
没多久就收到一句吐槽,这14个Skill组合起来太啰嗦了,还烧Token。确实这是我这段时间一直在想解决问题,好的Skill很多,但很多时候都是让Agent去盲选调用顺序。
Superpowers三个月前还是10万star,现在又翻倍了虽然它在Readme里面塞了一个基本工作流,但是我并不是每一次调用都需要那么多skill的。想来想去,还是每个人按照自己的习惯,安排一套这个skill的调用顺序最合适。

而且把Skills定好调用顺序之后,我还可以把其他框架上跟它重叠但不重复的技能纳入到这个工作流里面。比方说我就很喜欢在开发流程的最后一句触发compound里面的持续学习。

这个问题可以被具体化成,
到底该怎么用这一组Skill?一组Skill就像一个百宝工具箱。你知道我知道大家都知道里面有好东西,但每次执行的时候,还是得判断今天该用哪个,顺序是什么,要不要全塞进上下文,哪些步骤可以跳过等等等等。更麻烦的是,每读一个Skill的说明烧的都是我的TOKEN啊,Agent自己不心疼,我心疼。这种麻烦在最近狂用Codex的/goal命令的时候达到了顶点,我的周额度居然在周五就没了,重生之72小时我成古法手写程序猿了属于是。这两天在GitHub上大搜特搜省TOKEN还不降模型智商和体验的项目,Bad case是这个,说是会给Claude Code剩下65%的TOKEN,结果给我Claude干成呆瓜了。
还有一种新玩法是从Skills的组织入手的,叫做,OpenSquilla他把多个Skills组织抽象成了Meta Skill。普通Skill解决的是,我会什么。
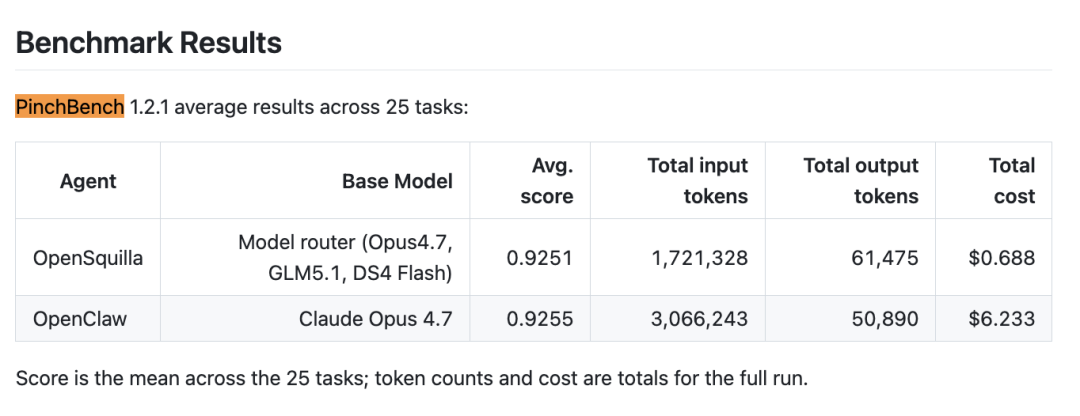
Meta Skill解决的是,现在这个任务,我该怎么把这些能力串起来。先做哪一步,后做哪一步,哪一步依赖前一步,哪一步没完成就别往下跑。不过这个项目跟OpenClaw比star差了快两百倍,所以我们还是先来看看纸面实力,在PinchBench 1.2.1上,三个模型混着用的OpenSquilla跟Claude Opus 4.7版的OpenClaw得分几乎一样,但Token少了将近一半,成本不到1/9。
超光速看了一下项目代码,一个很突出的差异点是,OpenSquilla的Meta Skill会让我们多写一份SKILL.md。这份文件不是一段提示词。它是在用YAML定义MetaSkill的步骤、顺序和依赖。
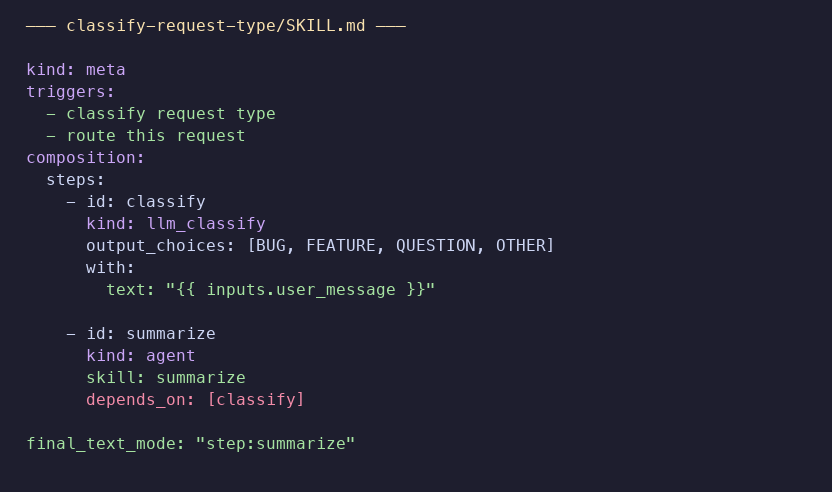
看到depends_on: [classify]了吧,翻译成人话,就是先给输入做分类,是bug,提问,还是其他情况。没分完类,就不准往下走。看到的时候我第一反应是,这不就是写了一套rules吗?区别在硬约束,rules靠模型自觉,上下文一长,模型就可能突破约束。MetaSkill不一样,它会在Runtime层先检查一遍。步骤顺序对不对,依赖有没有闭环,权限够不够。通不过校验,0次API调用,一分钱都花不着。
为了测试我故意写了一个坏依赖,depends_on: [missing_step],指向一个不存在的步骤。真就直接在Plan Validation阶段拦截了,连LLM调用都没发出去。

