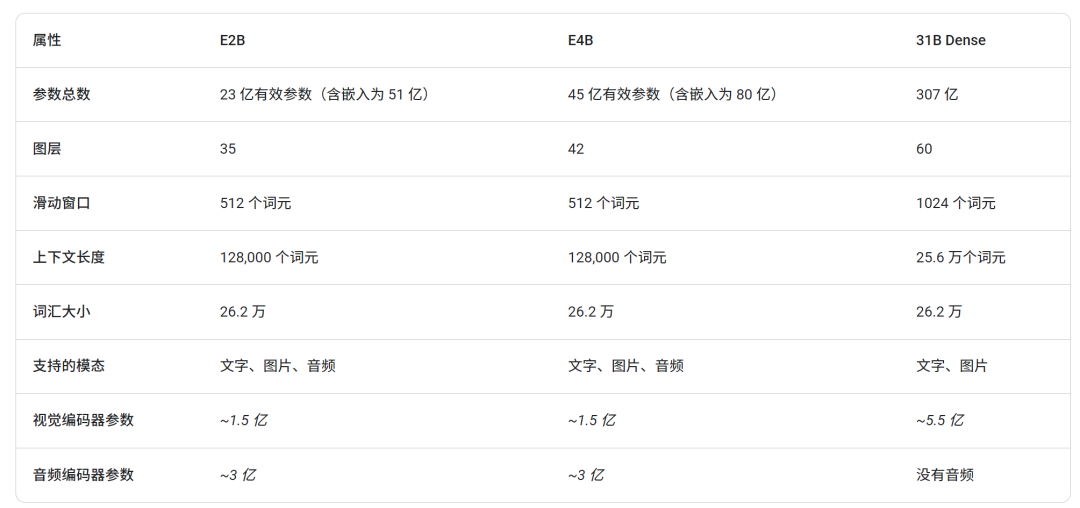
密集模型
密集模型总共有三个。
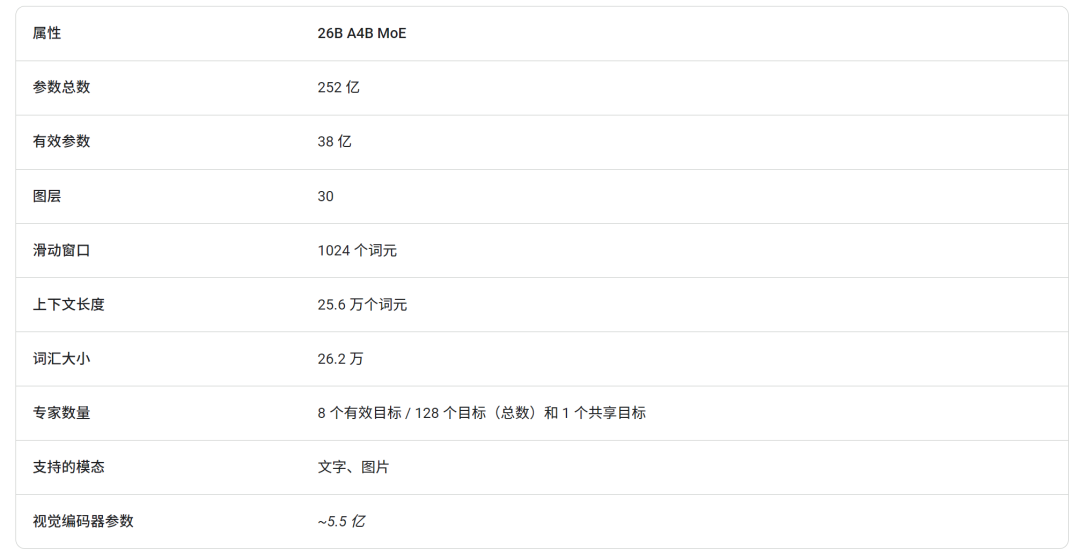
混合专家 (MoE) 模型
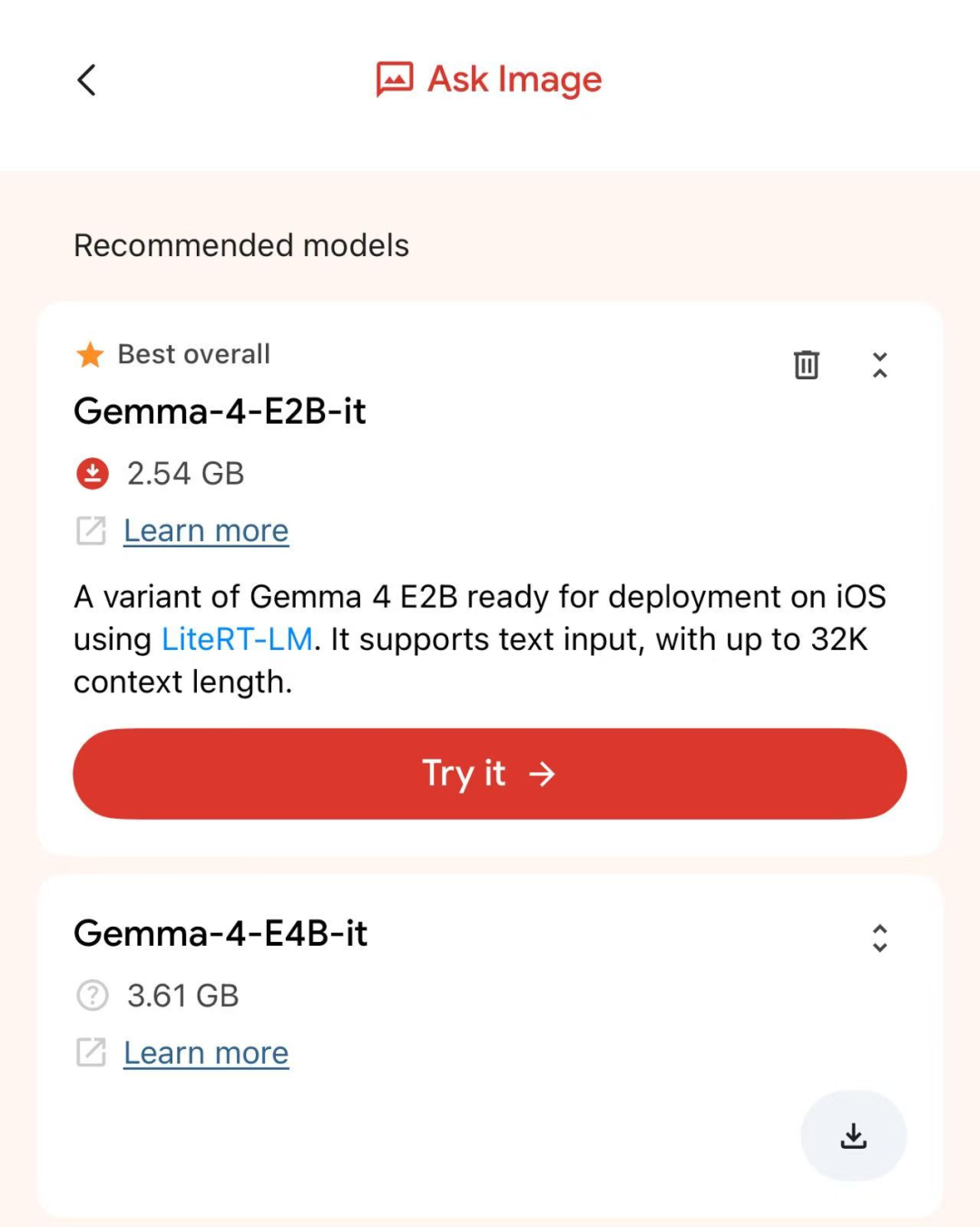
E2B大概占用2.2GB – 2.5GB,8GB内存的普通手机,扣掉系统内存跑起来也算比较流畅。
E4B大概占用3.8GB – 4.2GB,得12GB内存以上的旗舰机才能玩。
其他两个型号得比较新的苹果电脑型号或者3090/4090这种卡去跑了。
找了个很简单的方法去玩端侧模型。
Google发布的Google AI Edge Gallery,能在上面直接下载很多的端侧模型,苹果手机不放给咱们玩,Google帮咱们实现了一部分。
