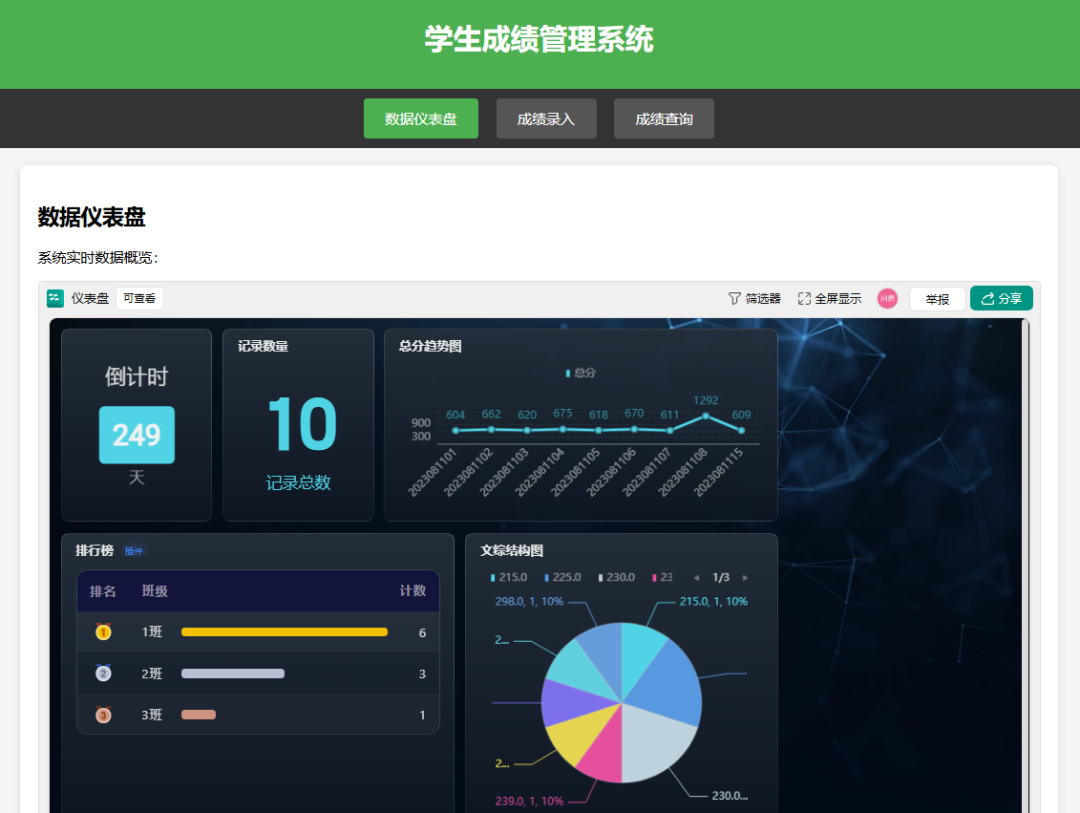

-
自动提取字幕– 从指定的 YouTube 视频中完整提取所有字幕文本,包括时间戳信息 -
智能内容总结– 将字幕文本整合后,调用 AI 大语言模型进行深度分析和智能总结 -
结构化输出– 将视频信息(标题、链接、时长等)和总结内容格式化为结构化文本 -
本地化保存– 自动将生成的笔记保存到本地文件
完成这个工作流后,你可以一键生成任何 YouTube 视频的总结笔记,省去大量的手动观看和记录时间。n8n 的完整工作流
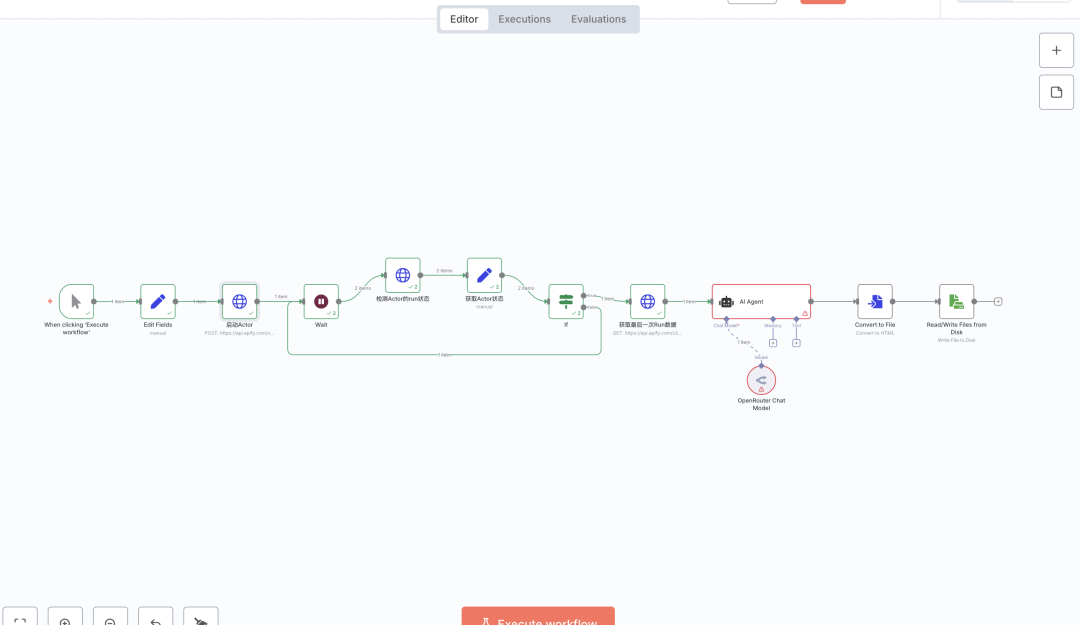
接下来,让我们先了解本项目的核心工具 —— Apify 平台。二、Apify 平台详解2.1 什么是 ApifyApify 是一个功能强大的云端 Web 爬虫和数据提取平台,专门为自动化数据采集而设计。与需要自己编写爬虫代码不同的是,Apify 提供了一个完整的生态系统——平台已经集成了大量预构建的工具(称为 Actor),用户无需编写复杂代码,直接配置参数即可使用。它的核心优势包括:
-
所有爬虫在 Apify 云端运行 -
