🌟一、什么是算法偏见? 🤖⚖️
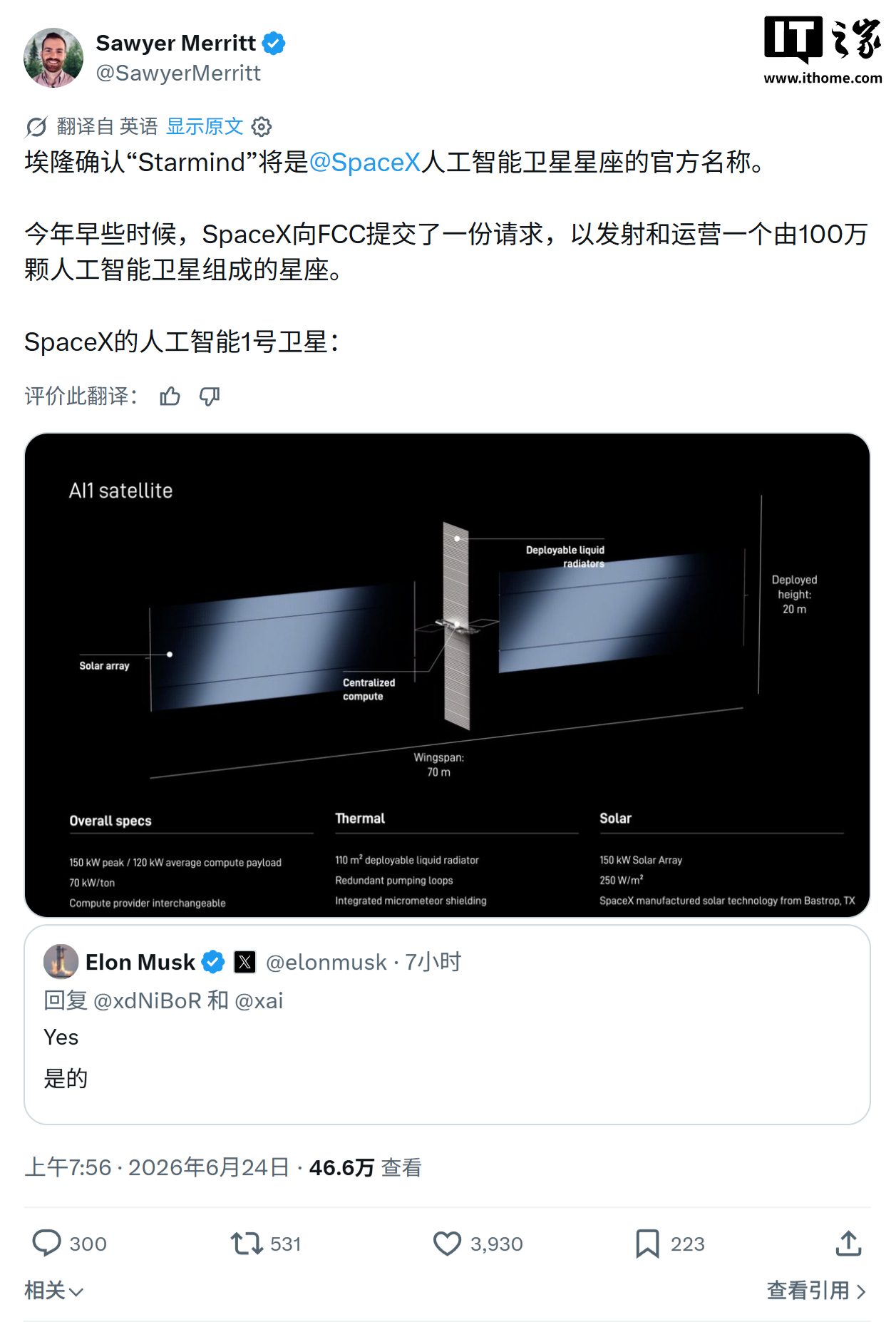
算法偏见(Algorithmic Bias)指的是在数据、模型或运行过程中,算法对某些群体或个体产生系统性、不公平的差异性对待,导致输出结果对特定群体产生歧视或不公;产生原因是由于训练数据、算法设计或应用环境等因素。具体表现为:
- 歧视性结果:某些人群被过度拒绝(如贷款、招聘被系统性地拒绝)。
- 透明度不足:无法解释为何对不同群体得出不同结论。
- 可持续性影响:误导决策、加剧社会不平等。
🌟二、算法偏见的主要来源
算法偏见并非有意为之,而是源于以下几个方面:
- 训练数据偏见 (Data Bias):这是最常见也是最根本的来源。
- 历史偏见 (Historical Bias):训练数据反映了过去社会中存在的偏见和歧视。例如,如果过去招聘数据中男性占多数,那么训练一个招聘算法可能会倾向于选择男性候选人。
- 采样偏见 (Sampling Bias):训练数据未能充分代表目标群体。例如,如果一个面部识别算法主要使用白人面孔进行训练,那么它在识别其他种族的面孔时可能会表现不佳。
- 测量偏见 (Measurement Bias):用于收集数据的过程本身存在偏差。例如,如果一个信用评分模型使用的数据来源存在系统性错误,那么它可能会对某些群体产生不公平的评分。
- 反映偏见 (Representation Bias):训练数据中某些群体的样本数量不足,导致算法对这些群体的理解不够准确。
- 算法设计偏见 (Algorithmic Bias):
- 目标函数偏见:算法的目标函数本身可能存在偏见,例如,为了最大化点击率而牺牲公平性。
- 特征选择偏见:算法选择的特征可能与某些群体存在关联,导致算法对这些群体产生偏见。
- 模型假设偏见:算法所做的假设可能不适用于所有群体,导致算法对某些群体产生偏见。
- 应用环境偏见 (Deployment Bias):
- 上下文偏见:算法在不同的应用环境中可能表现出不同的偏见。
- 反馈循环偏见:算法的决策会影响未来的数据,从而导致偏见不断加剧。
- 解释性不足:算法的决策过程不透明,难以发现和纠正偏见
🌟三、治理算法偏见的四大层面
|
|
|
|---|---|
|
|
