
结果又蹲到了小米MiMo-V2.5-Pro的UltraSpeed模式实现了万亿参数推理模型输出速度1000token/s,这意味着这张图里所有模型都比这模型慢6倍以上。而且前段时间,V2.5-Pro还降价了99%,UltraSpeed模式虽然是普通版的 3 倍,但依然属于性价比之王的状态。
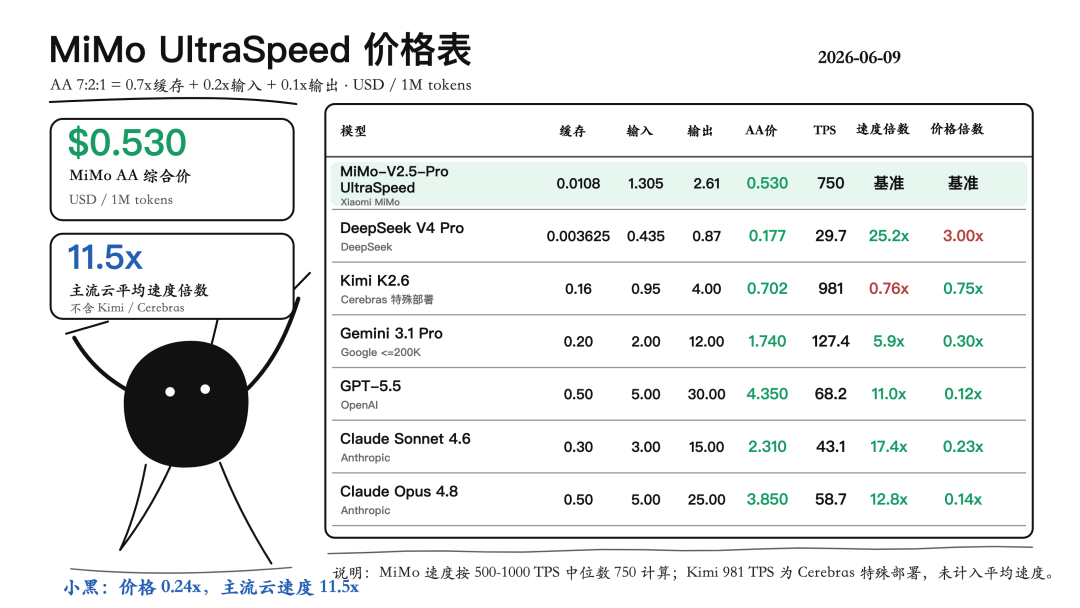
从图里看的话,Kimi K2.6的TPS也非常快,但981Token/s是Cerebras在自己的 Inference API 私有端点上跑出来的。简单来说,普通模型API通常跑在NVIDIA GPU集群上,速度卡在多卡之间搬权重、同步激活、做MoE的路由通信。Cerebras用的是Wafer-Scale Engine,可以理解成一整片晶圆级芯片系统,不是传统一张张GPU拼起来,片上的通信带宽超过NVLink NVL72的200倍以上。就,我一下子有点想到这个印象中很多年前可能是在节目上看到的,在直线加速车牵引下达到了296公里/时的自行车,MiMo-V2.5-Pro UltraSpeed模式下1000token/s的速度是在单8卡节点上跑出来的,相当于用一辆家用自行车蹬到了300公里/时。

那我只能说,Claude Code的动态工作流(Dynamic Workflows)引来了它真正的话事人了。马上开测,先来个几千token的网页生成提示语热热身,同一个提示语,我测试了三遍。基本上思考过程能够达到700以上 token/s,输出过程更是实实在在能比1000 token还要快,峰值一度打到了2140token/s。
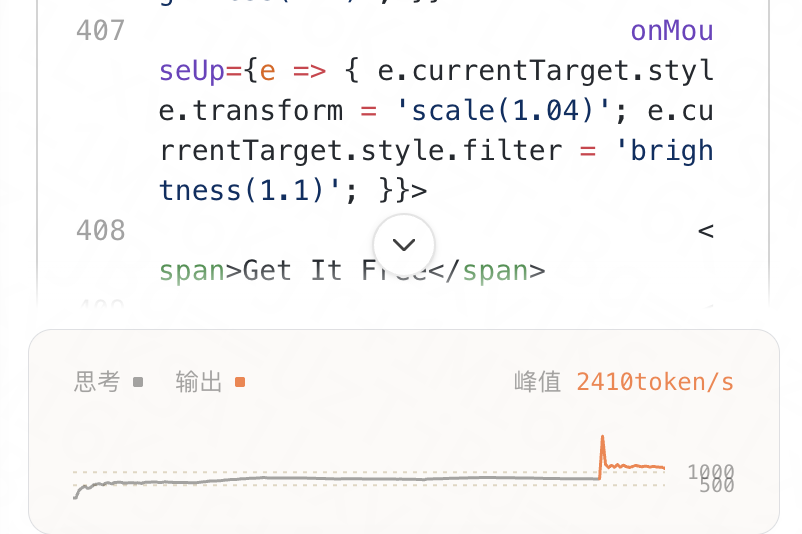
以后可能连起身冲咖啡,或者说发个提示语刷刷手机等生成的时间都没有了。把MiMo-V2.5-Pro接到Claude Code桌面版开UltraCode模式后,做出来网页在交互,不同尺寸的适配度都可以追上我用GPT5.5 high从零开发的版本。UltraCode模式出来后我平时不舍得让Claude Sonnet 4.6用,但是用太差的模型就算通过UltraCode模式烧大量的积分也不能一次性拿到满意的结果,反而会因为超长时间的推理浪费时间。