无需担心服务器配置和维护 -
自动处理代理、验证码等反爬问题
-
超过 1500+ 预构建的爬虫工具(Actor) -
覆盖 YouTube、Instagram、Twitter、Amazon 等主流平台 -
社区贡献的各类数据提取工具
-
提供完善的 RESTful API -
支持多种编程语言 SDK -
轻松集成到现有工作流
-
免费套餐提供一定额度 -
按使用量付费,成本可控
对于我们的 YouTube 内容提取项目,Apify 提供了专门的 Actor 来获取视频字幕和元数据,让数据采集变得简单高效。2.2 核心概念Actor(执行器)
Actor 是 Apify 平台的核心,可以理解为一个在云端运行的、可复用的自动化脚本。每个 Actor 都被设计用来完成一项特定的任务,例如“抓取推文”、“搜索谷歌”或“提取 YouTube 字幕”。
Run(运行)
启动一个 Actor 时,就创建了一次Run。可以选择同步运行(等待任务执行完毕并立即返回结果)或异步运行(立即获得一个 Run ID,然后通过这个 ID 在稍后查询任务状态和结果)。对于耗时较长的抓取任务,异步模式更为常用。
Dataset(数据集)
Dataset 是 Actor 运行结果的主要存储方式。它像一个表格一样,可以存储多条结构化的数据记录。
三、实战操作步骤现在让我们开始构建这个完整的自动化工作流。整个过程包括 Apify 配置和 n8n 工作流设计两个部分。3.1 准备工作我们要先在 Apify 网站注册一个账号1) 注册并登录 Apify,打开注册地址https://console.apify.com/sign-up可以直接用 Google、Github 快捷注册或其它自定义邮箱
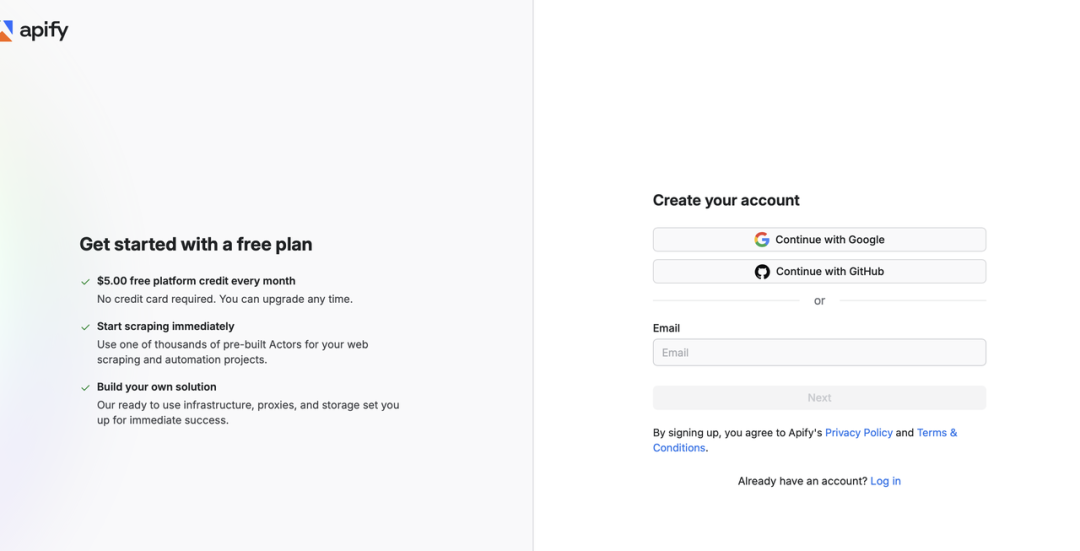
注册成功之后, 平台会赠送 5 美金 , 每月重置, 每个Actor 的价格会不一样,比如 YouTube 可以解析 1000 个视频。
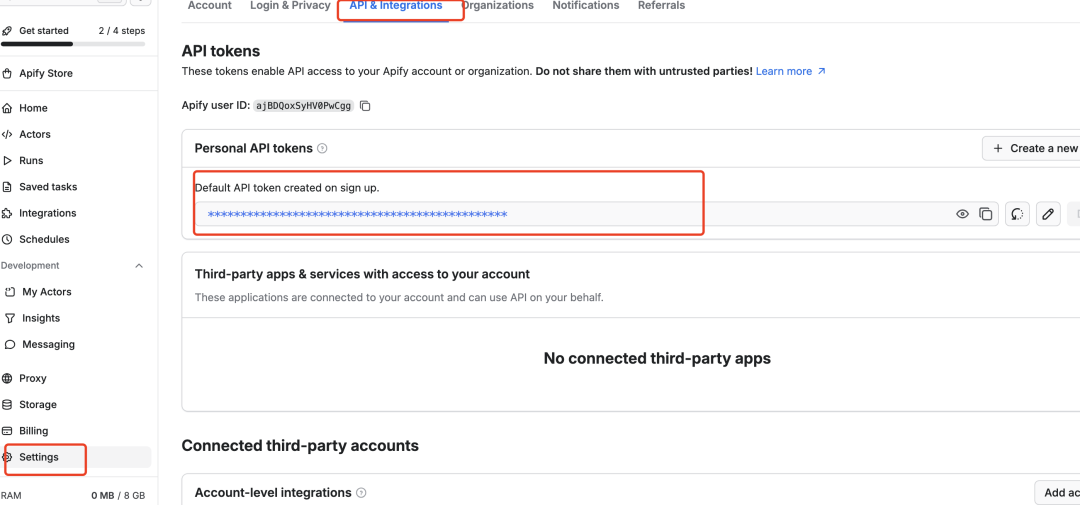
2) 获取 API TokenToken 在注册的时候就默认生成了。在个人后台「Settings」-「API & Integrations」可以找到,如果不想要默认生成的,点击「Create a new token」创建新的 Token,
-
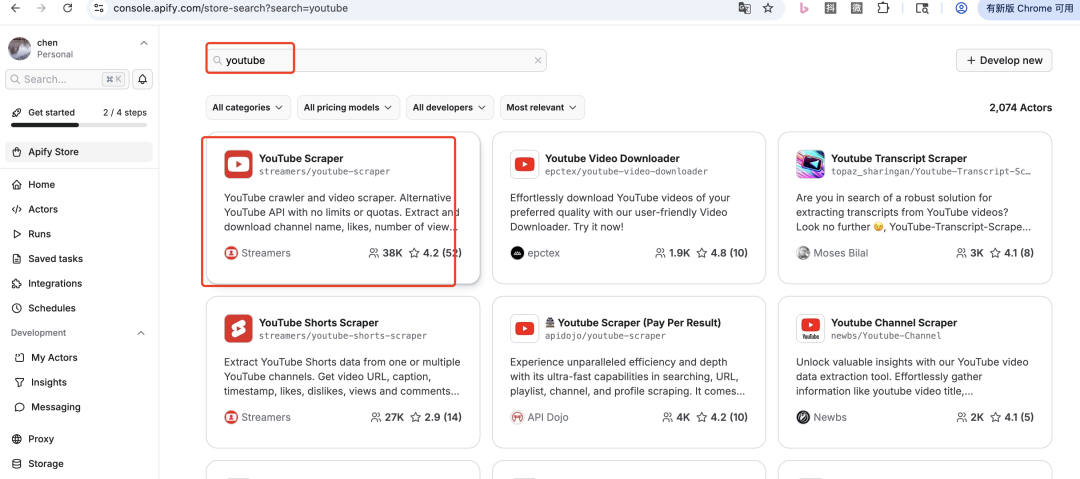