• 数据清洗与重加权 • 对敏感属性设限 |
|
|
• 对抗性去偏技术 • 可解释性(XAI) |
|
|
• 多元化团队 • 定期开展算法审计 |
|
|
• 行业标准与自律 |
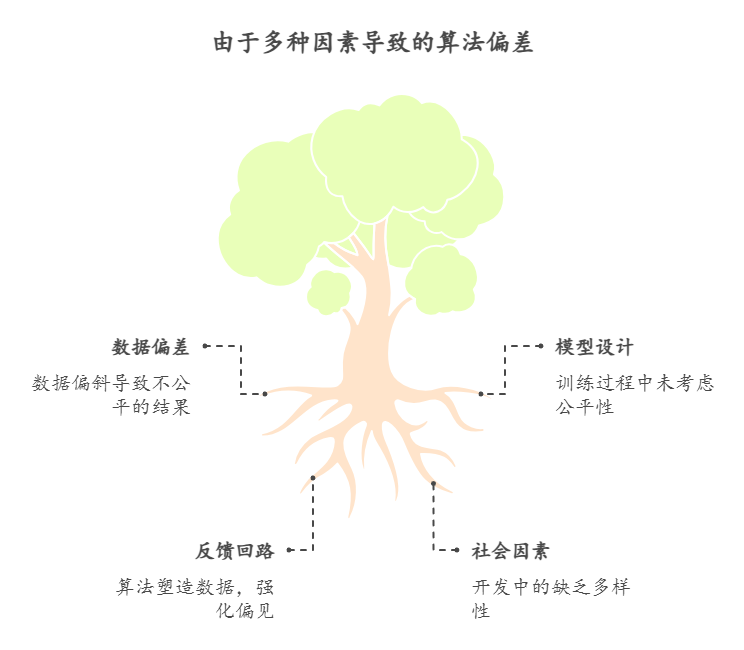
💫1. 数据层面:
- 重采样/重加权:对少数群体样本加权,平衡训练集分布
- 清洗标签:消除历史歧视标签(如司法数据中对某族裔的过度定罪)
💫2. 模型层面:
- 公平性指标:如“机会均等(Equal Opportunity)”、“预测率平等(Predictive Parity)”等,用以量化和约束偏差
- 对抗性去偏:引入对抗网络,让模型在保持准确度的同时“无法区分”不同敏感属性
💫3. 组织层面:
- 多学科审查:技术、法律、伦理专家共同评估算法风险
- 算法审计:内部或第三方定期评估算法性能与公平性,公开审计报告
💫4. 法规政策:
- 强制披露:要求企业公开算法原理、数据来源、绩效指标
- 问责制度:对损害用户权益的算法决策进行法律追责
🌟四、实践案例
- 招聘系统去偏:
-
✂️ 去除简历中的性别、年龄等敏感字段 -
📊 引入“盲评”机制,评估算法在不同群体上的通过率差异 - 信贷风控模型:
-
🛠 模型训练中加入“机会均等”约束,确保相似信用状况的申请人获得相似批准率 -
🔍 定期审计,监测不同族裔、性别的拒贷率
🌟五、下一步建议
- 从源头做起:项目立项时即纳入“公平性评估”
- 持续监测:上线后定期回溯与审计,动态修正
- 用户反馈:开放申诉通道,让受影响者有发声与纠偏机会
- 行业协作:参与开源社区,共享算法审计工具与最佳实践
🌟六、工具和资源:
- AI Fairness 360 (AIF360):IBM开源的工具包,用于检测和减轻算法偏见。
- Fairlearn:Microsoft开源的库,用于评估和减轻机器学习模型的公平性。
- What-If Tool:Google的工具,用于可视化和分析机器学习模型的行为。
- TensorFlow Data Validation (TFDV):TensorFlow的工具,用于验证和分析数据质量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。