还有一个测模型3D能力的Prompt我也扔进去测了,要求不用任何库,创建一个包含全屏 canvas 的单 HTML 文件。我觉得效果还是挺明显的,包括按钮的灯光,从屏幕上方投影下来的灯光,以及按钮击中音符后人群欢呼的剪影,还有打满进度条之后的星光特效,都挺符合我对吉他英雄的记忆的。而且UltraSpeed模式下只用了3分钟就完成了。
当然只用来做个网页有点大材小用了,我在X上看到的用Claude Code动态工作流的都是用75万行代码整个Bun从Zig重写成Rust的,所以我干脆让开着UltraSpeed模式把我github上所有的项目读取了一遍,让MiMo-V2.5-Pro给我出一个升级报告,看看我要怎么降低skill的安装难度,以及普通人看到这个Skill后能不能一秒get到作用,还要给每个项目的readme(说明书)做成统一风格,还顺手给它发了我喜欢的几个Skill让它学习学习,主打一个来都来了,之前我有这个模糊的想法但是因为开发周期可能有点久还要犹豫犹豫,现在我想看看加速之后多久能完成。可以看到,直接就造了12个Agent来帮我完成这个复杂的计划。
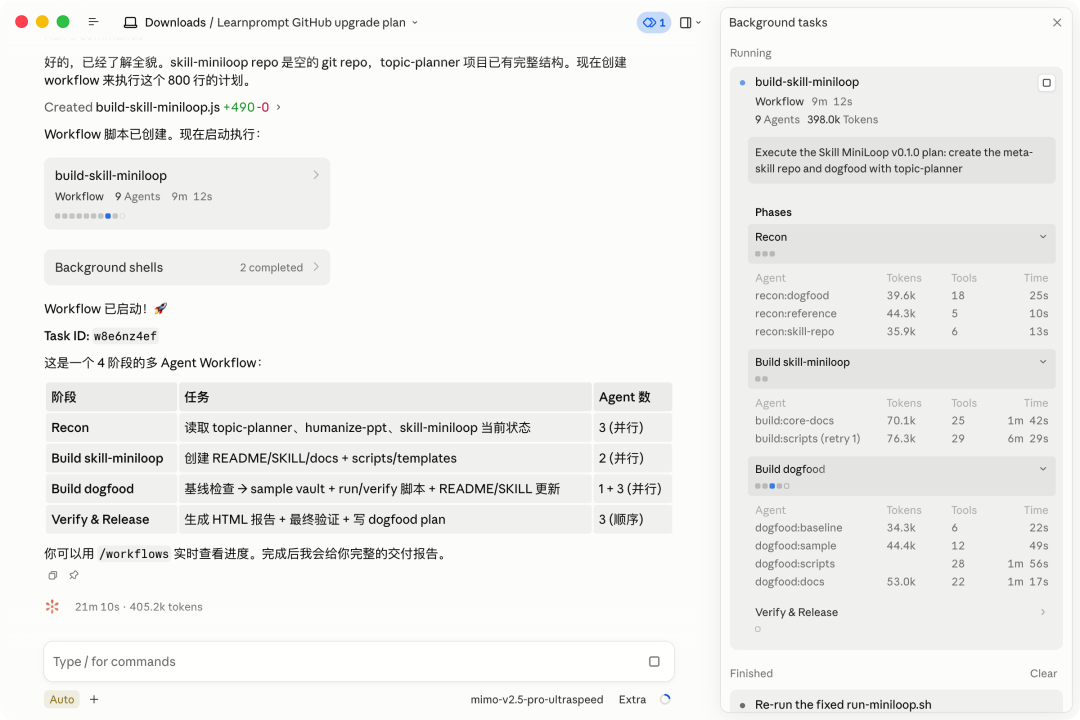
本来以为要跟之前一样跑一个晚上第二天早起来看报告的,结果12个Agent用了11分钟完成了,还做了一份HTML的Skill可读性检测报告,还带一个修改提示语,你可以直接丢给本地Agent做项目优化。比方说这里有注意到,我之前专门写给飞书文档转到markdown然后发到Z上面的这个Skill实际上是缺少Showcase和明确的指令脚本的,这样可能会让想要上手用的人不知道最终的效果,以及中间的过程是什么。
我发现这个过程其实还蛮能解决我的痛点的。现在开发一个Skill已经是非常非常简单的了,不管你是用什么样的 Agent,只要你提出你的需求,然后用上Skill Creator的话,基本上都可以做出一个能够被Agent读懂的 Skill。至于为什么说是被Agent读懂的?因为对于模型来说,读取你整个项目文件并进行安装是非常简单的,但关键在于人啊,做出来Skill的README(说明书)能不能让别人一眼就看懂?在发布阶段能不能做一个最小的验证环节,来测试到底缺了什么东西?Showcase有没有?兼容多少Agent?我之前是直接用Hermes复制一个空的Profile,一个啥skill都没有Agent来验证这个Skill能不能达到我想要的效果。总之这些经验和上面的项目可读性检查报告我也都说给MiMo-V2.5-Pro了,它打包成了一个Skill,叫mini loop
