

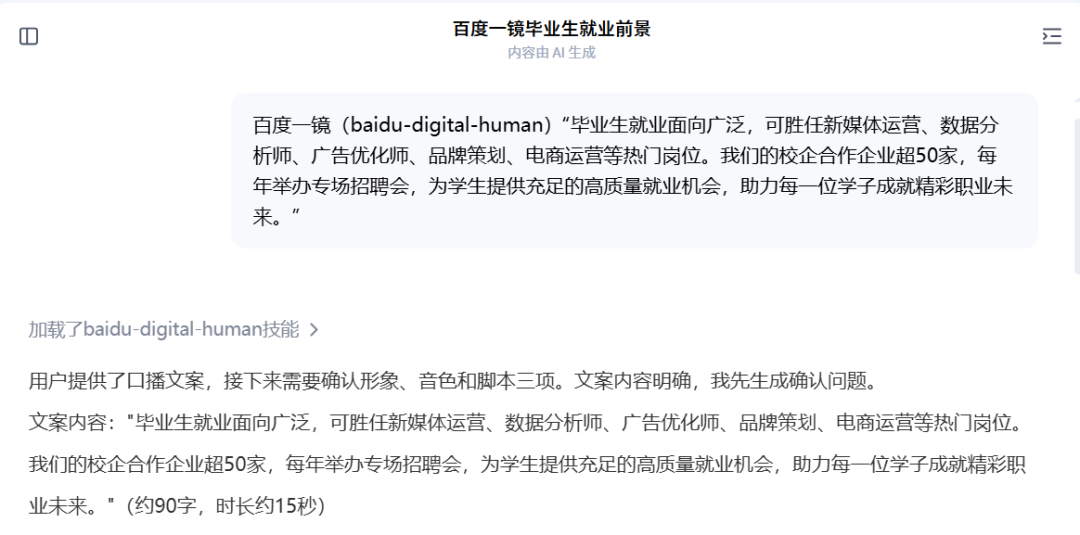
操作流程第一步,输入文案。你可以直接贴一段写好的稿子,也可以只给个主题让系统帮你生成脚本。我随手丢了一段文字进去:
第二步,选数字人形象。目前有四个:陈珍乐(女)—— 书卷风,中式书案、书卷茶具,古雅清幽。适合文化、读书类内容。李雨晴(女)—— 知性风,雅致书房,米色衬衫配柔粉半裙,明亮温婉。适合教育、生活类内容。孙宁(男)—— 清新风,白衬衫、细框眼镜、办公书架,干净通透。适合科普、科技类内容。李佳蔚(男)—— 商务风,深灰Polo、黑框眼镜、近景半身,沉稳。适合企业宣传、商务类内容。四个形象男女都有,正式的文艺的都覆盖了,基本够用。

第三步,等视频出来。单条支持2000字以内的口播文本,3到5分钟出片。我选完没等多久,视频就出来了:

适合谁用?这个工具不是要替代专业视频制作。它解决的是”不需要电影级质感,只需要一个人对着镜头把话说清楚”的场景:想做口播但不想出镜的;需要批量生产视频内容的;没有拍摄设备和场地的;想快速把文字变成视频的;旅游攻略、产品种草、知识科普、活动宣发、企业培训、个人IP起步……
几个实际感受省事。以前做一条口播视频,写稿、找场地、拍摄、剪辑,半天起步。现在丢段文字进去,几分钟出片。门槛低。不需要相机、灯光、提词器,不需要你会剪辑软件。有段文字就行。出片快。3到5分钟,比你自己录一遍再剪一遍快多了。当然,数字人跟真人出镜比还是有差距,微表情和肢体动作没那么自然。如果追求的是个人IP的信任感,真人出镜还是有优势。但如果只是要把信息用视频形式快速传达出去,这个够用了。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


