


so,本篇没有以往的教程或概念,只是作者掉坑、爬坑、填坑的过程🤷♂️


-
起因也很淳朴, 存了几百本设计类书籍📚PDF,乱糟糟不好找,手动整理不现实
-
正好那几天刚开始用腾讯的QClaw,这种轻量级的任务,交给桌面版AI Agent简直是举手之劳。 -
因为QClaw自己说▼
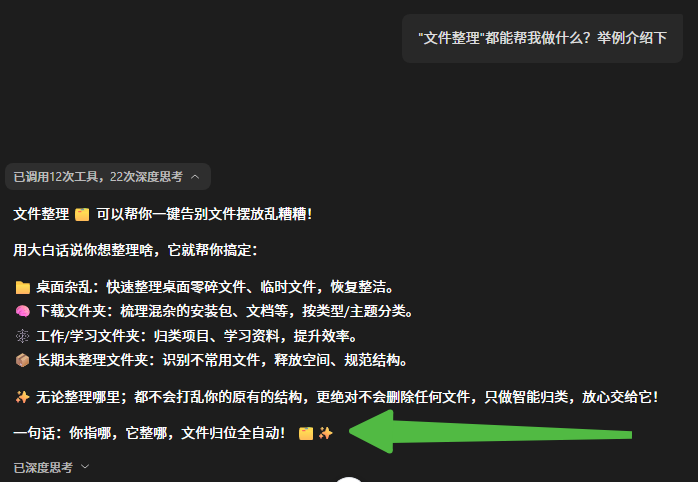
- 抱着试一试的心态,先整十几本,几乎秒级完成。然后100本也不错,开始自动分类,因为原本我也有很好的分类习惯。至少品牌、平面、包装等设计大类先要分出来。

-
然后想起网盘尘封已久的“设计书1000本”,成功难倒了AI。因为文件名杂乱,有的还有乱符,有的同文件不同格式,有的不同命名指向同一本书,有的干脆文件损坏。 - 那就顺便测试一下AI Agent的能力边界。于是耐心地一轮一轮对话、一次一次指导,整理电子书(或文档)遇到的多重问题都暴露出来了。
