
大家好,我是焦哥。零代码基础手搓工作流,专注于AI智能体工作流的搭建知识分享。

早就想搞一个 AI 新闻日报的工作流,但一直被两个问题困扰:一是找不到稳定好用的新闻源,二是输出形式太纠结,文字稿不够直观,音频、视频制作又太折腾。直到我发现一个“骚操作”:直接把 HTML 网页转成图片!这一下全解决了:颜值高:版面精美,甩开纯文字好几条街。风格多:科技蓝、商务红、复古报纸…想要什么风格随你挑。成本低:最“变态”的是,这套流程跑下来,Token 消耗竟然是零!能吸粉:图片末尾还能带上你自己的二维码做推广。这样的效果,你确定不心动?赶紧跟我一起动手搭建吧!
先看下效果



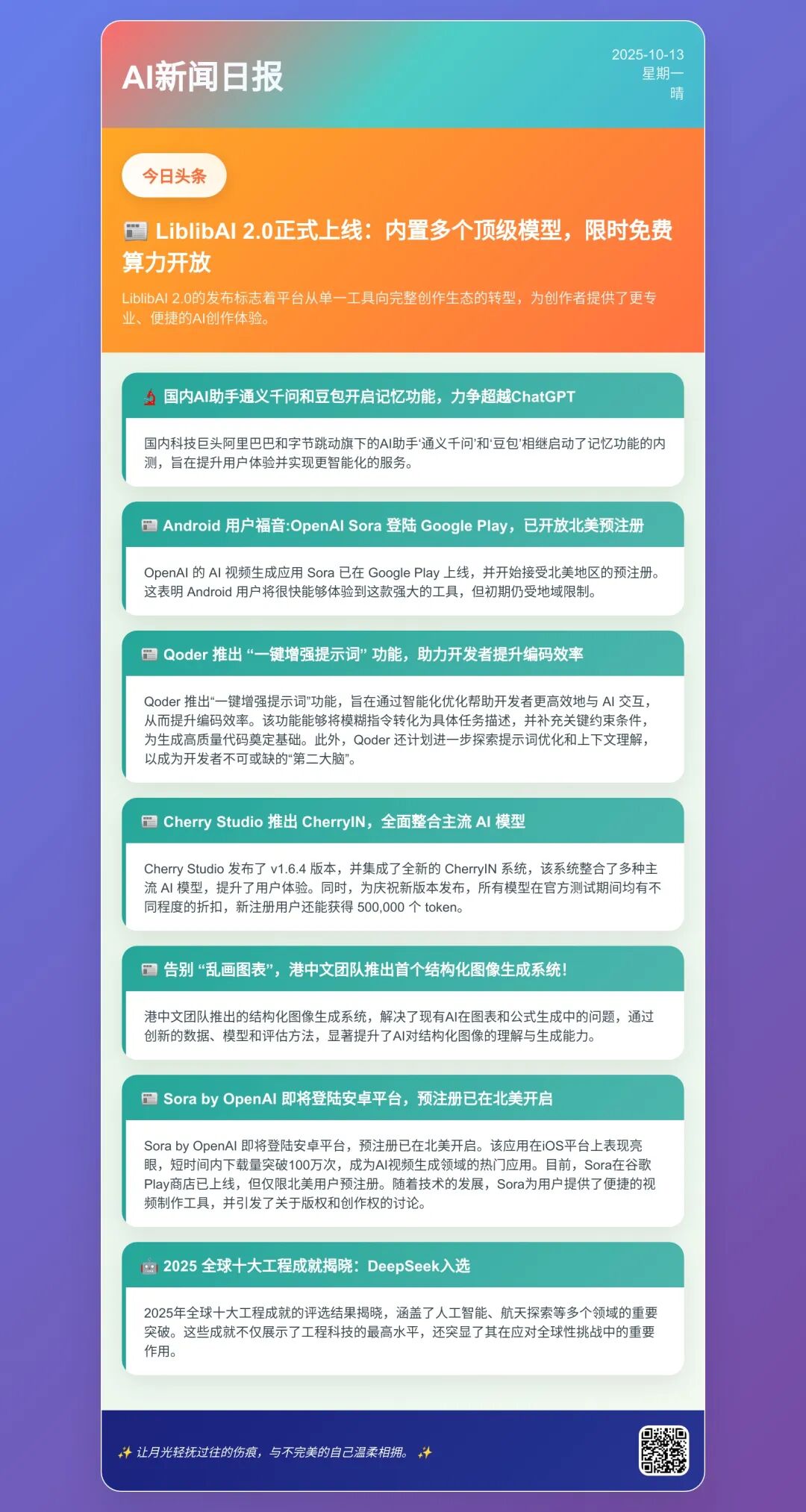
工作流总览
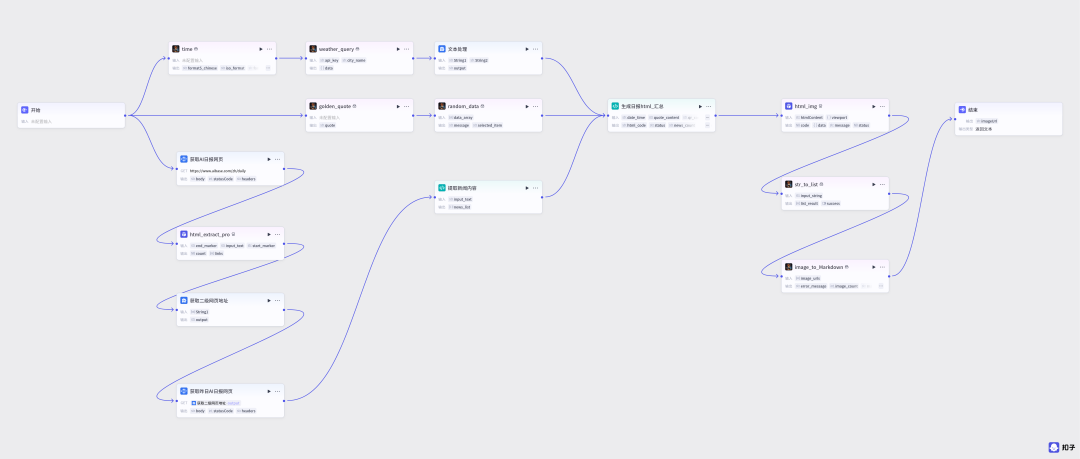
工作流节点开始节点焦哥现在的工作流是直接运行的,不需要输入任何参数。后面的节点,我制作了四种图片风格,并且加入了随机数节点,随机生成一种风格日报。当然,你也可以在开始节点添加一个参数style(风格),直接指定生成这个风格的日报。
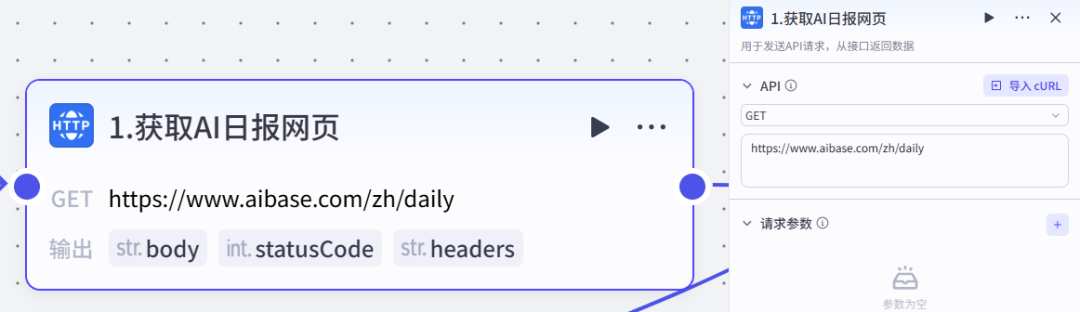