以前我们是靠写Rules让模型遵守约定。现在变成了先用代码转一圈看看,这条工作流本身成立吗?
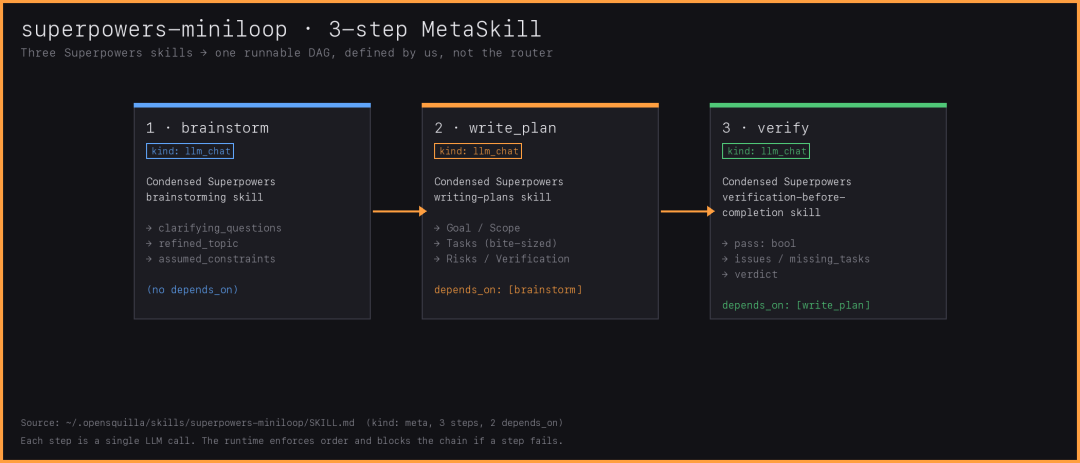
那我直接上手把把Superpowers底下Skills组合做成Meta Skill,brainstorm负责想需求,write_plan负责写计划,verify负责检查风险,作为我日常的固定搭配流程。打包成一个Meta Skill后就不需要Agent每次来考虑这次需不需要,一套流程定下来,跟着规定走,不能遗漏也不能跳步。用同一个提示语任务测了三轮,提示语都是搜索3个2026年AI agent跑生产环境的风险,再写一段给工程经理看的总结。能看出来有没有Meta Skill差距还是蛮大的,
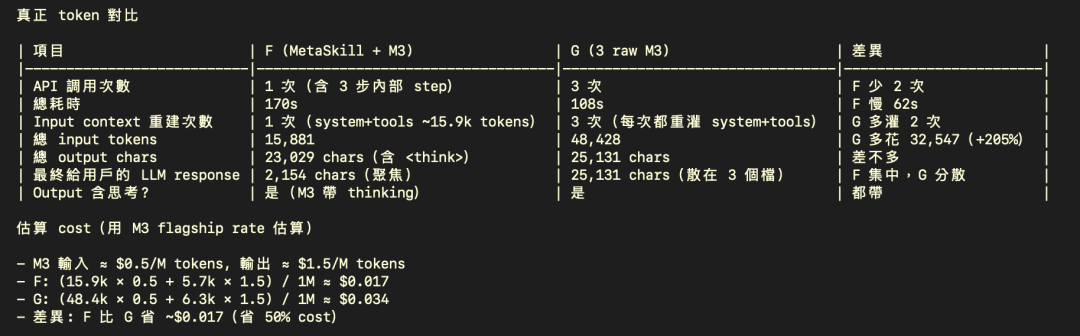
同样是成功跑完了内容,Meta Skill把输入TOKEN就压到67%。每一步思考过程减少了,也不再把Token消耗在迁移途中的说明上,用人话说的话,它用更长的前置运行时间,换来更少的重复上下文消耗。

