
最近新出的音频克隆项目不多,今天给大家推荐的这个很有特色,功能很多,而且对显存低的机器很友好,Win/Mac/Linux都支持。
已经点了5k星了。
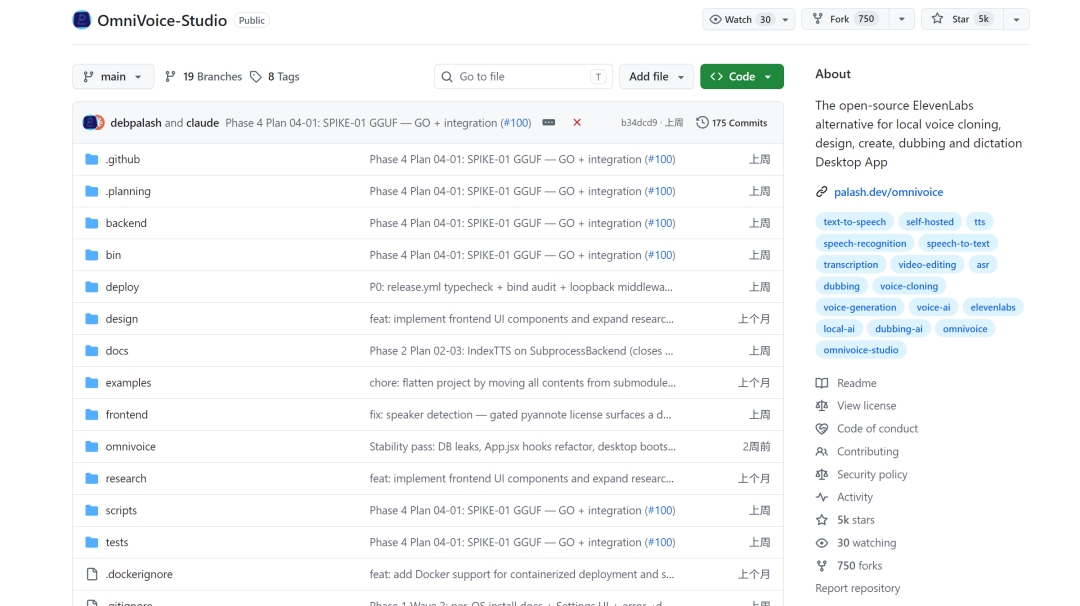
很多自称本地运行的开源音频工具,要么配置极其复杂,要么前端UI极其简陋,根本无法用。
OmniVoice Studio直接提供了跨平台的桌面客户端,直接支持646种语言 的声音克隆。
运行原理:
- 最低内存要求为4GB,内存≤ 8 GB 时,TTS模型会在转录过程中自动卸载到CPU上运行。
- 内存≥ 8 GB 时,所有操作都会同时在GPU上运行。
- 没有GPU的情况下,CPU 模式也能运行,只是速度会慢一些,TTS速度大约慢3倍。
功能特点