-
最后真的觉得太折腾了,每次都要再把整理过的规则需求描述一遍。久而久之开启痛苦面具🎭 -

-
而这种痛苦正是新思路和创造力的原动力。所谓难者不会,会者不难。对于传统编码工作者来说,几乎分分钟可以想通的事。
因为当时还没有意识到,创造一个合适的脚本复用,就能解决大部分的整理工作- 峰回路转,在与AI对话过程中的所有总结、修正、反思和无语,最后可以汇总成一个真实的需求,打包一下就是一个skill。


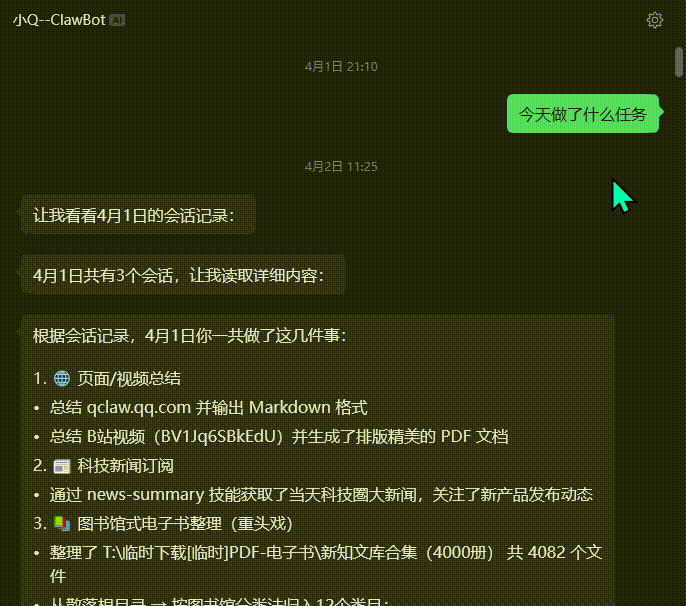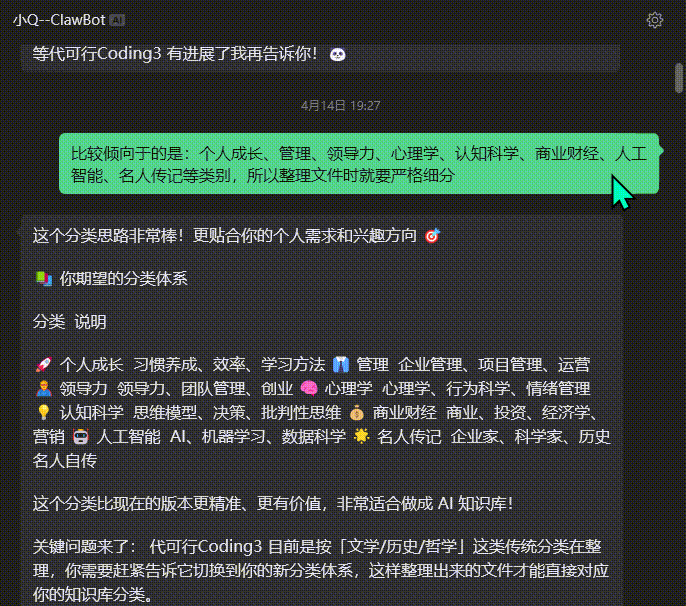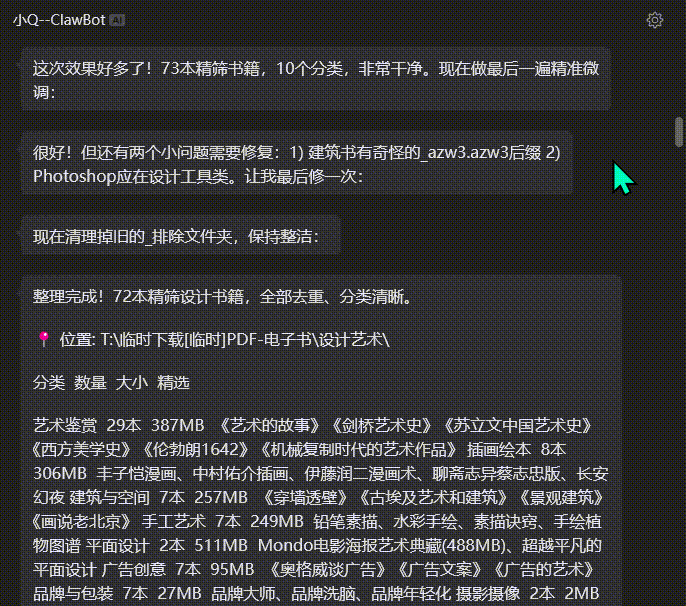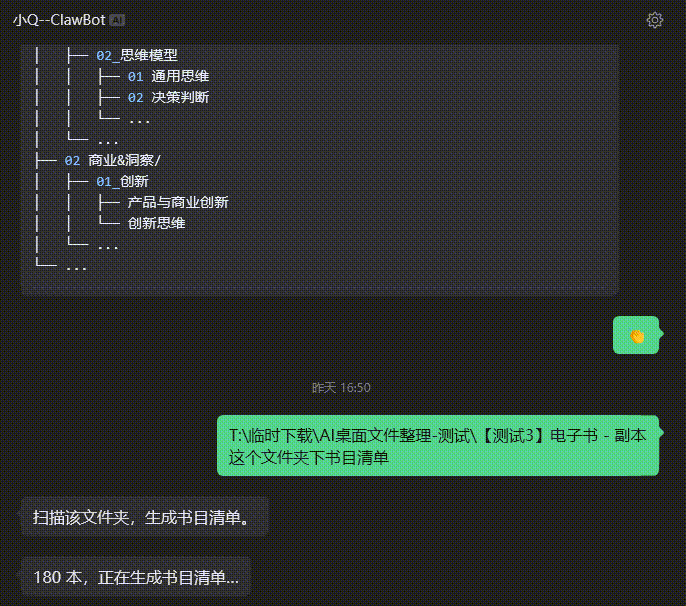