HTTP 请求节点这个工作流的核心之一就是先获得AI新闻资源,我用的是这个网址:https://www.aibase.com/zh/daily
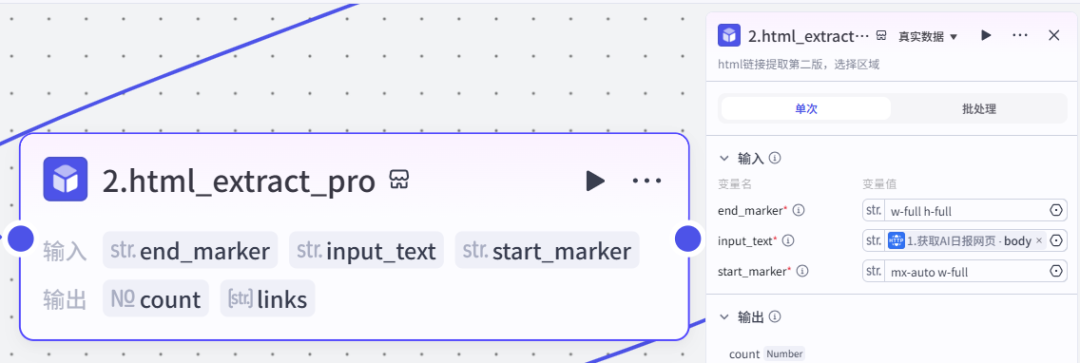
插件节点因为我们真正想要的是第1个新闻标题的内容,这里用一个插件节点获取第1个标题对应的链接ID
文本处理节点通过字符串拼接,得到这个二级网页的链接地址
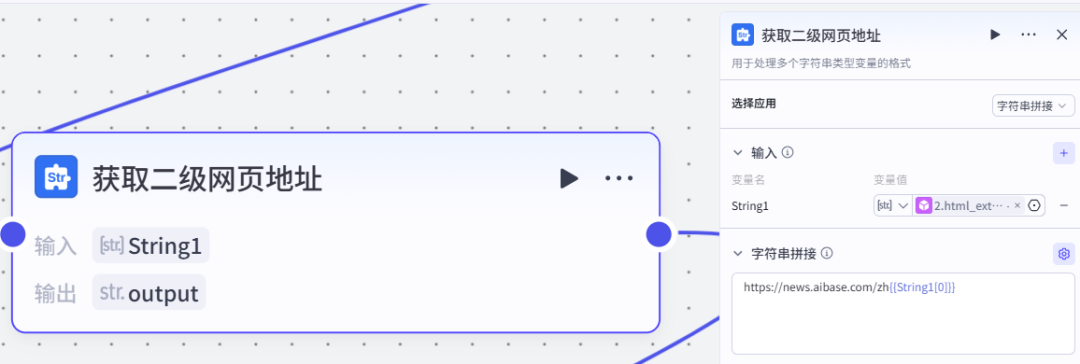
HTTP 请求节点重新获取这个链接的内容

代码节点(提取新闻内容)通过python代码处理,获取新闻的标题和摘要
pyrhon代码
importasyncio
importre
defclean_content_prefix(content):
"""
移除新闻内容中的非正常摘要开头
"""
# 定义需要移除的开头模式
unwanted_prefixes = [
r'^文章指出[,::,]?\s*',
r'^文章主要内容[是为]?[,::,]?\s*',
r'^文章说的是[,::,]?\s*',
r'^文章表示[,::,]?\s*',
r'^文章提到[,::,]?\s*',
r'^文章介绍[了]?[,::,]?\s*',
r'^文章描述[了]?[,::,]?\s*',
r'^文章报道[了]?[,::,]?\s*',
r'^文章称[,::,]?\s*',
r'^文章显示[,::,]?\s*',
r'^文章强调[了]?[,::,]?\s*',
r'^文章分析[了]?[,::,]?\s*',
r'^文章讨论[了]?[,::,]?\s*',
r'^文章解释[了]?[,::,]?\s*',
r'^文章阐述[了]?[,::,]?\s*',
r'^据文章[,::,]?\s*',
r'^根据文章[,::,]?\s*',
r'^该文章[,::,]?\s*',
r'^这篇文章[,::,]?\s*',
r'^本文[,::,]?\s*',
r'^文中[,::,]?\s*'
]
cleaned_content = content
forpatterninunwanted_prefixes:
cleaned_content = re.sub(pattern,'', cleaned_content, flags=re.IGNORECASE)
returncleaned_content.strip()
asyncdefmain(args):
"""
从HTML文本中提取新闻标题和正文,使用正则表达式直接匹配模式
参数:
args: 包含输入参数的字典,格式如:
{
"params": {
"input_text": "1、标题
内容
..."