对于模型切换 ,OpenSquilla支持多家模型,自带了一个本地小模型,我发的请求在要发给干活的大模型之前会先做个分类是简单还是复杂任务。不过这个模型切换只能在是在新开session或者新建立对话情况下才实现。
我觉得还是为了切起来够稳定,如果在同一个Session中频繁换模型,很容易就会出现上下文缓存,工具格式和日志混乱等等问题。主要是我心痛我Claude的一小时缓存。还有,我留意到一个细节,OpenSquilla用子Agent去理解和压缩上下文,也就是说在一个上下文是 400K左右的模型,到了300多接近400K的时候,还是能够能记住我之前说的点。提示语长这样,
我:设计一个 AI Agent 的测试计划,包含安装流程、功能测试、失败场景、评分标准和结论。输出为结构化 Markdown。🦐:生成的文件已准备就绪:ai-agent-test-plan.md✅我:Search the web for the latest AI agent frameworks newsin2026, fetch3pages, then writeastructured reportcomparing them inatable.Include pros/cons and pricing.🦐:(自动触发 web_search → web_fetch ×3→ 生成报告)输出:一份包含8个框架的对比分析报告Claude Agent SDK、OpenAI Agents SDK、Google ADK、LangGraph、CrewAI、Smolagents、PydanticAI、AutoGen含 ExecutiveSummary、Key Findings、对比表、协议矩阵、局限性分析

同一个对话里,从你是谁到写一份8个框架的调研报告,全跑通没有忘记上下文。并且在话题结束,给出一份巨巨巨详细的花销明细。
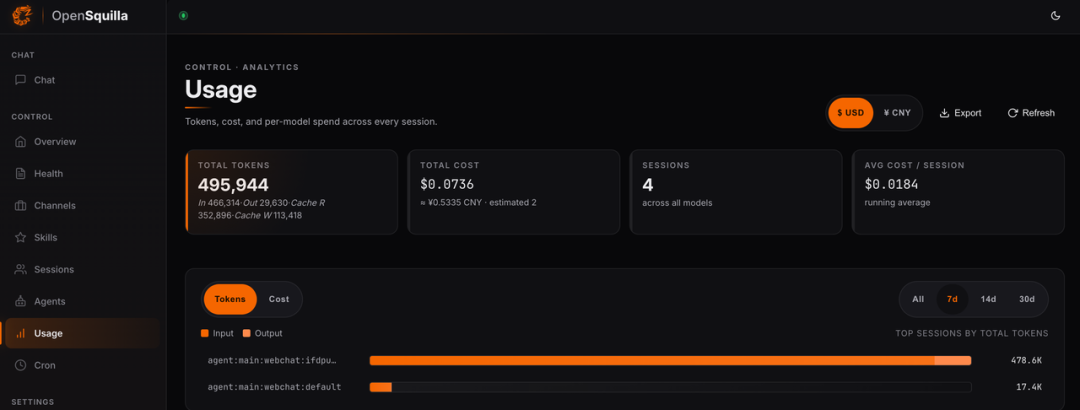
从自我介绍到8框架竞品报告,同一会话花了7美分都花在哪了。
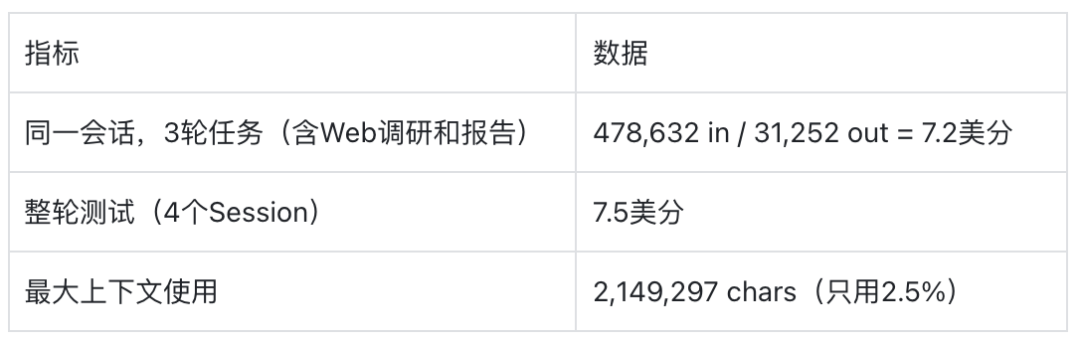
OpenSquilla把这一切都摊开了。每个Session的Token数和成本精确到小数点后四位。这一轮测下来,只能说星不可貌相啊,全是狠活。过去半年,Agent是先卷模型,再卷MCP,接着卷Skill。Skill都卷到Clawhub上有6w多了,正常一个Agent也就常用的也就50个70个。
可能挑了很久,终于选了一个Skill带回家,但过几天,新的又来了,旧Skills也就被忘了。但Agent每轮都还是会读旧Skills的说明书,对我来说过多的Skills只是散落在仓库里的文件,但Agent会因为Skills里内置的各种规则误导,规则加太少,Agent容易失去了方向,规则加太多,Agent就左脑打右脑了。真正拉开差距的,从来都不是谁的Skill更多,这跟一周能不能烧掉一亿token一样没有意义。能不能把Skill串成一条稳定的工作流,别让Agent在完全没有限制的空间里临场发挥。我们真正需要的是让它知道,第一步做什么,要不要继续。哪一步没必要,能不能省略。这一步的问题,要怎么定位。每次对话的下一次都能跑更稳定,把好的步骤做的更好,坏的Bug也不再发生。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