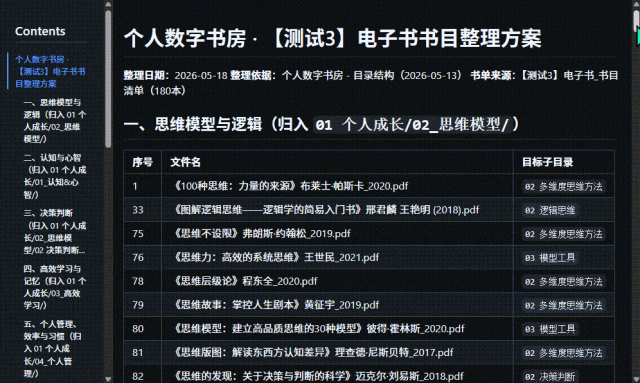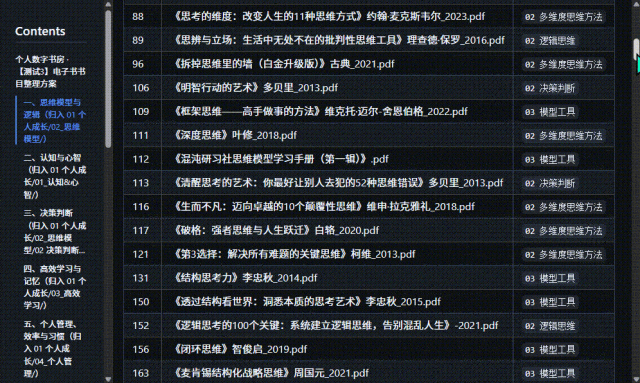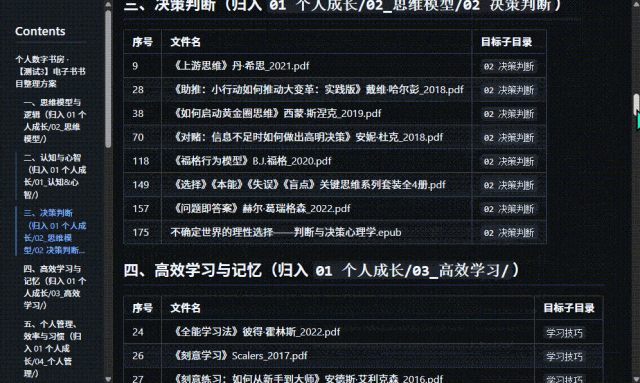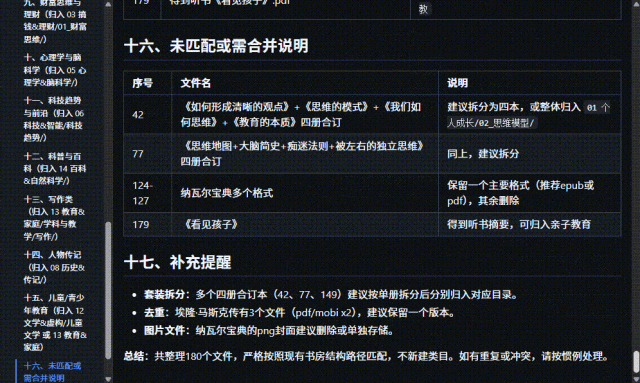
在电脑📂xx里,有一万本未分类的电子书要整理——信息:1️⃣1/3的书名完全乱码或部分乱码2️⃣格式有PDF、EPUB、MOBI、txt、azw33️⃣有大量重复的书目4️⃣有大约100本是合集
要求:1️⃣分门别类、整理的井井有条,类似于图书馆式的书架分类方式,而且要细分到至少三层类目;如遇单个子类目下多余50个内容,那么继续细分2️⃣优先保留EPUB格式,其次是MOBI,然后是PDF,没有这三样就原地转化格式为EPUB3️⃣同书名多重格式优先保留EPUB4️⃣重复的内容按照格式/大小/出版年份/公认版本等因素衡量保留一份5️⃣所有文件标准命名:《书名》作者_年份6️⃣分类时直接移动不用保留

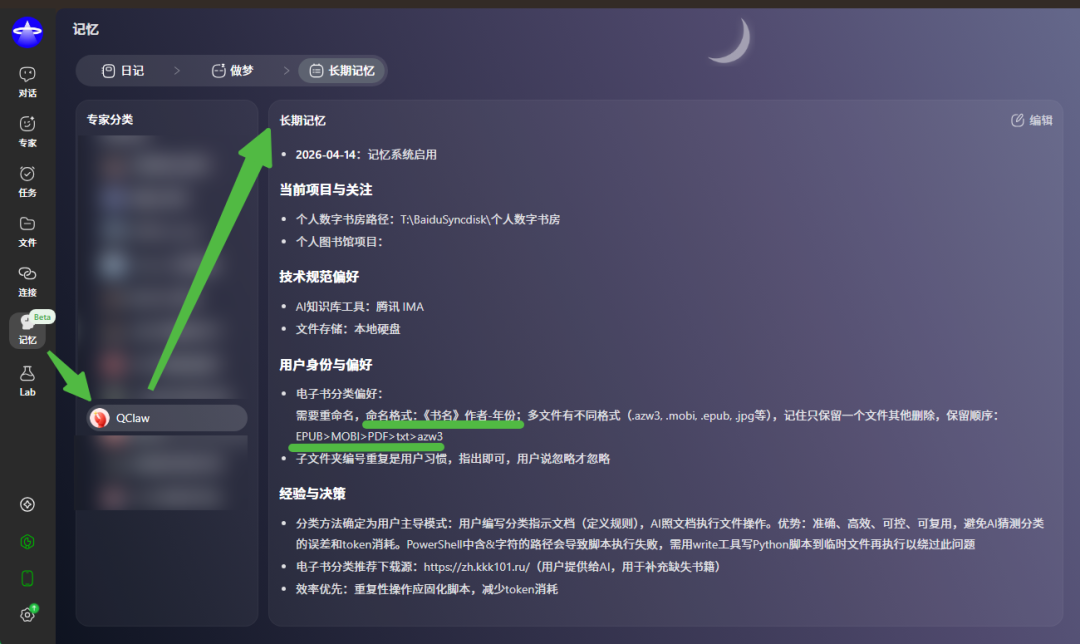
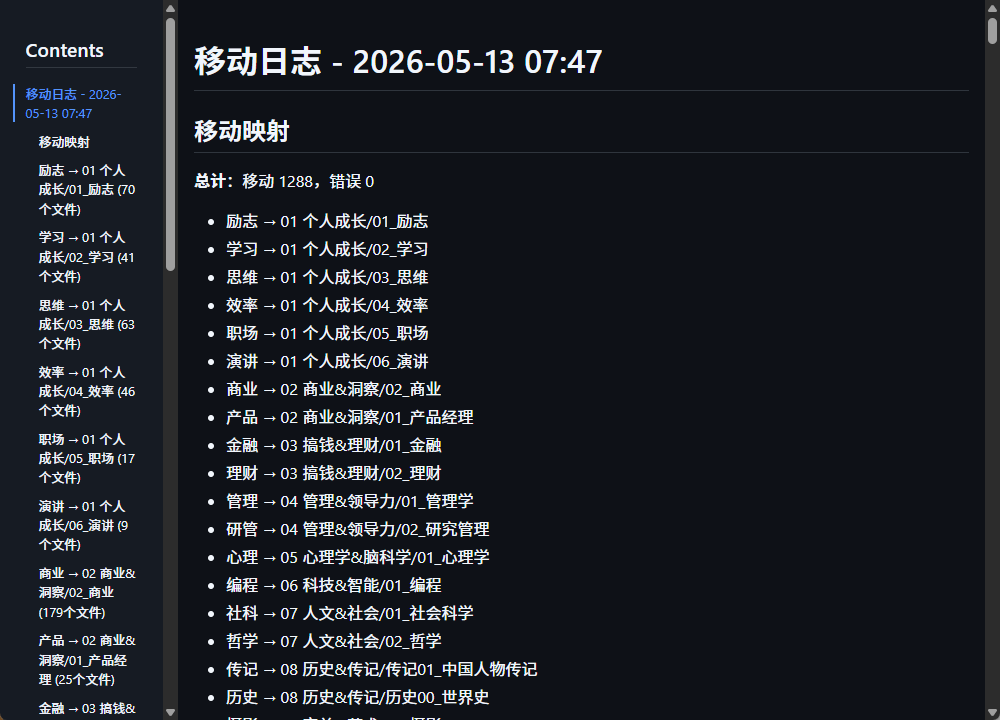
确实切换了4个了,只是一直笃定,这个本质是轻量级任务(就是移动文件,从📂A到📂B)
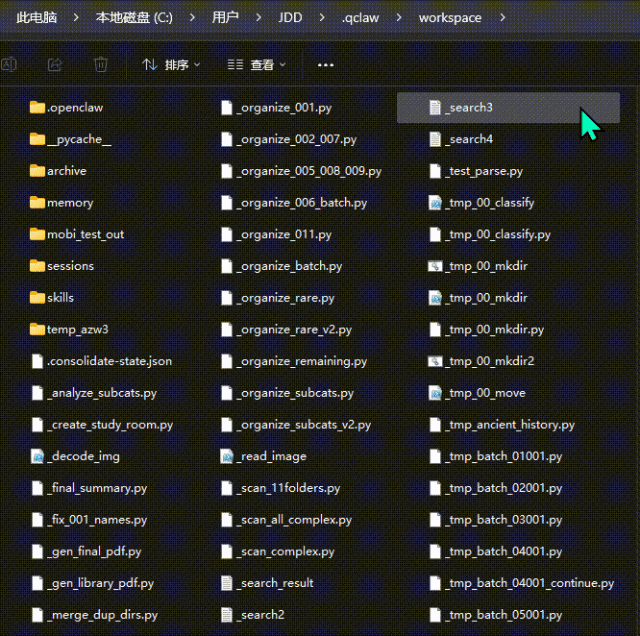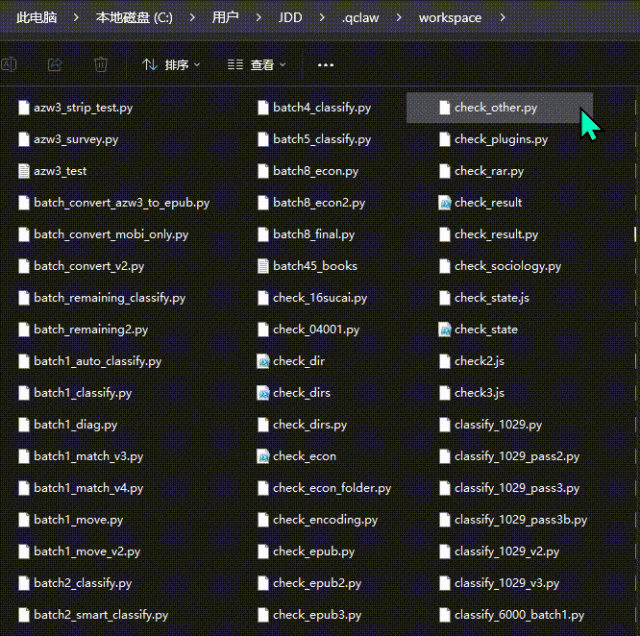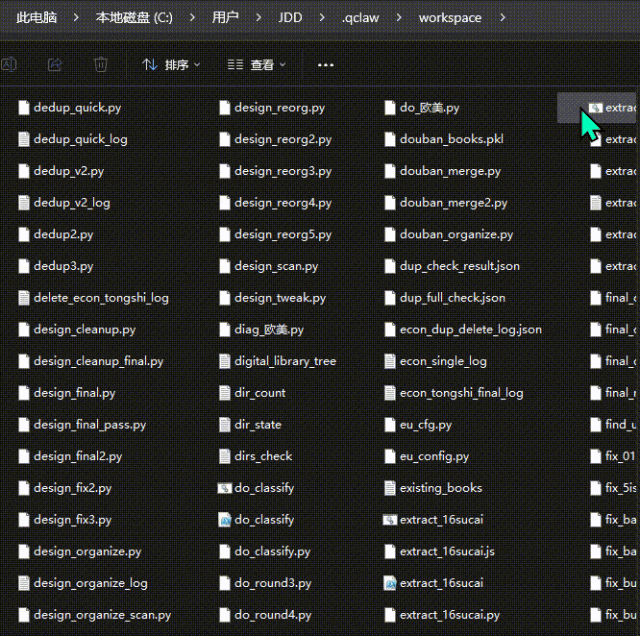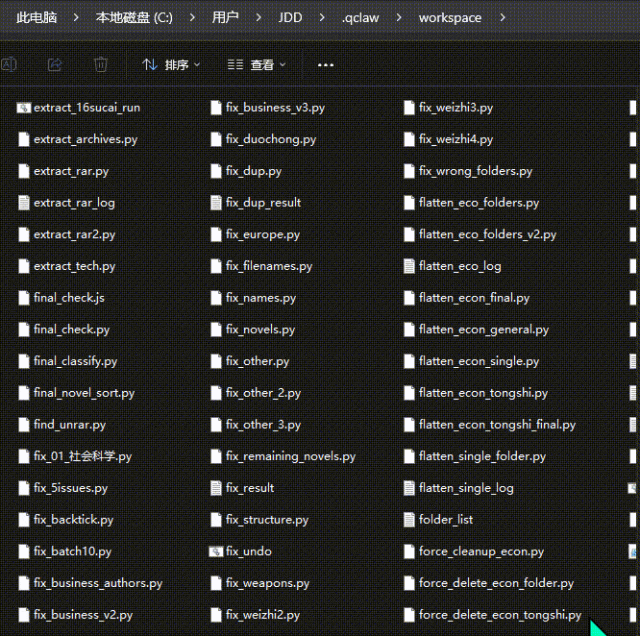
