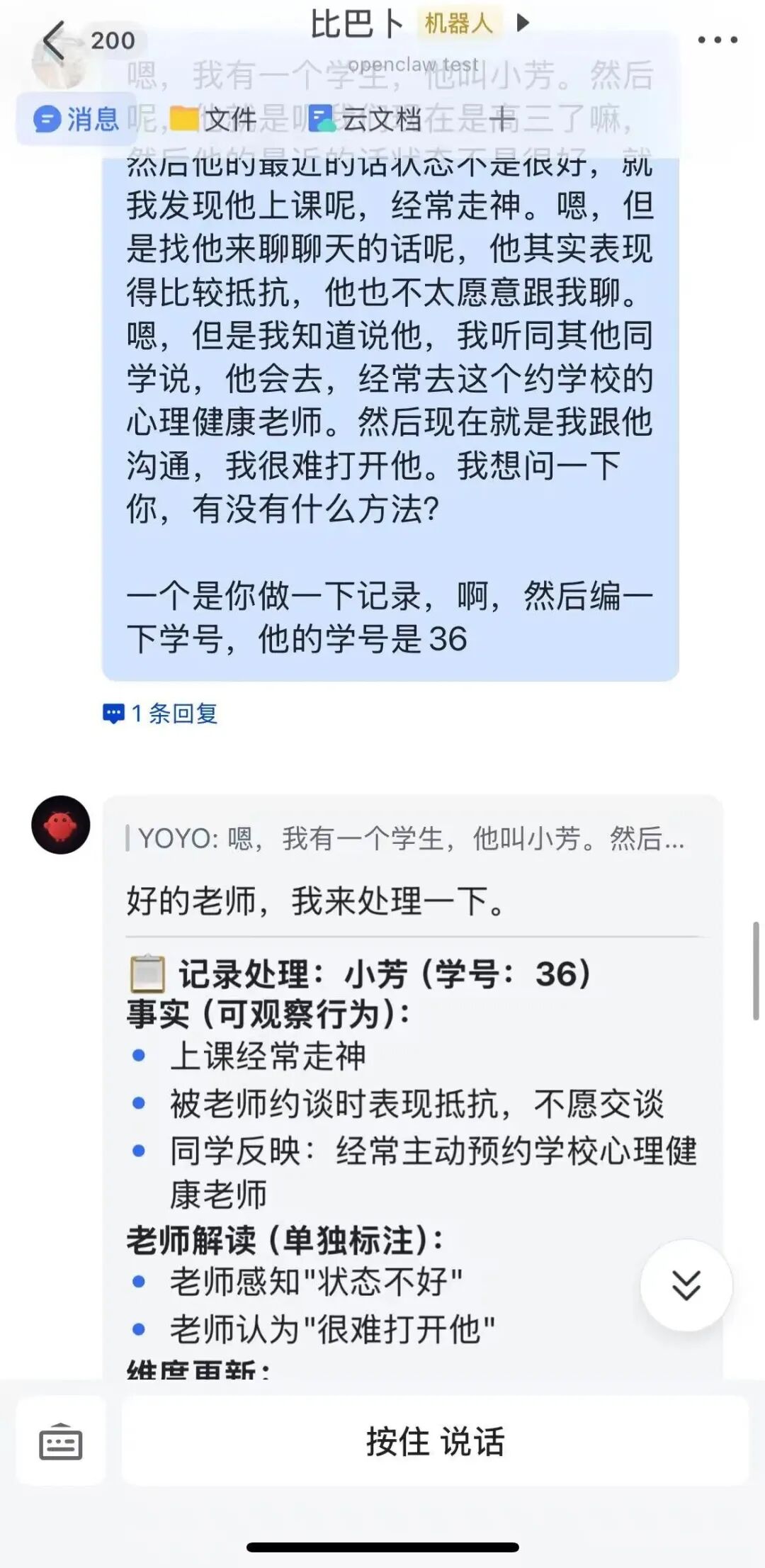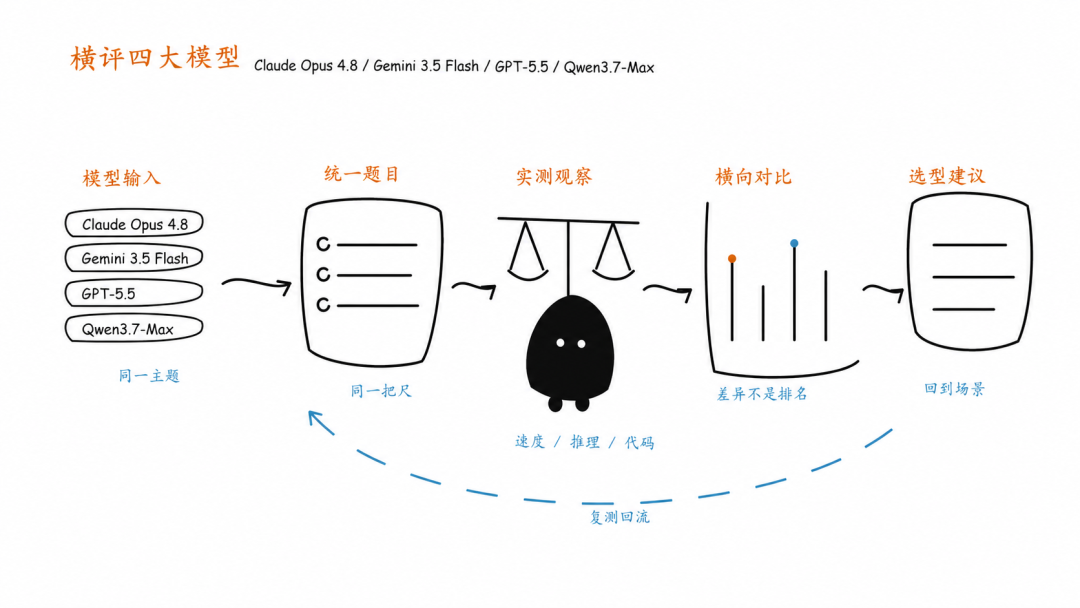
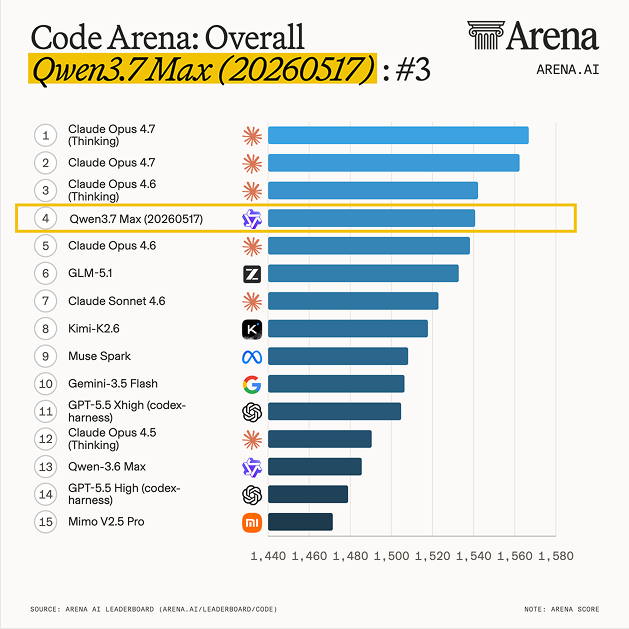