}
}
返回:
包含新闻列表的对象,格式如:
{
"news_list": [
{"title": "📰 新闻标题1", "content": "新闻内容1"},
{"title": "🤖 新闻标题2", "content": "新闻内容2"}
]
}
如果未找到新闻,返回:
{
"news_list": [],
"error": "未能提取新闻项目",
"debug_html": "原始HTML片段..."
}
"""
# 获取输入文本
input_text = args["params"]["input_text"]
# 直接使用正则表达式找出所有可能的新闻标题和内容
# 查找类似 "1、标题后面跟着的段落" 的模式
news_pattern =r"(\d+[、.]\s*.+?).*?
(.*?)
"
matches = re.findall(news_pattern, input_text, re.DOTALL)
news_items = []
fortitle, contentinmatches:
# 清理标题和内容中的HTML标签
clean_title = re.sub(r'','', title).strip()
clean_content = re.sub(r'','', content).strip()
# 清理内容中的非正常摘要开头
clean_content = clean_content_prefix(clean_content)
ifclean_titleandclean_content:
news_items.append({
"title": clean_title,
"content": clean_content
})
# 如果上面的方法没找到,尝试另一种模式匹配
ifnotnews_items:
# 尝试查找
数字、标题
后面跟着的段落
alt_pattern =r"
(\d+[、.]\s*.+?)
\s*
(.*?)
"
matches = re.findall(alt_pattern, input_text, re.DOTALL)
fortitle, contentinmatches:
clean_title = re.sub(r'','', title).strip()
clean_content = re.sub(r'','', content).strip()
# 清理内容中的非正常摘要开头
clean_content = clean_content_prefix(clean_content)
ifclean_titleandclean_content:
news_items.append({
"title": clean_title,
"content": clean_content
})
# 如果仍然没找到,尝试第三种模式
ifnotnews_items:
# 尝试寻找标题模式,不依赖于HTML结构
title_pattern =r'(\d+[、.]\s*[^
]+)'
titles = re.findall(title_pattern, input_text)
fortitleintitles:
ifre.match(r'\d+[、.]\s*', title): # 确认是以数字开头的
clean_title = title.strip()
# 寻找标题后的内容
title_pos = input_text.find(title)
iftitle_pos != -1:
# 找到标题后的第一个段落
next_p_start = input_text.find("
", title_pos +len(title))
next_p_end = input_text.find("
", next_p_start)ifnext_p_start != -1else-1
ifnext_p_start != -1andnext_p_end != -1:
content = input_text[next_p_start:next_p_end]
clean_content = re.sub(r'','', content).strip()
# 清理内容中的非正常摘要开头
clean_content = clean_content_prefix(clean_content)
ifclean_content:
news_items.append({
"title": clean_title,
"content": clean_content
})
# 如果上述方法都无法找到新闻项目,尝试直接返回标题行和后面的文本
ifnotnews_items:
# 尝试查找所有强调文本作为潜在标题
strong_pattern =r'(.*?)'