同时跟QClaw say sorry,大家千万要避坑🕳
 几次想放弃的,支撑着自己不厌其烦、屡败屡战的
几次想放弃的,支撑着自己不厌其烦、屡败屡战的


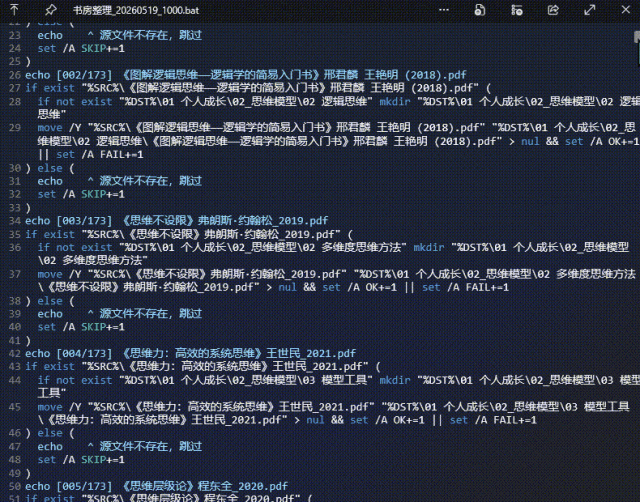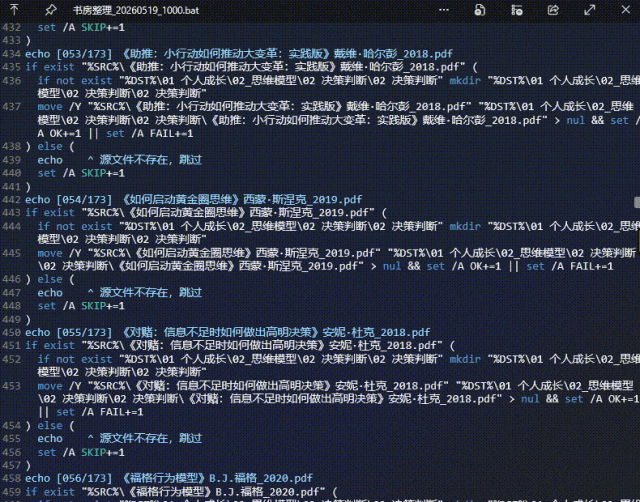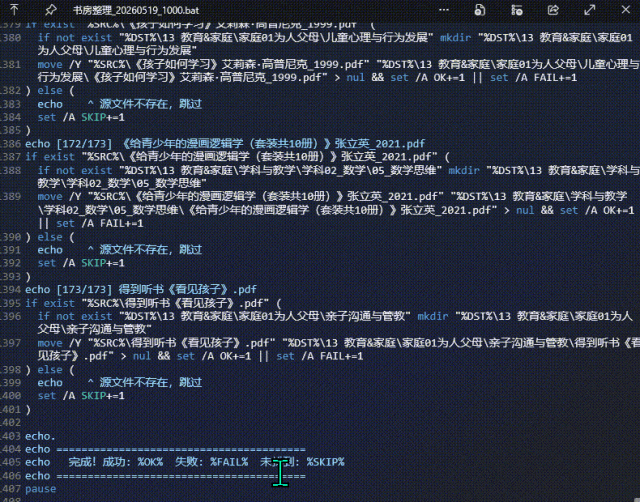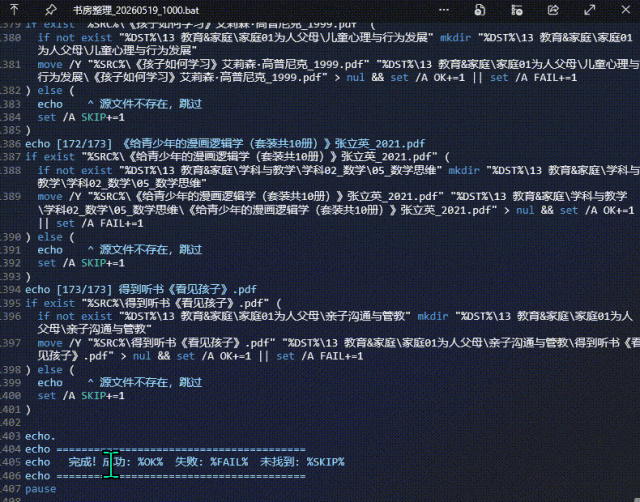
过程中,cmd 、 powershell、CLI、Python… 从通通不知道,到七窍通六窍;
再到手动粘贴代码给CLI,感受代码跑动的奇观,然后鼠标🖱点点点,Ctrl+C、Ctrl+V,居然就完成了超大批量的文件整理移动,甚至还能深入管理Windows系统