找到 Youtube 的 Actor ,可通过搜索关键字「youtube」快速找到。
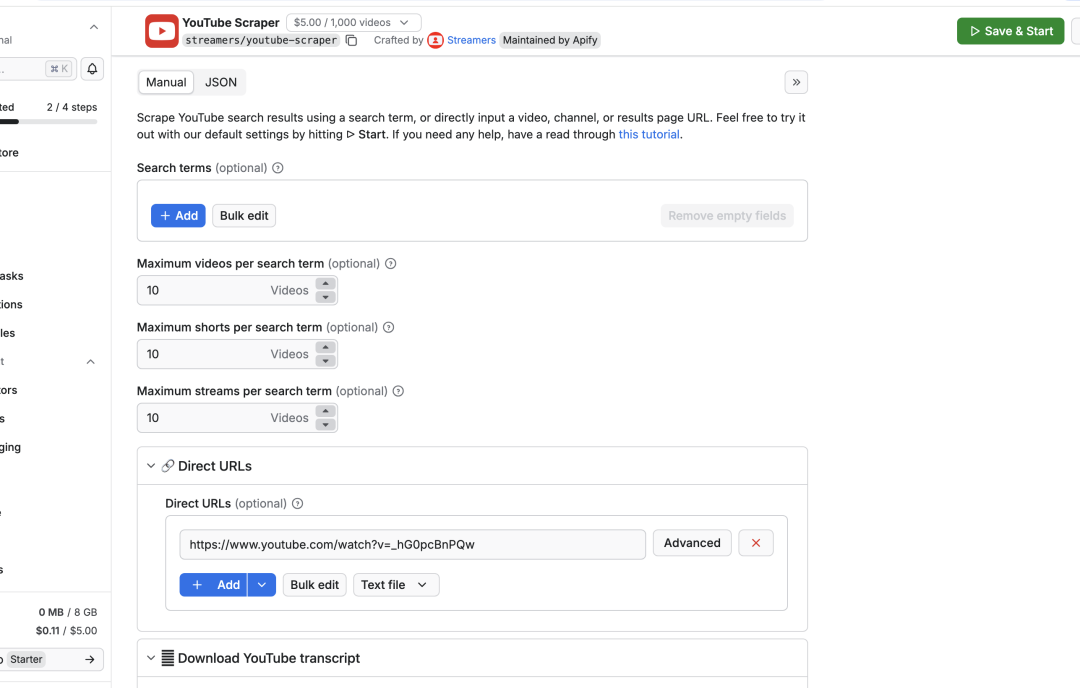
4)点击 YouTube 这个 Actor 进入详情页,在「Manual」这里我们配置输入参数,比如 URL 地址、字幕的信息等
配置完成后,我们切换到「JSON」标签, 会发现 Apify 已经将输入的参数都使用 json 的形式组装好了,我们后续可以直接在n8n中使用。
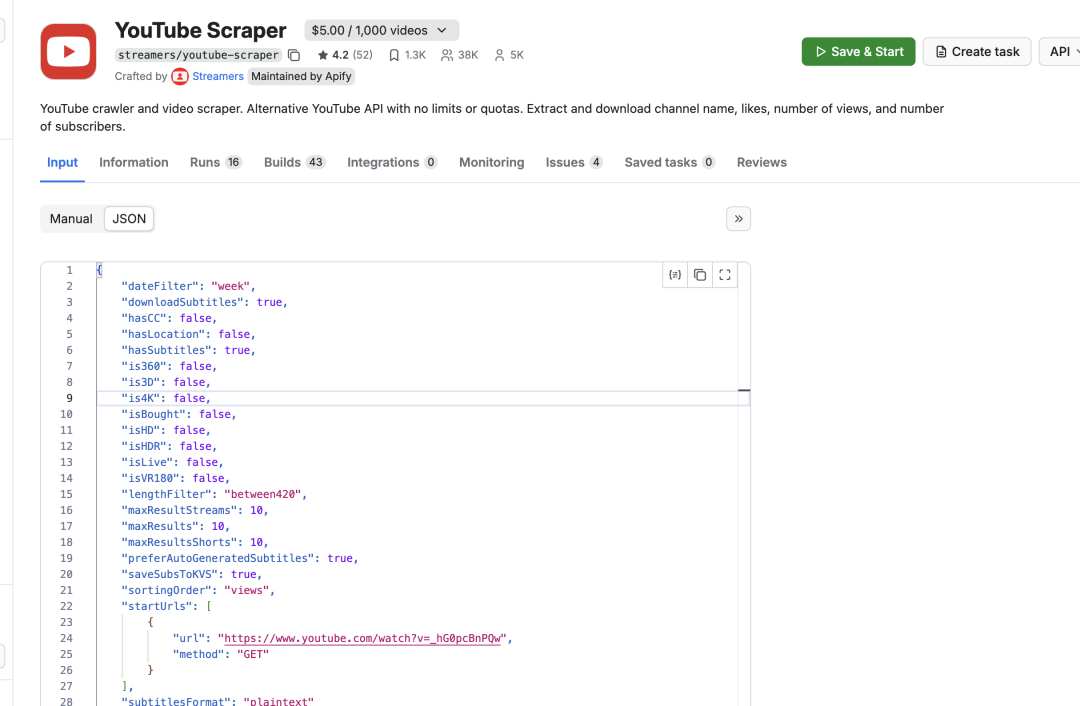
3.2 API的 endpoints 地址每一个 Actor 都有相应的 API 相关的地址,比如启动,查询、更新和删除任务等
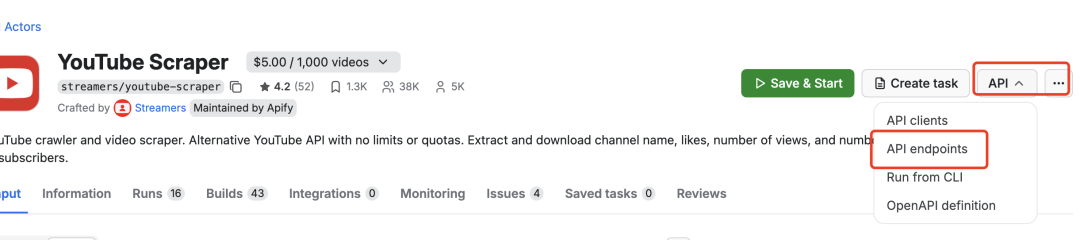
点击「API endpoints」链接,里面有和这个 Actor 相关的地址,目前我们只需要关注启动和查询的地址即可。
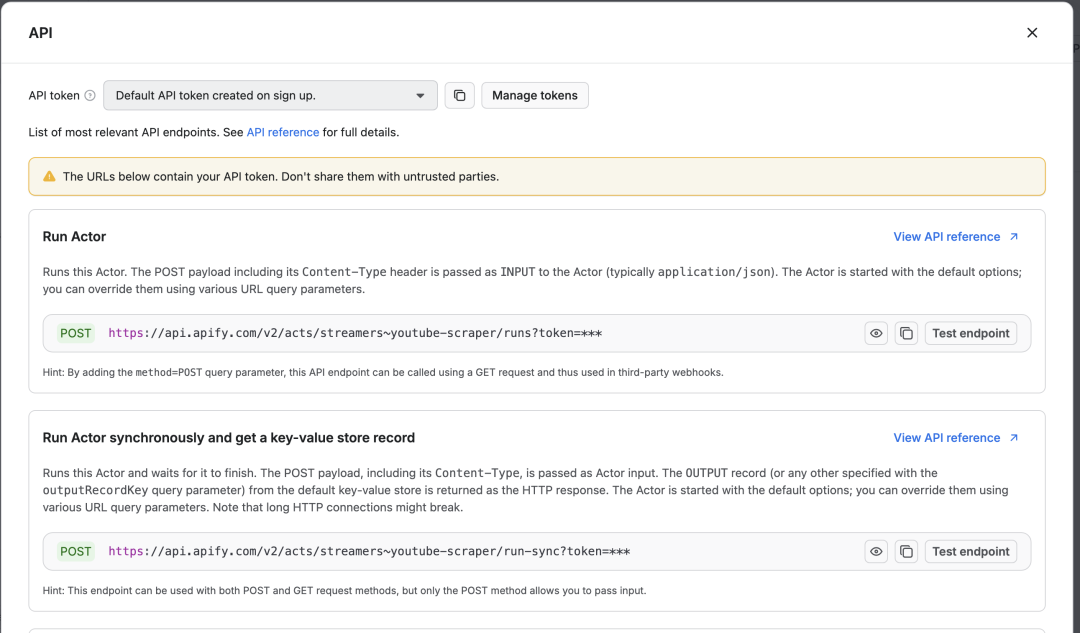
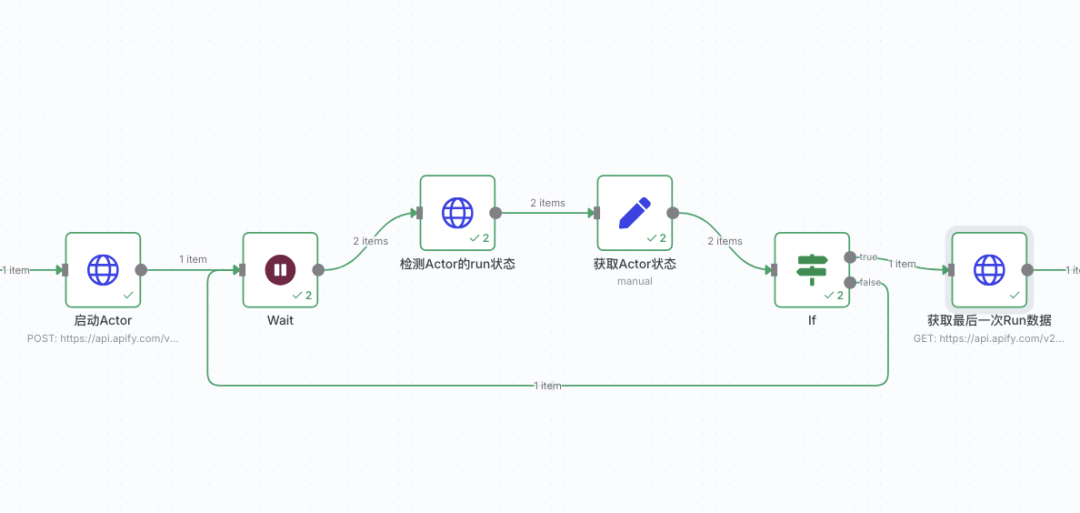