strongs = re.findall(strong_pattern, input_text)
forstrong_textinstrongs:
# 只处理看起来像标题的强调文本(数字开头)
ifre.match(r'\d+[、.]\s*', strong_text):
title_pos = input_text.find(strong_text)
iftitle_pos != -1:
# 向后查找一些文本作为内容
content_start = input_text.find("", title_pos) +10
content_end = input_text.find("", content_start)
ifcontent_end == -1:
content_end = content_start +300# 限制长度
content = input_text[content_start:content_end]
clean_content = re.sub(r'','', content).strip()
# 清理内容中的非正常摘要开头
clean_content = clean_content_prefix(clean_content)
ifclean_content:
news_items.append({
"title": strong_text,
"content": clean_content[:200] +"..."iflen(clean_content) >200elseclean_content
})
# 根据内容匹配合适的emoji图标
defget_emoji_by_content(content):
content_lower = content.lower()
emoji_mapping = {
'股票':'📈',
'股市':'📈',
'投资':'💰',
'融资':'💰',
'收购':'🤝',
'合并':'🤝',
'破产':'💸',
'亏损':'💸',
'盈利':'💵',
'利润':'💵',
'AI':'🤖',
'人工智能':'🤖',
'机器人':'🤖',
'ChatGPT':'💬',
'大模型':'🧠',
'芯片':'🔧',
'半导体':'🔧',
'苹果':'🍎',
'华为':'📱',
'小米':'📱',
'特斯拉':'🚗',
'汽车':'🚗',
'电动车':'🔋',
'电池':'🔋',
'医疗':'🏥',
'健康':'❤️',
'疫情':'🦠',
'疫苗':'💉',
'教育':'📚',
'学校':'🏫',
'考试':'📝',
'游戏':'🎮',
'电影':'🎬',
'音乐':'🎵',
'体育':'⚽',
'足球':'⚽',
'篮球':'🏀',
'天气':'🌤️',
'环保':'🌍',
'政策':'🏛️',
'法律':'⚖️',
'科技':'🔬',
'互联网':'🌐',
'5G':'📡',
'元宇宙':'🥽',
'区块链':'🔗',
'比特币':'₿',
'数字货币':'💱'
}