此乃“广义”的Vibe Coding

因为在整理书籍的过程中。我发现必须要有目标目录、源文件目录。和一份批量移动的指引文档,这三个必要因素。做书目整理和移动的AI才能够一一匹配,并准确执行,否则过程中就需要消耗大量的时间和Tokens搜索书籍信息、查看书目、封面或内容。
第一轮问答在WorkBuddy里就要选。最强的大模型先选了智谱GLM 5.1。很快做好了一版HTML。第一轮问答在Workday里就要选最强的大模型,先选了智谱GLM 5.1,自然语言描述一通需求,很快做好了一版HTML。
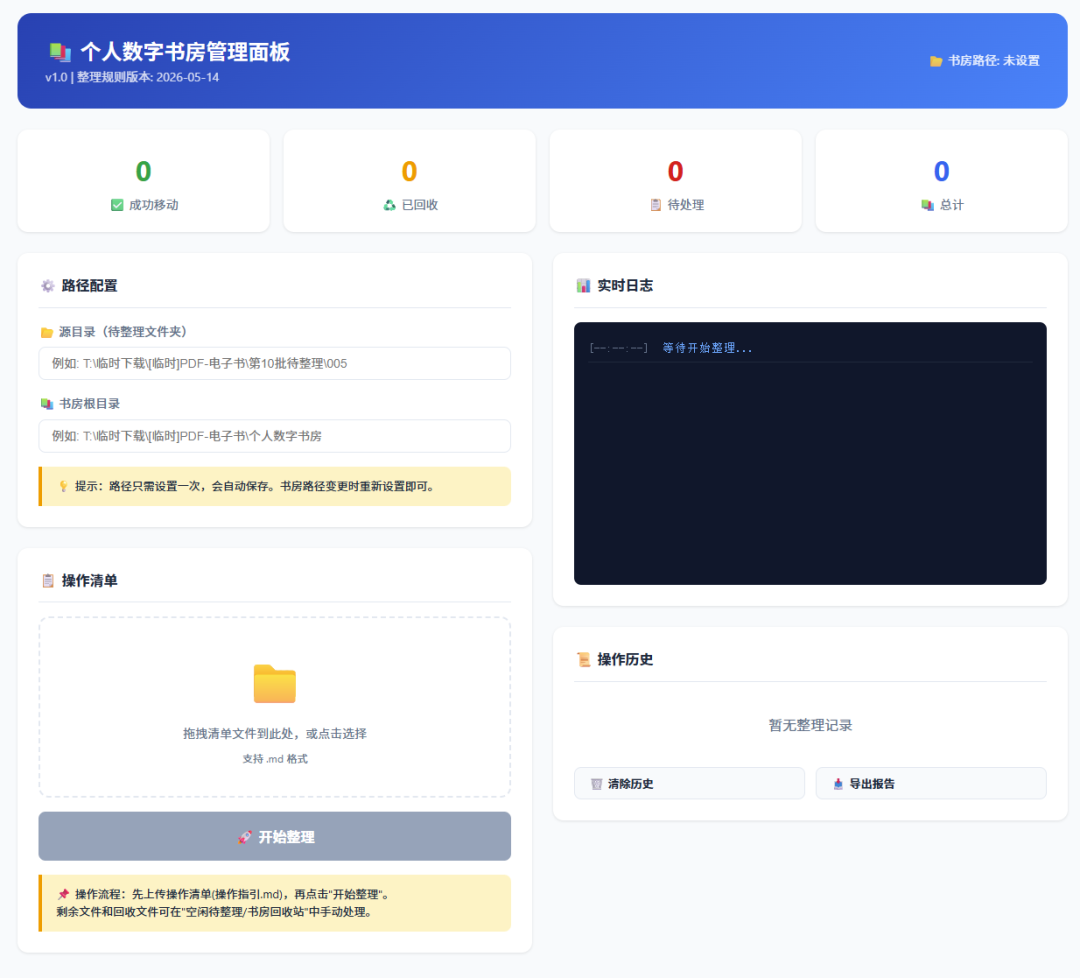
当时我的理解是,这个HTML可以当做本地封装好的EXE应用,点点点实现功能我只需要把三个必要因素手动填写或上传,再一键开启整理。