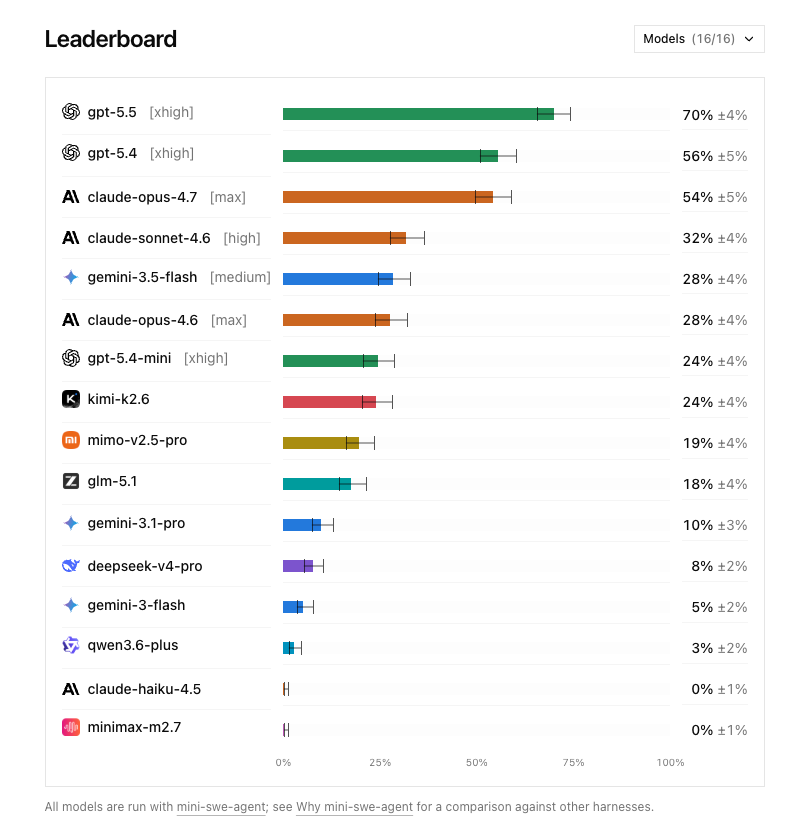
我挑了四款最近讨论度很高的模型:Claude Opus 4.8、Gemini 3.5 Flash、GPT-5.5、Qwen3.7-Max,做一次横评,看看它们在真实任务里的交付表现。