Apify 的配置基本上就是这样的了,接下来我们去创建n8n 的工作流3.2 n8n 工作流工作流的主要步骤是
-
启动 YouTube 的 Actor -
检测 Actor 的状态 -
获取 Dataset 的数据 -
AI 大模型视频总结 -
保存到本地
1) HttpReqeust 节点在 n8n 中增加一个 Http Request 节点,重命名为 「启动Actor」,URL地址填入上面 endpoints 的 「Run Actor」地址 :https://api.apify.com/v2/acts/streamers~youtube-scraper/runs?token=``XXXX打开「Send Body」,直接传递 json 数据, json 的数据为我们在上面 Actor 创建输入参数时的JSON标签的值
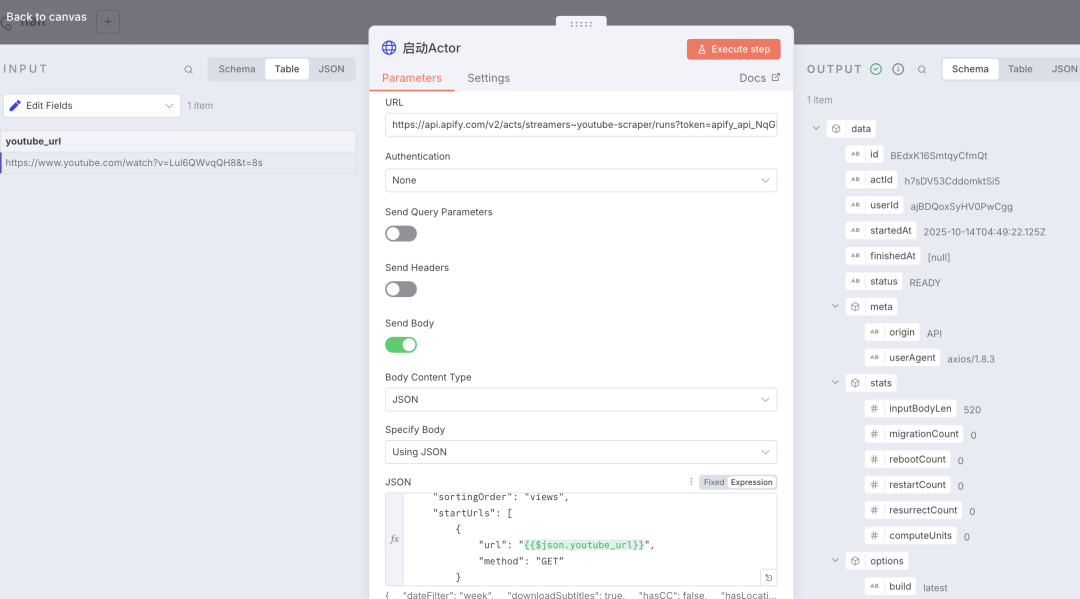
2)HttpRequest 节点增加一个检测节点,因为刚启动 Actor 的时候,数据并不是立即就返回了,所以需要有一个状态的检测,检测的 API 接口地址,可以参考 Apify 的接口文档地址