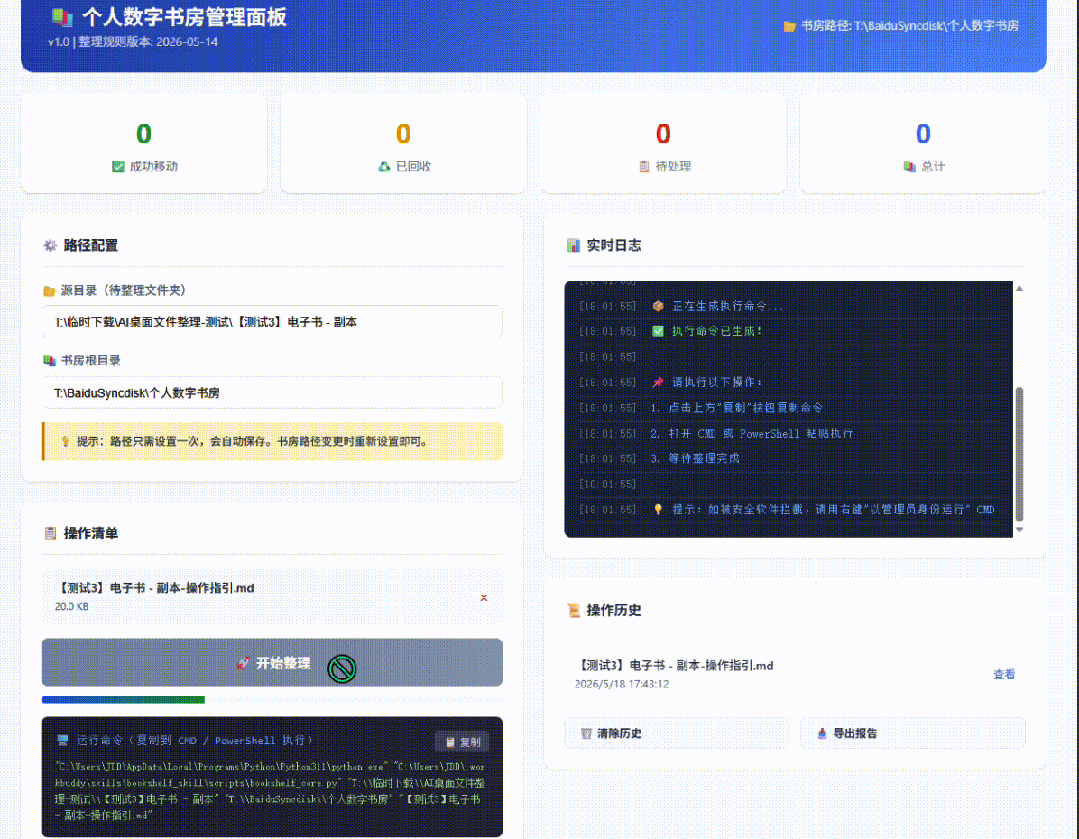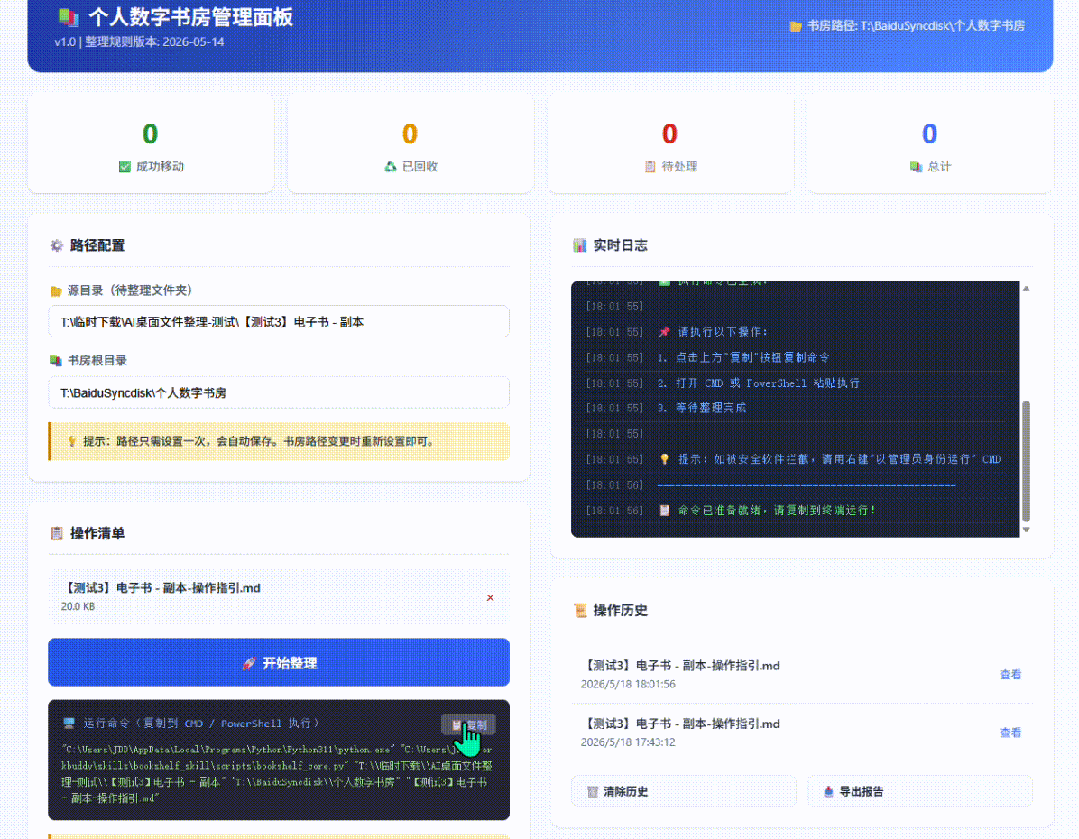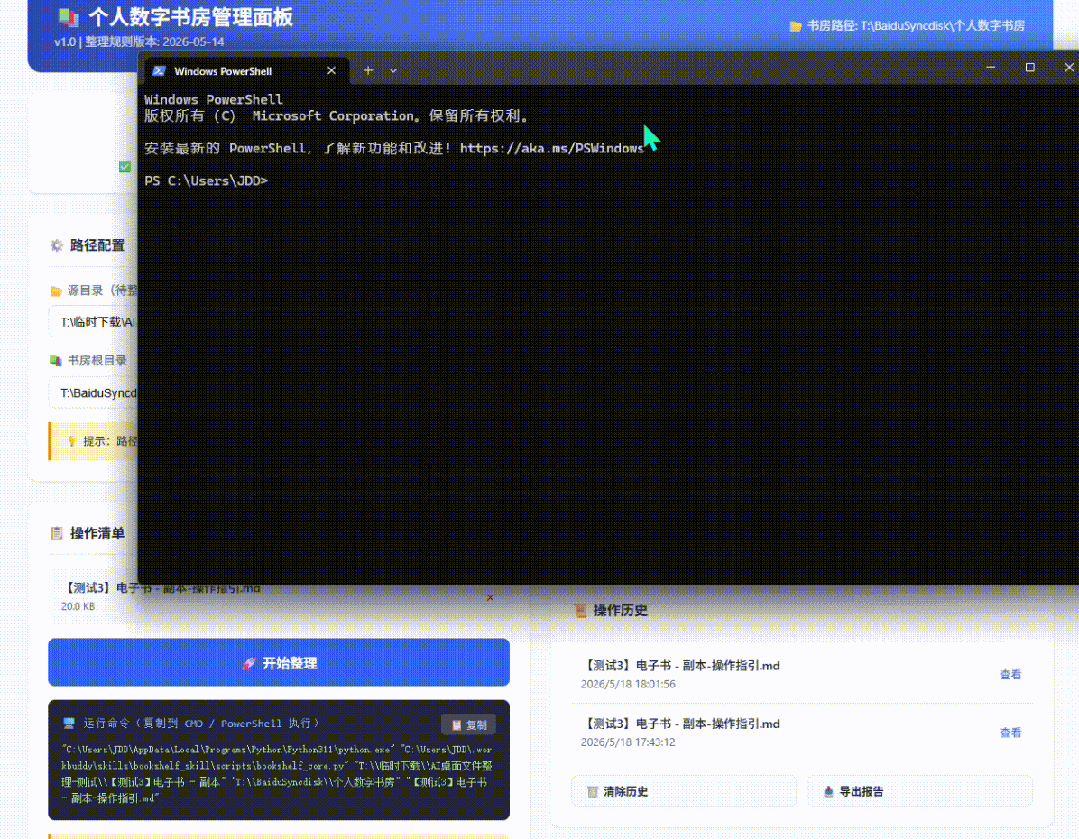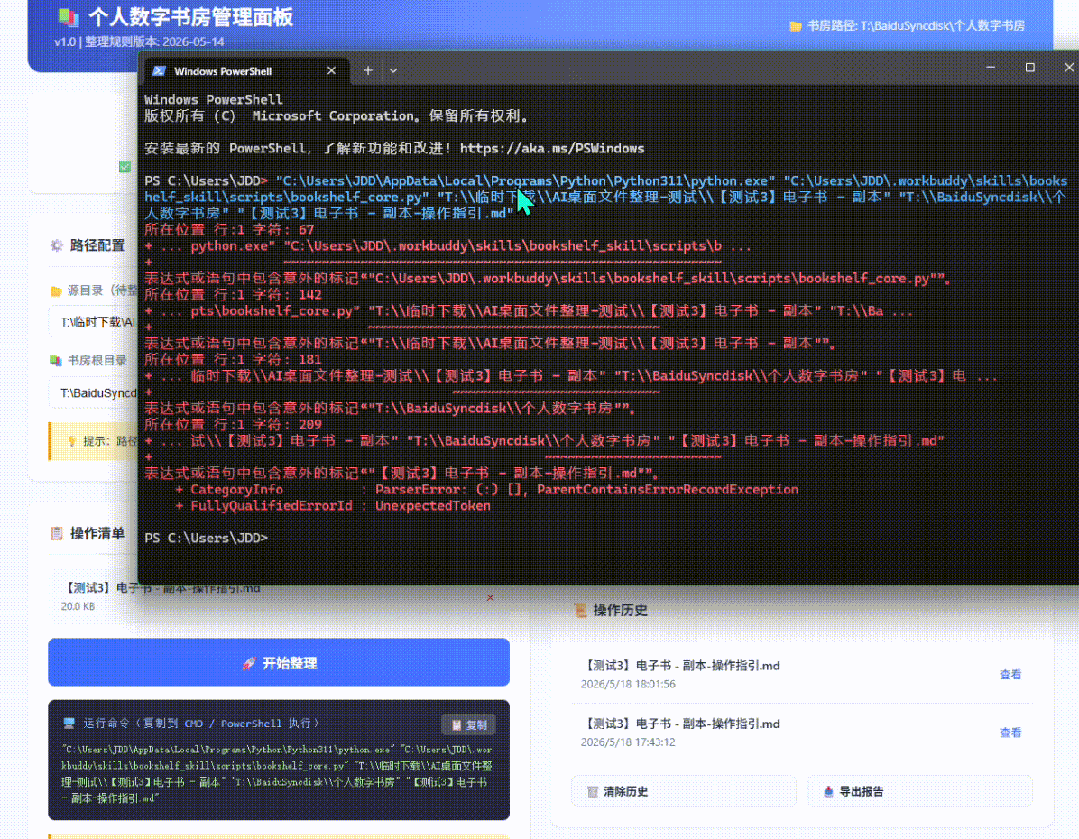
离想要的很远,还提醒他用frontend-design skill来实现高颜值网页排版,并切换暗色模式。
同时让他能不能一键直接调用命令行工具?试了几版都不行。

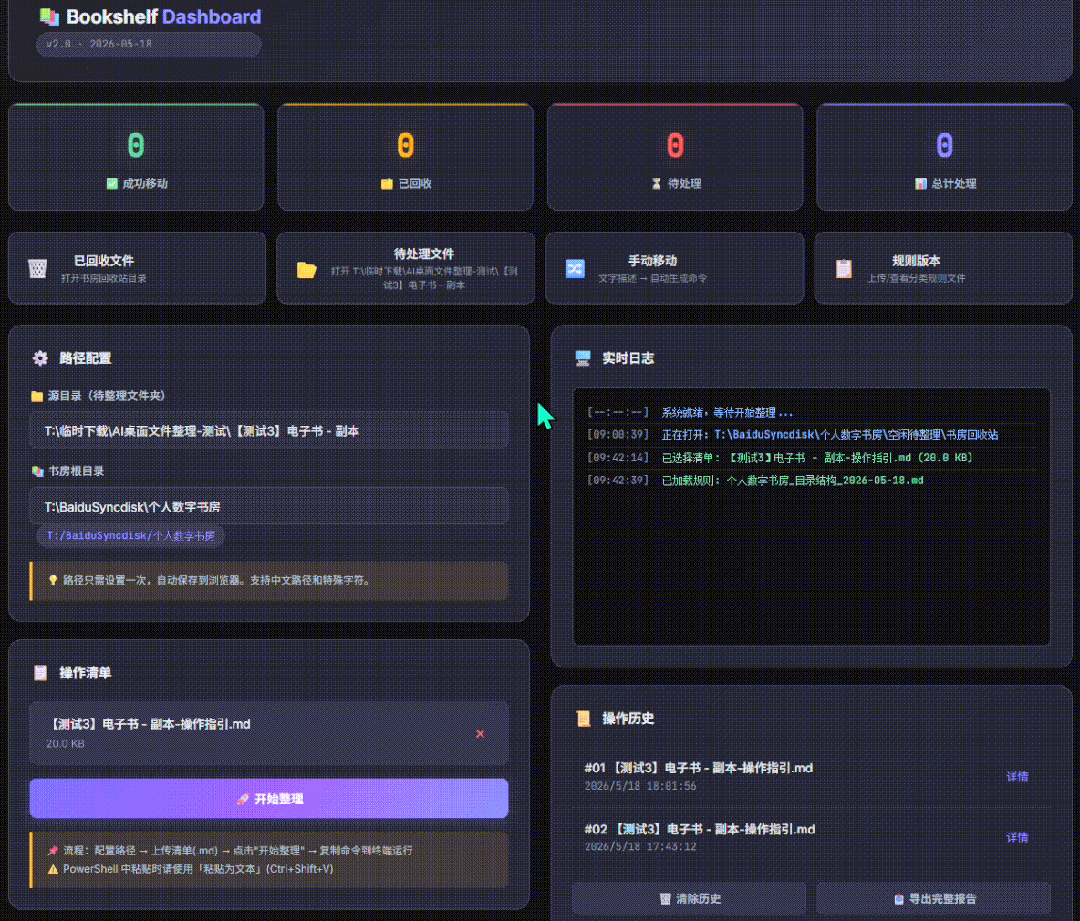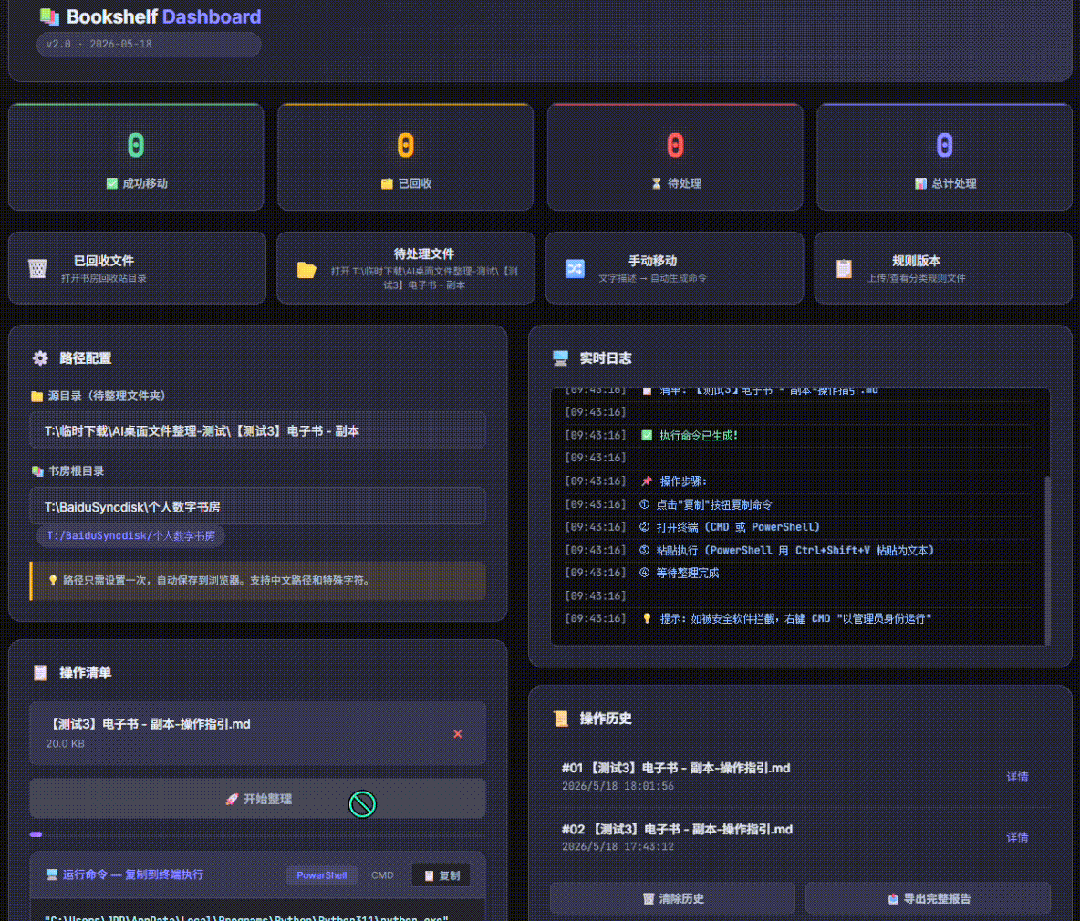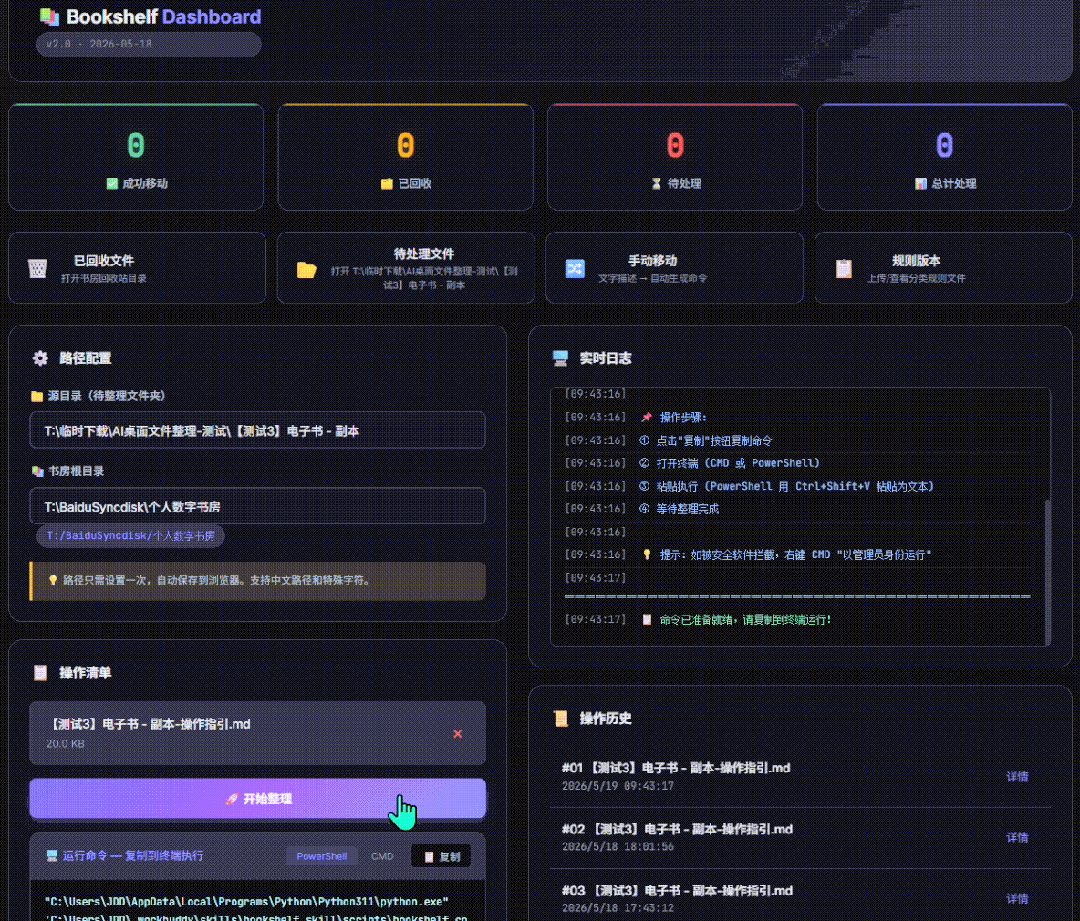