forkeyword, emojiinemoji_mapping.items():
ifkeywordincontent_lower:
returnemoji
return'📰'# 默认图标
# 构建输出对象格式
result = {
"news_list": []
}
# 为每个新闻项目添加到结果中
forindex, iteminenumerate(news_items,1):
# 移除标题中的序号(如 "1、" "2." 等)
clean_title = re.sub(r'^\d+[、.\s]*','', item['title']).strip()
# 根据内容获取表情包,放在标题前面
emoji = get_emoji_by_content(item['content'])
news_item = {
"title":f"{emoji}{clean_title}",
"content": item['content']
}
result["news_list"].append(news_item)
# 如果还是没找到,返回错误信息
ifnotnews_items:
return{
"news_list": [],
"error":"未能提取新闻项目",
"debug_html": input_text[:500] +"..."
}
returnresult
插件节点新闻内容有了,我们获取一些其它元素,时间+天气
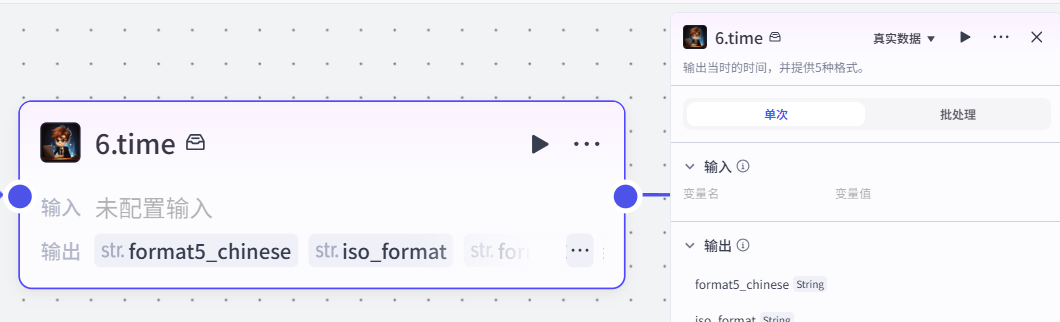
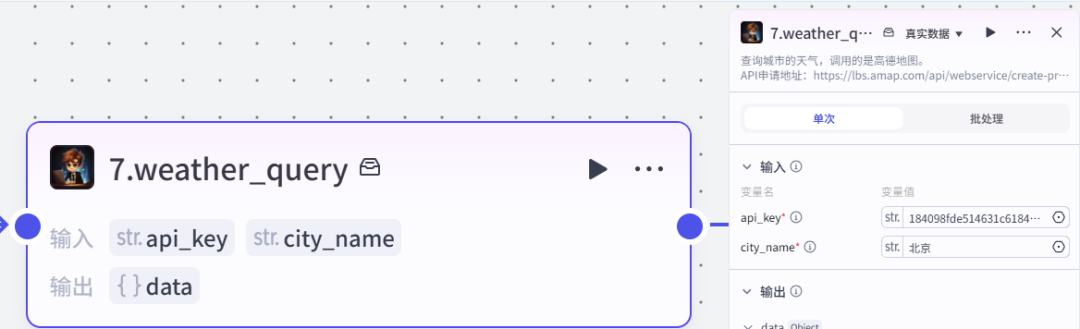
把时间与天气合并成一个字符串
随机获取一个金句
当然我们还可以添加自己的微信二维码,先把二维码转成链接,推荐用 草料二维码解码器https://cli.im/deqr
插件节点排版风格有四种{科技蓝,商务红,复古纸,青春活力},我们从这四个数据中随机获取一个。

代码节点所有的素材都准备好了,直接传入,生成html代码格式的AI日报
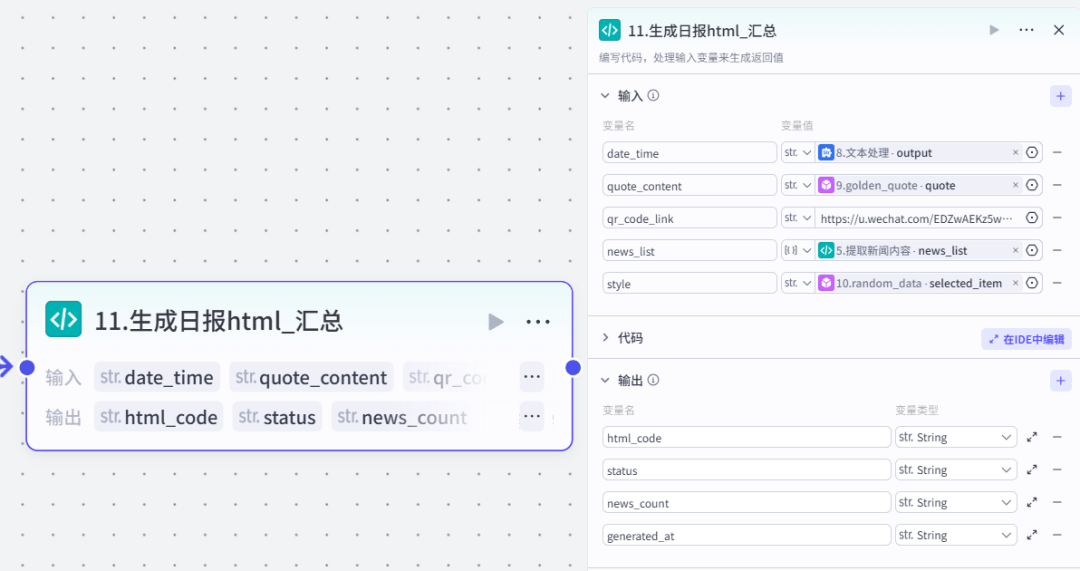
代码太长了,这里就不贴出来了。阅读到文章底部获取。
插件节点把html代码转为图片
插件节点因为输出的图片是链接形式,我们直接渲染成图片格式
结束节点
运行正常后,我们就可以点击发布了,绑定到智能体。最后再设置触发器(每天的固定时间自动运行生成AI新闻日报),具体设置可以参考这篇文章:告别手搓!Coze触发器一装,你的公众号爆文从此自动生成!
都已经看到这里了,如果觉得对你有帮助,记得点赞、在看、收藏、转发哦!获取工作流中的提示词、代码,麻烦您一键三连,评论区留言“AI日报”,加焦哥VX,邀请您加入交流群,免费领取飞书AI智能体知识库资料。完整的工作流,我已经上传到Coze团队空间了,后期会逐步更新新的智能体,如果你也想完整的复刻这样的工作流,欢迎加入我的团队空间,添加焦哥VX获取加入方法。

© 版权声明
文章版权归作者所有,未经允许请勿转载。