https://docs.apify.com/api/v2/actor-run-get
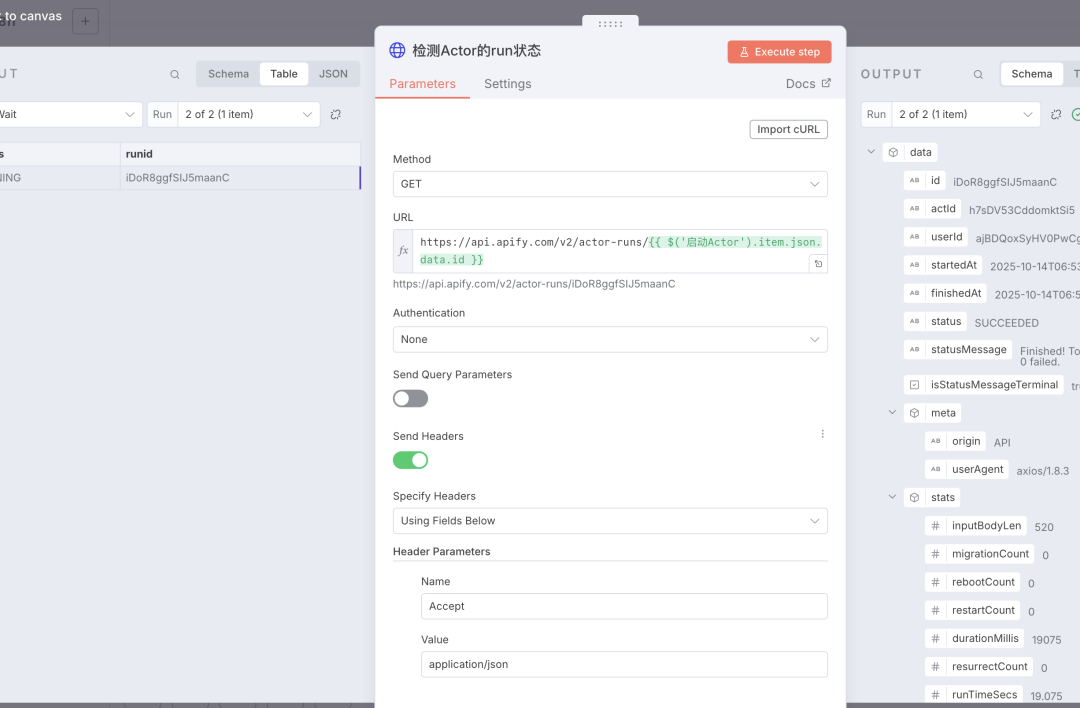
这里的 URL 地址为 https://api.apify.com/v2/actor-runs/``:runid, 其中 runid的值为启动 Actor 时,接口返回的 id 字段的值
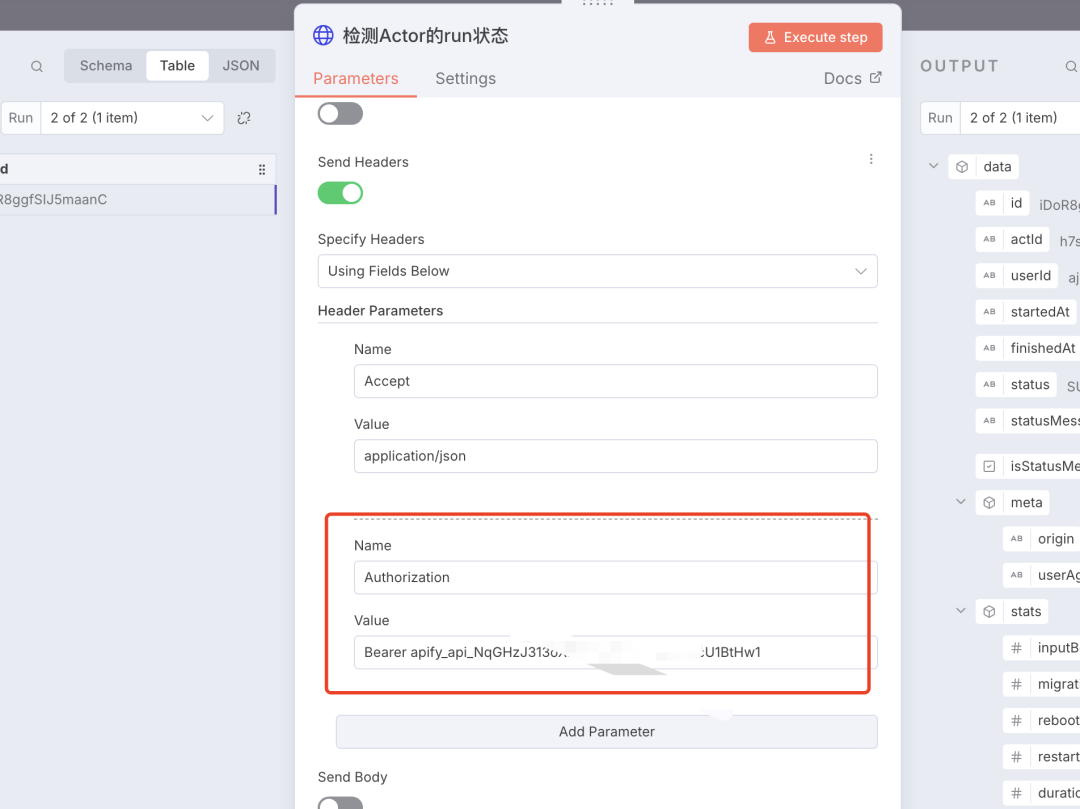
这个接口需要有一个 Bear 的认证,需要我们提供 Token 的值
当接口返回的 status 字段的值为 「SUCCEEDED」时,就可以获取数据了。3)Http Request 节点URL的地址也是从上面的 endpoints 中获取的,https://api.apify.com/v2/acts/streamers~youtube-scraper/runs/last/dataset/items?token=``XXX
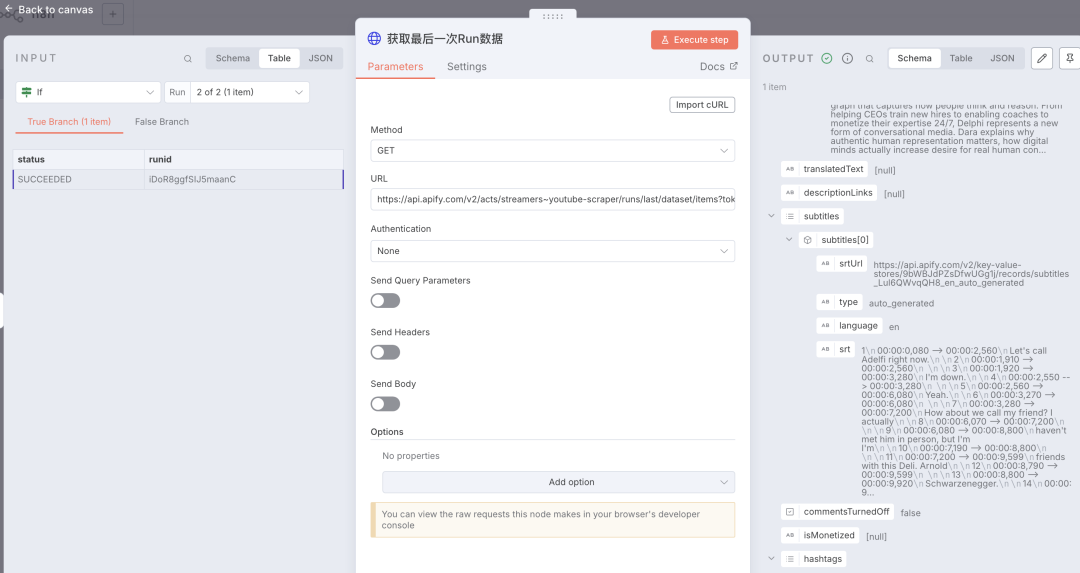