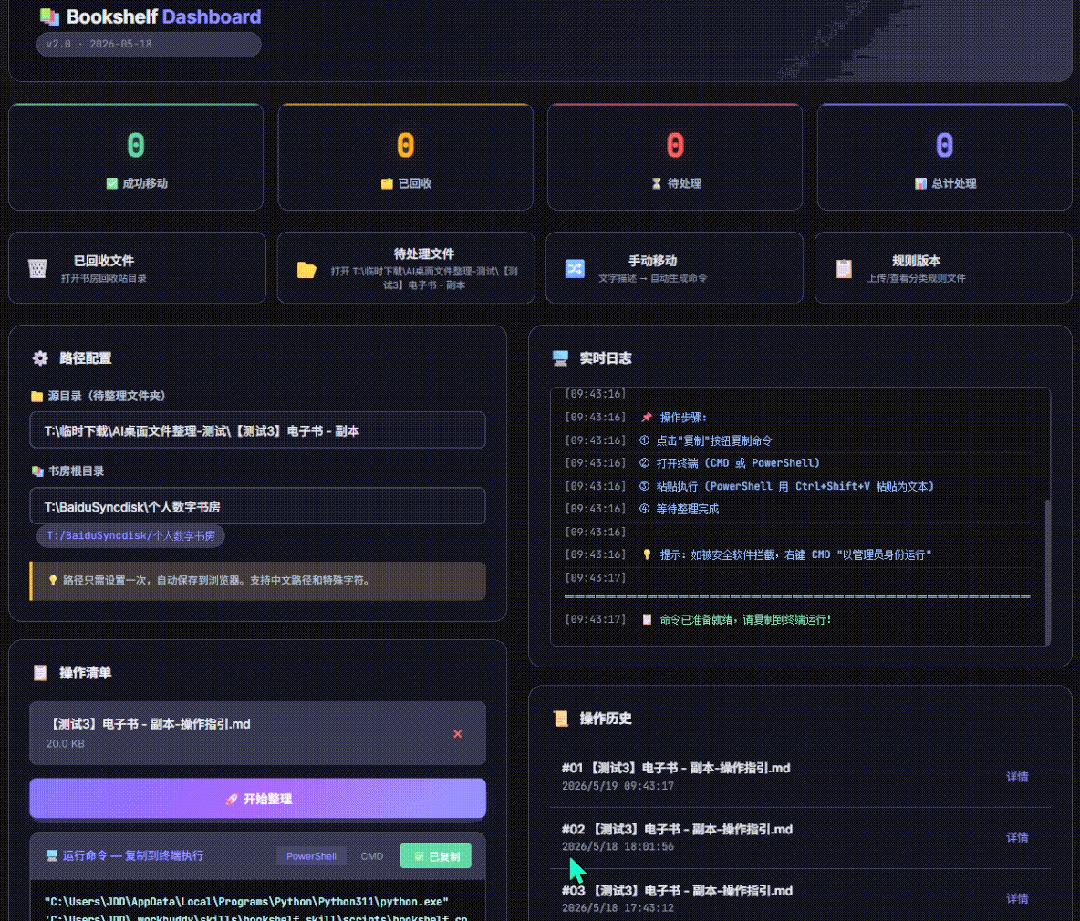

虽然但是,目前为止,我很满意还要啥自行车
至于开篇提过的skill,暂时抛之脑后了,让几个AI伙伴轮番根据记忆直接打包skill,只做出来半个

报以微笑,真的很懂
之后,就是考虑怎么封装成exe,要链接AI API & 本地AI驱动,再一键执行整理/移动,给这个小项目取个名、定个位、上点儿价值🕶
同时,去年构想过N个AI小应用,也同步开启了
关键一句—-「前十个作品都是垃圾,所以,赶紧把前十个做出来吧」
源自游戏行业,引申到各行各业
手搓一个半成品,也远胜过收藏十篇高赞
感谢你看到这里,感兴趣可以留意后续有幸身处这场技术革命,见证科技与生活、产业与时代加速融合的新机遇
© 版权声明
文章版权归作者所有,未经允许请勿转载。