- 案例1:长文档精读


- 案例2:任务规划
- 案例3:代码修复

- 案例4:中文写作




- 案例5:数据分析

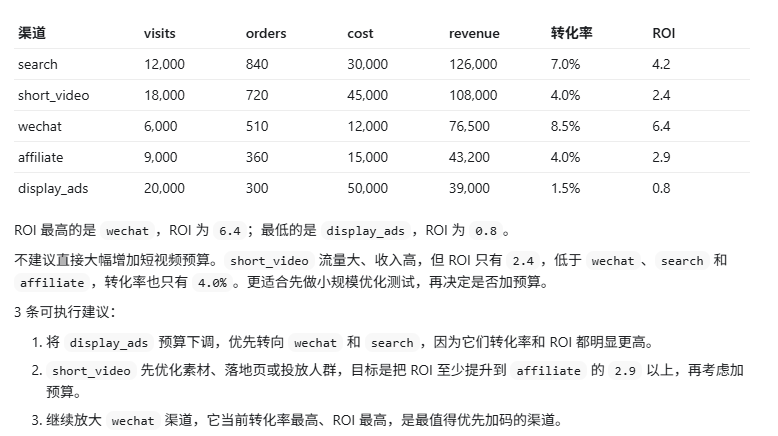

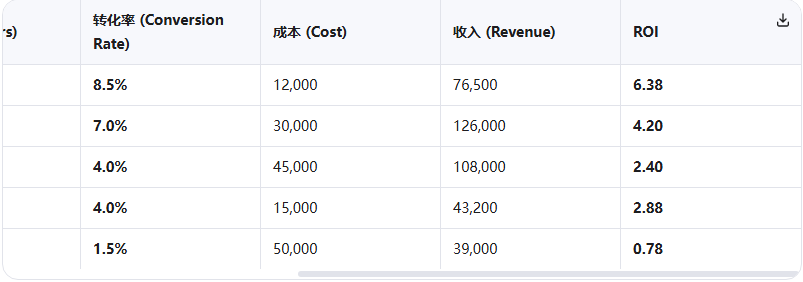
- 案例6:指令遵循压力测试



- 案例7:svg 图coding测试




这次测试里,很多模型不是不会做,而是容易在某个环节出问题:有的会改业务逻辑,有的会多输出格式,有的会把推测写成事实,有的会算对但排序错。所以,真正会用 AI,不是把任务一丢就完事,而是知道每个模型适合放在哪个位置。模型竞争已经从“参数和榜单”进入“真实任务交付”阶段。以后大家不会只关心某个模型在 benchmark 上高了几分,而是会更关心:它能不能稳定调用工具,能不能遵守格式,能不能处理长任务,能不能在复杂工作流里少出错。未来可能不会是一个模型通吃所有场景,而是多模型协作:一个负责深度分析,一个负责稳定输出,一个负责中文表达,一个负责视觉和代码生成。所以这次横评下来,我的最终建议是:别只看排行榜,也别只听发布会。
拿自己的真实任务跑一遍,才知道哪个模型真的适合你。
© 版权声明
文章版权归作者所有,未经允许请勿转载。