「subtitles」字段下面的 srt 为视频字幕的原始文本,内容总结也是从这个字段里面获取数据。4) IF 节点检测Actor状态时,有可能成功或未完成,这里通过 IF 判断状态值,如果未成功时,使用「Wait」状态延时后继续查询,直到成功后,进入下一节点。
5) AI 大模型在 n8n 中,增加一个 AI 大模型的节点
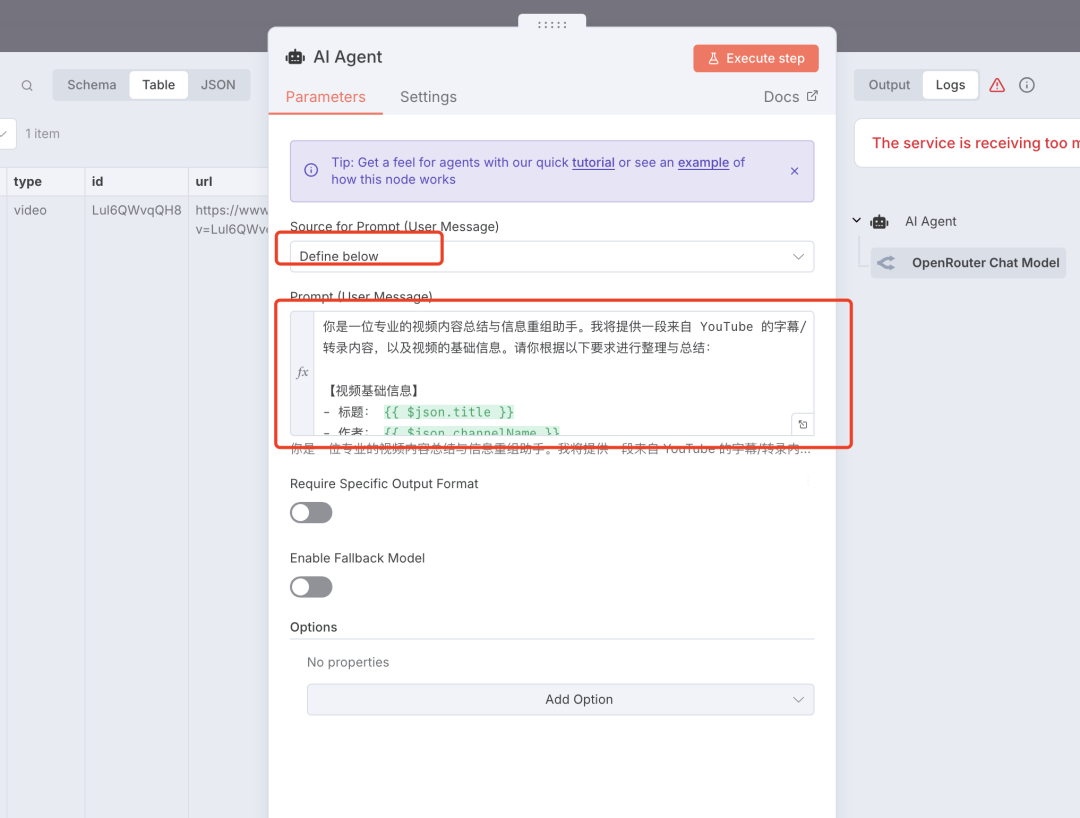
在 AI 节点的 Source 中选择「Define below」, Prompt 中输入我们的提示词。这个提示词根据自己的要求来写,不会写的直接让 AI 来写就行。
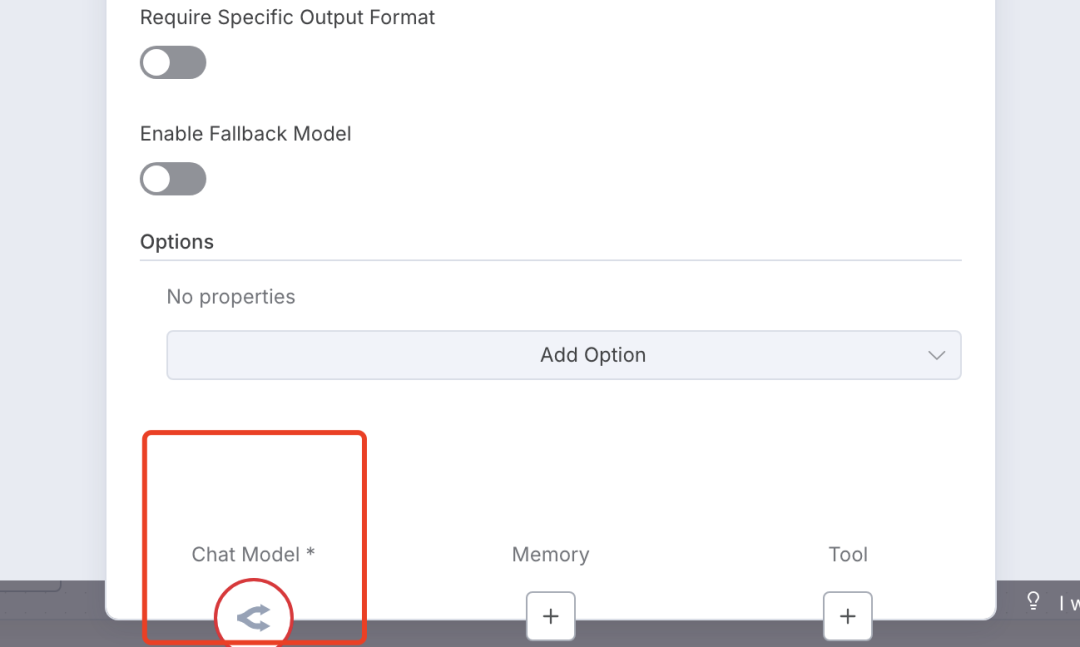
然后需要挂载一个大模型,点击下面的「Chat Model」
会出现Deepseek、Gemini、GPT、Claude和 Openrouter 等,我没有其它的大模型 API 权限,这里用的是 Openrouter 免费的 Gemini 模型,用起来会有限制,不是太稳定 。如果自己有合适的大模型的 API 权限,可以直接换掉就行。
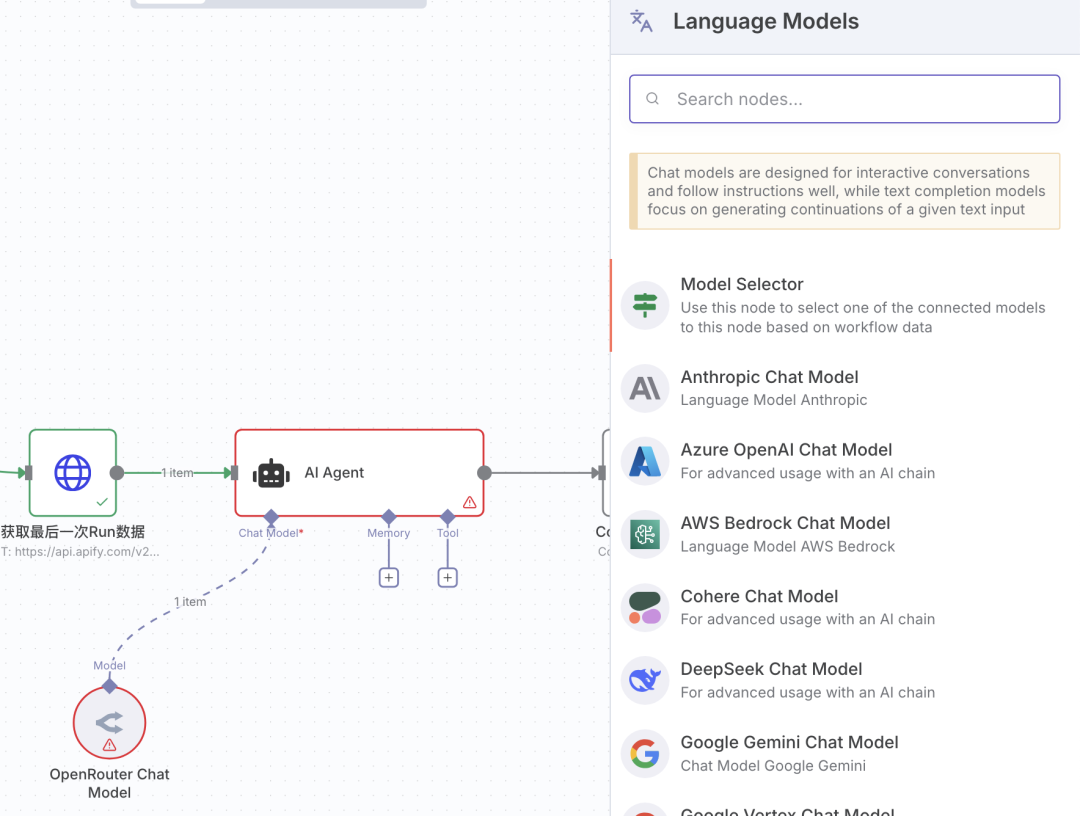