- 零样本声音克隆:无需微调训练,只需导入一段3秒钟的目标音频样本,系统就能很快复刻音色。
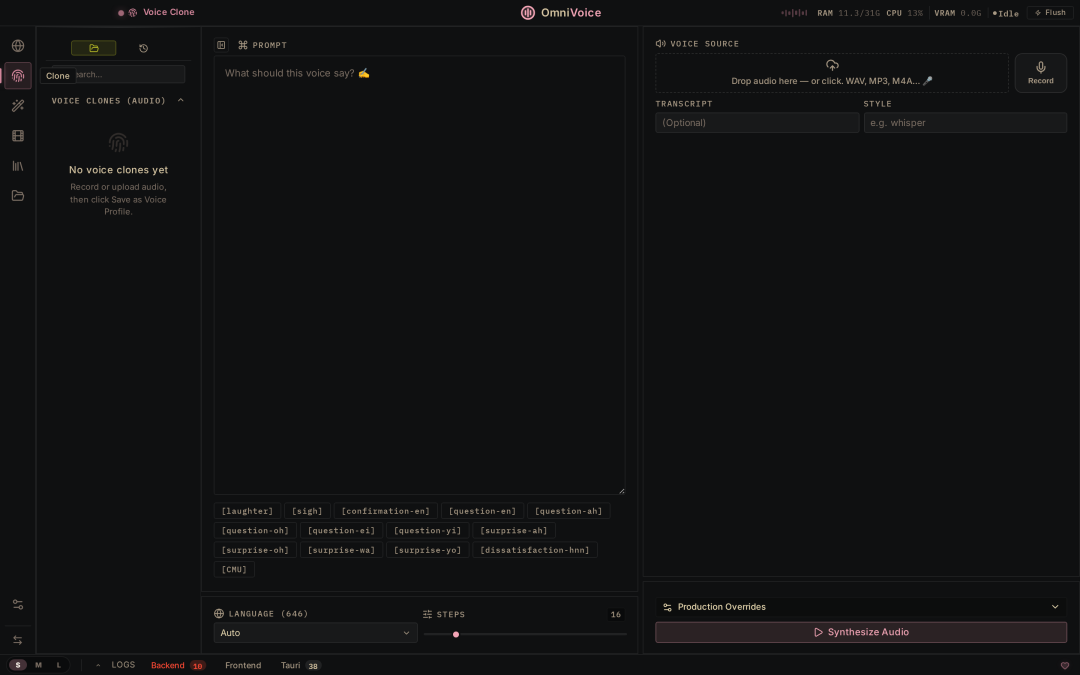
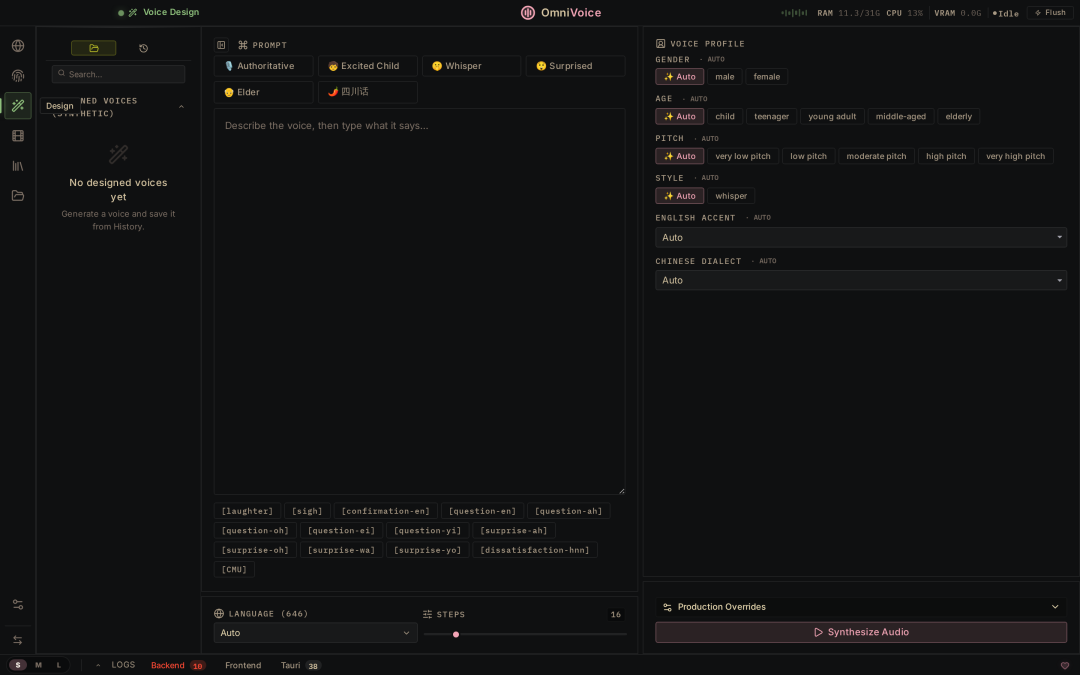
- 声音设计:用户随意调节声音的性别、年龄、口音、音高、速度、情感乃至地方方言,生成的声线可直接存入本地声音画廊随时调用。
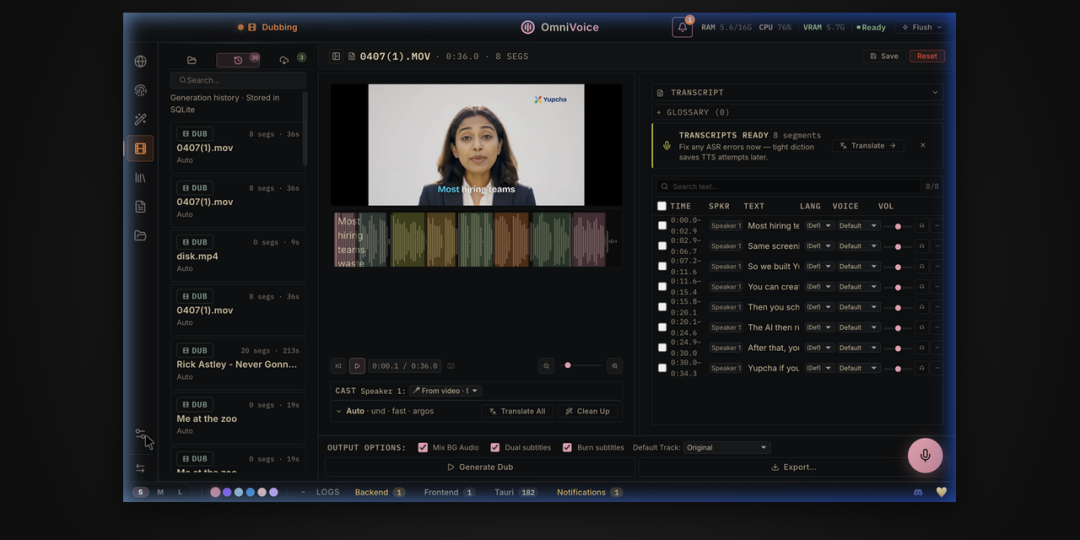
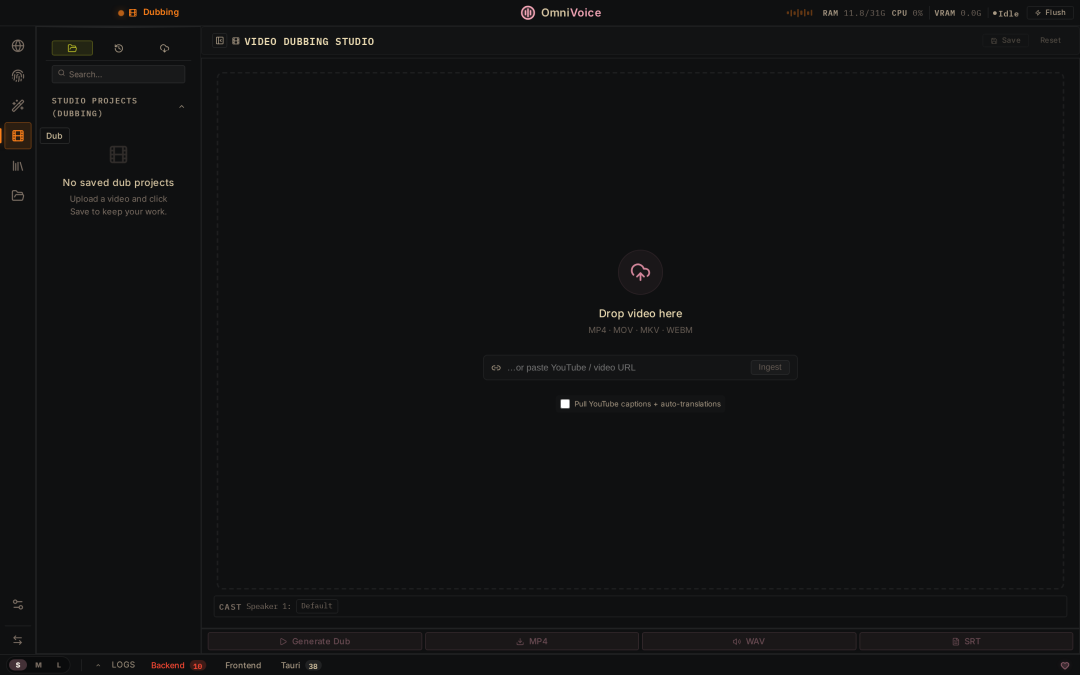
- 电影级视频自动翻配:集成多模态管线,支持直接导入YouTube链接或本地MP4,系统会自动分离人声和背景音,然后进行说话人识别和文本切片,随后一键用克隆音色重组输出新语言的视频。
- 全局悬浮听写组件:按下全局快捷键唤起毛玻璃悬浮窗,直接说话,系统通过本地WebSocket进行流式语音识别,自动把文字粘贴到你当前光标所在的任何输入框内。
- 原生支持MCP:内置MCP服务端,让你可以直接在 Claude Desktop、Cursor或其他AI Agent客户端中一键配置、直接调用本地的OmniVoice语音能力。
- 多后端引擎、极低硬件门槛:除了默认模型,系统还原生集成了阿里CosyVoice 3、针对苹果M芯片优化的MLX-Audio(内含Kokoro、Qwen3-TTS)等后端。内置显存智能感知离线机制,在显存小于8G 时会自动将TTS模型移出显存由CPU接管,彻底杜绝 显存溢出崩溃。
https://github.com/debpalash/OmniVoice-Studio

© 版权声明
文章版权归作者所有,未经允许请勿转载。