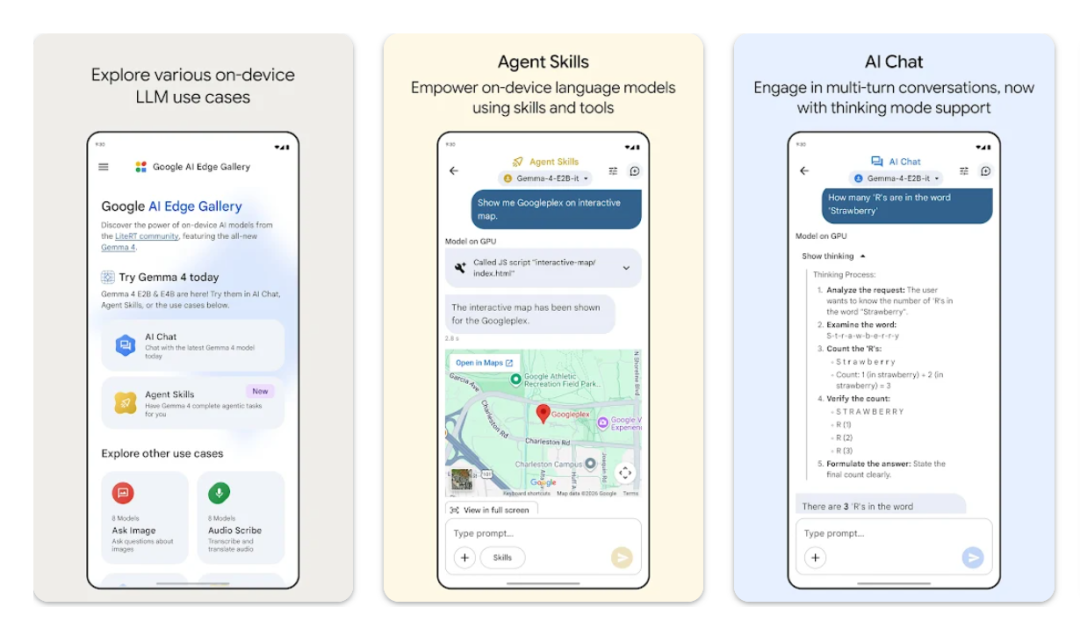
就两三个G,下载很快。
全程无加速无剪辑。
测试型号,iPhone15 Pro Max
它是多模态模型,再来测一张图片分析,也是快的离谱。
无法想象,这样小的一个端侧模型,也是支持深度思考的。
为什么Gemma 4能在手机上跑出高性能?
关键在于Sparse Attention(稀疏注意力)机制的进一步演进。
相比传统的全量计算,Gemma 4能够精准地划重点,只计算最相关的token。
这不仅降低了计算量,更直接砍掉了40%的电池损耗。
所以,Gemma 4,在端侧现在是真的称王称霸了。
写在最后
在手机上就能跑的端侧模型彻底落地,开发者也可以基于这个模型做更多事情了。
网络、云服务器,可能在移动端要慢慢退下来了。
各大应用商店的APP开发者们,狂欢吧!

© 版权声明
文章版权归作者所有,未经允许请勿转载。