创建一个 Openrouter 的 Credential 后,选择需要的 model 即可。
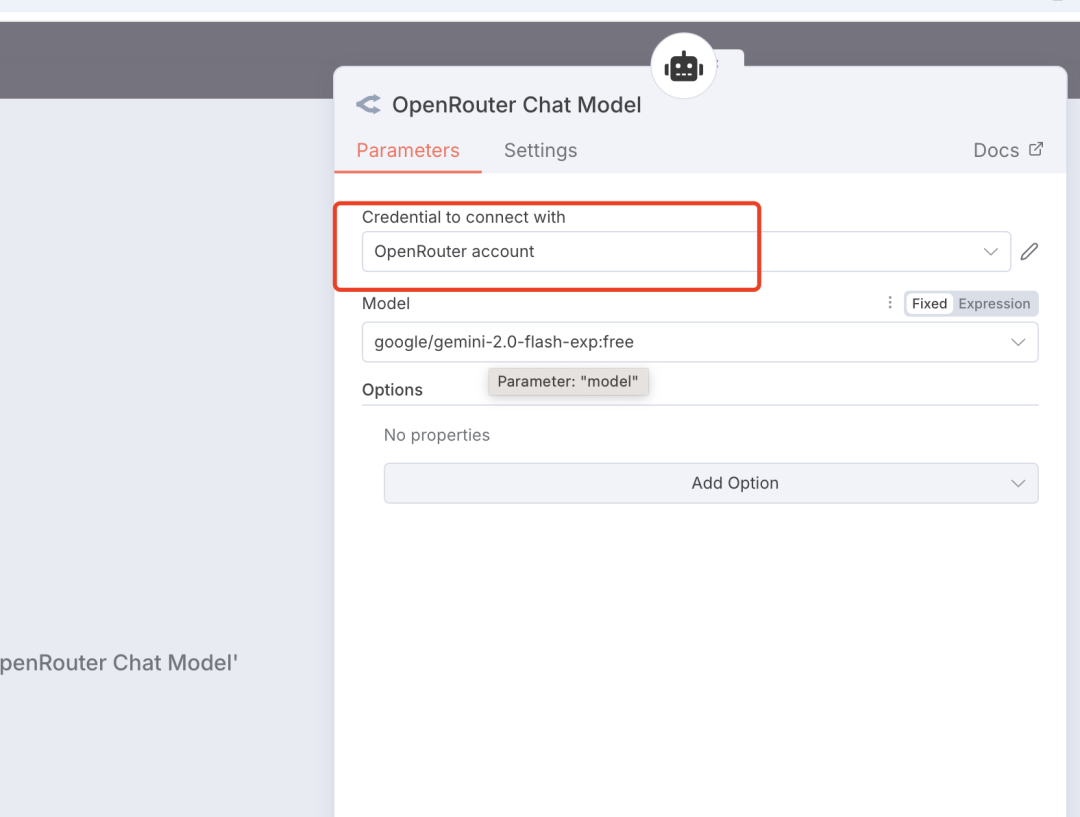
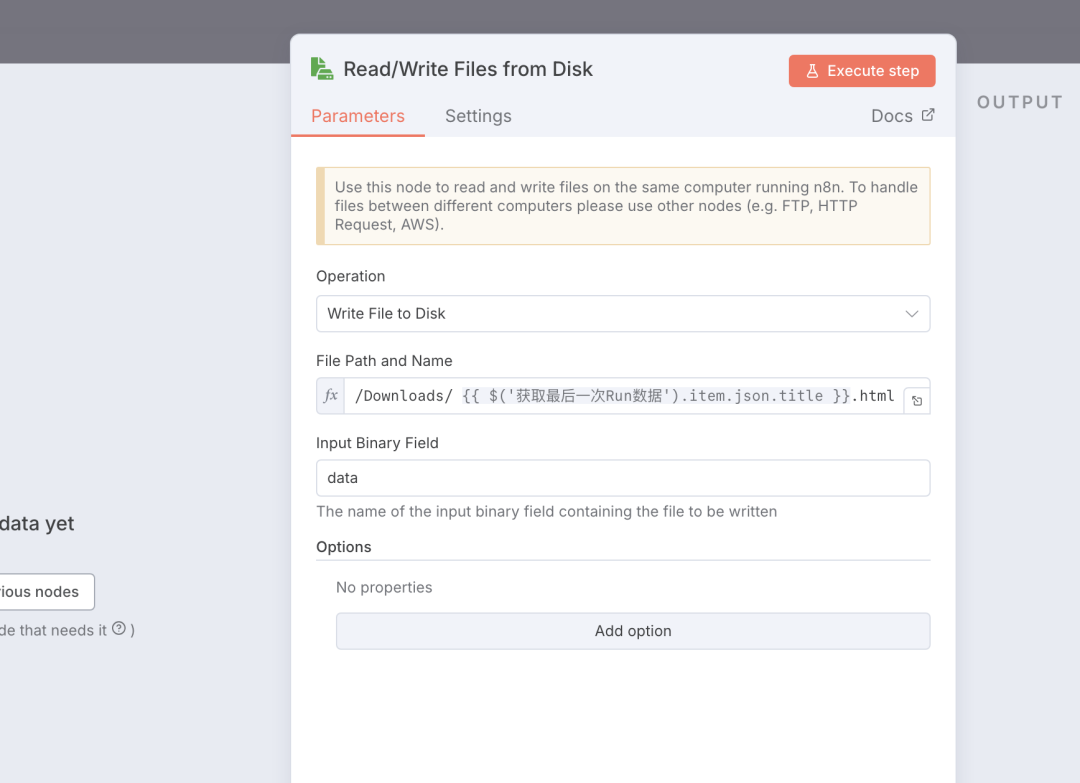
6)保存到本地
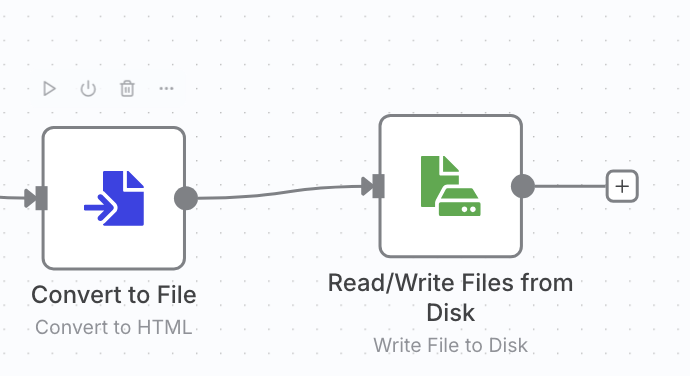
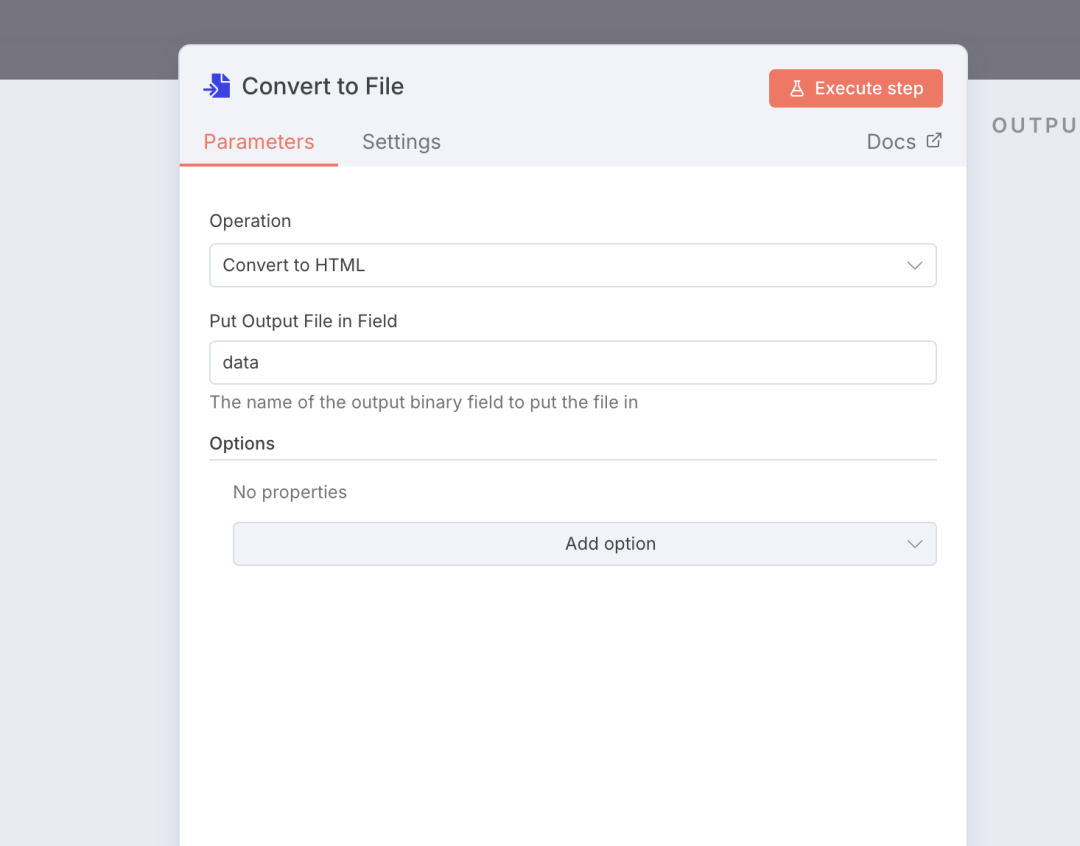
增加一个文件转换的节点,将 json 数据转成 html 格式。
增加一个写文件的节点
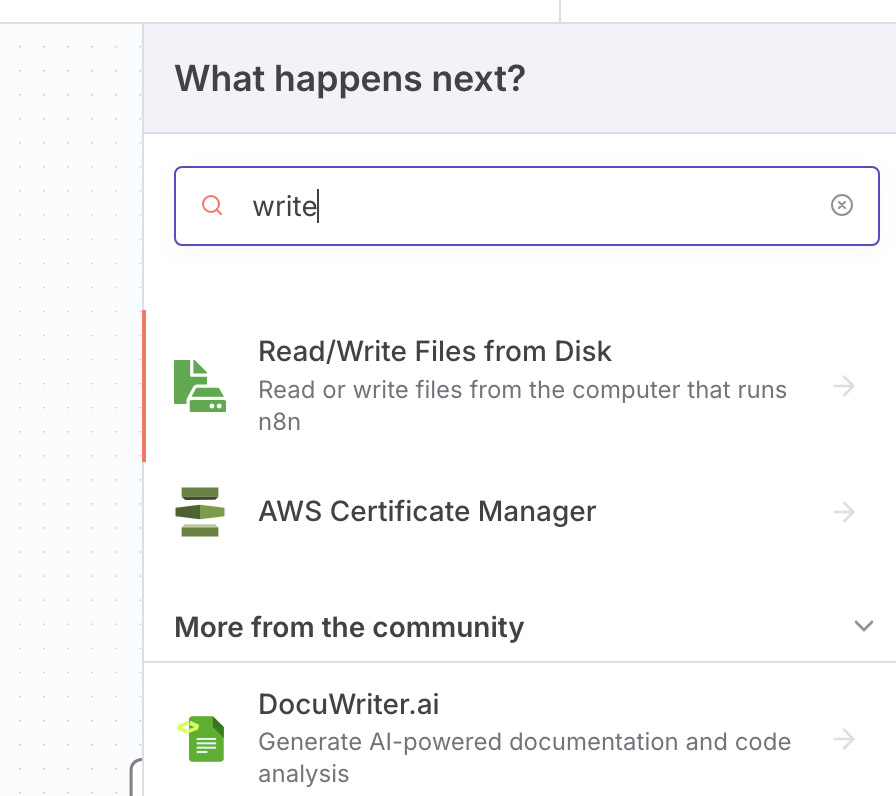
将上一节点转化的 html 文件保存到本地中。
以上就是 n8n 视频内容总结工作流的步骤。四、总结通过 Apify 和 n8n 的强大组合,我们成功构建了一个完整的 YouTube 视频内容自动化提取和总结系统,无需复杂编程,仅通过配置和拖拽就能实现帮助你快速从视频中提炼核心信息,让机器处理重复性工作,大幅提升效率。如果你也有类似的自动化需求,不妨尝试这套方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。