🔗github. com/LearnPrompt/skill-miniloop大家可以去试试看这个测试新skill的skill水平到底怎么样。目前我还没有进行任何人工的代码修改。之前讲过用cc swtich换Claude Code,Codex,Hermes里的模型,今天就多一步换Claude Code桌面版的,这样能方便管理多个对话还可以切换成Cowrok,桌面版多了一步,要开启路由。我们先切换到桌面添加新供应商,按步骤填key就行,直接保存。这时候会提醒你需要路由才能生成。
在左上角点设置之后就选路由,可以单独对Claude生效,这样就不会影响Codex的设置。重启之后,Claude Code桌面端的右下角对话框就会变成mimo-v2.5-pro-ultraspeed了。
哦,对了,虽然已经快到没时间冲咖啡了,但是我想了想还是不能省下喝咖啡的时间,所以我还装了个瑞幸Skill,让MiMo-V2.5-Pro按照我的心情给我选一杯咖啡来着,要是还能请我喝个咖啡就更好了。最后的最后,MiMo-V2.5-Pro UltraSpeed到底为啥能跑那么快呢?不是常用的换个参数小的Flash版本,从技术报告上看,MiMo-V2.5-Pro是MoE 模型,可以理解成一个公司里有很多专家,每次回答只叫其中一部分专家来干活。第一步就先是把这些专家的参数用FP4混合量化压小不降能力。第二步用了有点像提前草稿的机制,先用更便宜的方式快速猜一批 token,再让主模型检查。如果猜得准,就不用每个token都慢慢算一遍。普通模型是一个字一个字往外吐。这就像打字输入法提前给你整句话候选,你确认一下就能直接上屏。然后就是让GPU持续满负荷流动起来,把计算,搬数据,通信这些环节排成流水线。三件事叠在一起,才把1T的MoE 推到1000 tokens/s级。所以我们根本就不是讨厌快模型,是讨厌快了但蠢到全部要返工的模型。速度我要,质量我也要,鱼和熊掌都可以兼得的情况下,那肯定多多益善。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


