无论是朋友常常提出的问题,还是我自己反复测试的课题——到底哪个AI模型在哪个领域表现最出色?这一直是个颇具争议的问题。是否存在一个客观且令人信服的评判标准?

直到最近,我发现了一个颇具说服力的网站:https://lmarena.ai/。它或许可以给出一个相对公平的答案。(如果你有特殊网络条件,并对AI有兴趣,这个网站一定要收藏!这是你免费体验世界最好AI想起你我的温柔的心的地方,没有之一!)
在这个网站上,你可以清晰地看到当前世界顶级大语言模型(LLM)在多个任务维度上的表现排名。涵盖领域广泛,数据更新及时,堪称是AI领域的“竞技场”。

那么,这个排名真的客观、权威吗?让我来打个比方:在临床医学中,评估一种药物是否有效,有一个被公认为最科学的方法——随机、大样本、双盲实验。简单来说,就是让几组病人服用不同的药物或安慰剂,但他们并不知道自己服用的是什么。

他们只需如实反馈感受,最终通过大规模数据统计得出药效是否真实存在。人越多,实验次数越多,结果就越靠谱。
LMArena正是将这种思路应用于AI模型的对比评测。它的机制很巧妙:系统会随机选择两个AI模型,让它们在相同的提示词下完成同一个任务,用户只需根据结果选择“谁更强”。整个过程中,模型的名字是隐藏的,完全基于内容体验进行“盲测”。
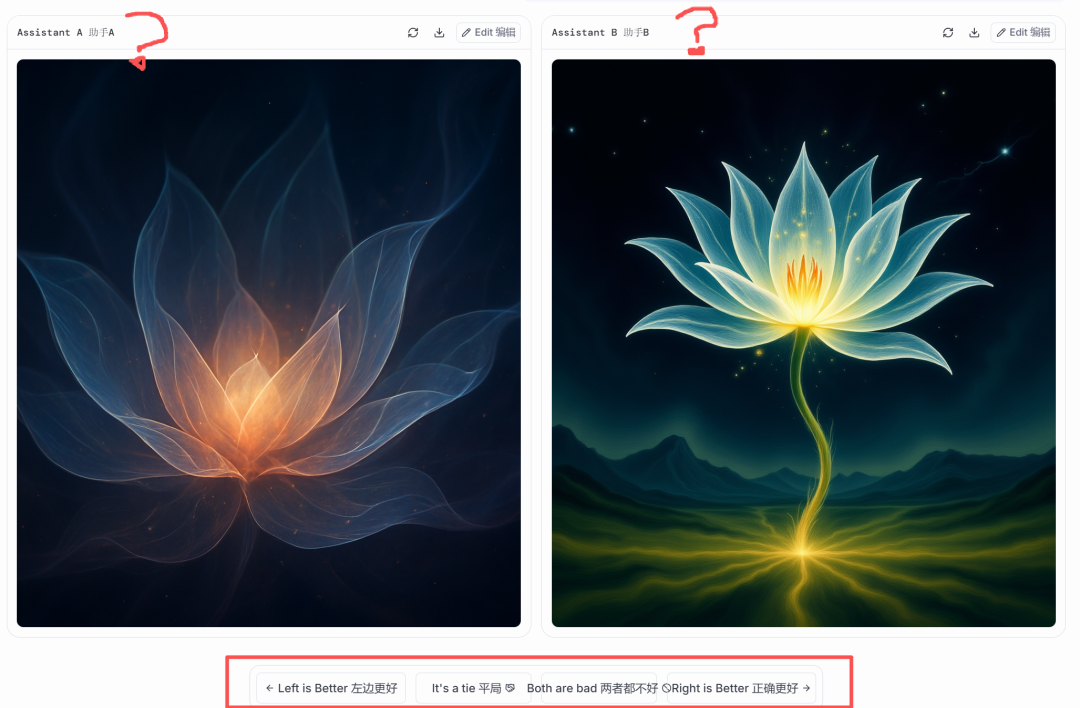
最终,再揭示模型身份,并将用户的选择计入模型整体评分中。

这不正应了那句老话:“是骡子是马,拉出来遛一遛”!

通过成千上万次真实用户的直观判断,LMArena为我们提供了一份更贴近真实应用体验的AI排行榜。这种“以战代评”的方式,不仅公平透明,而且极具参与感,也为AI的发展提供了更人性化的检验标准。
以下是2025年11月6日的榜单:
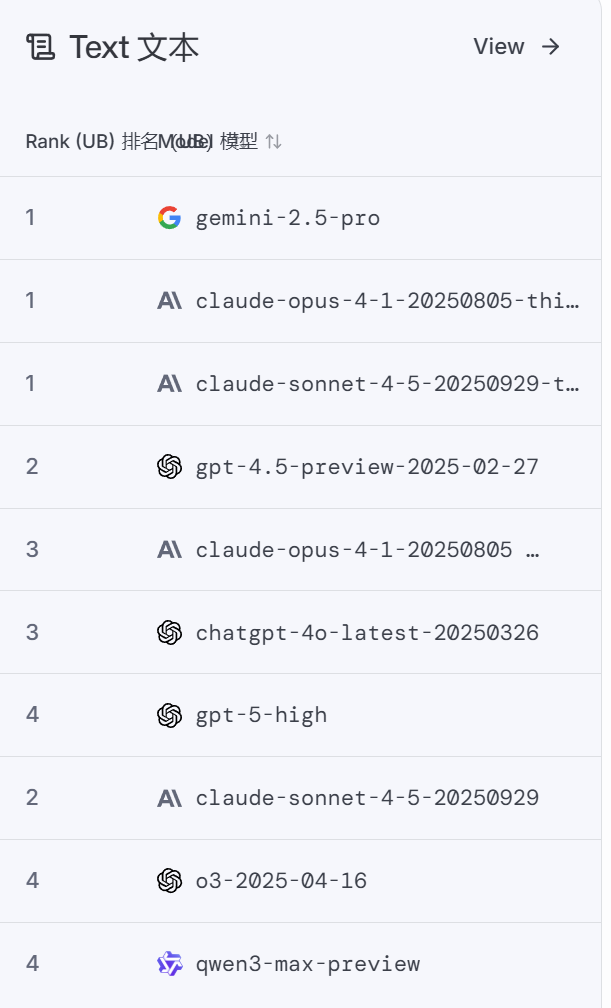
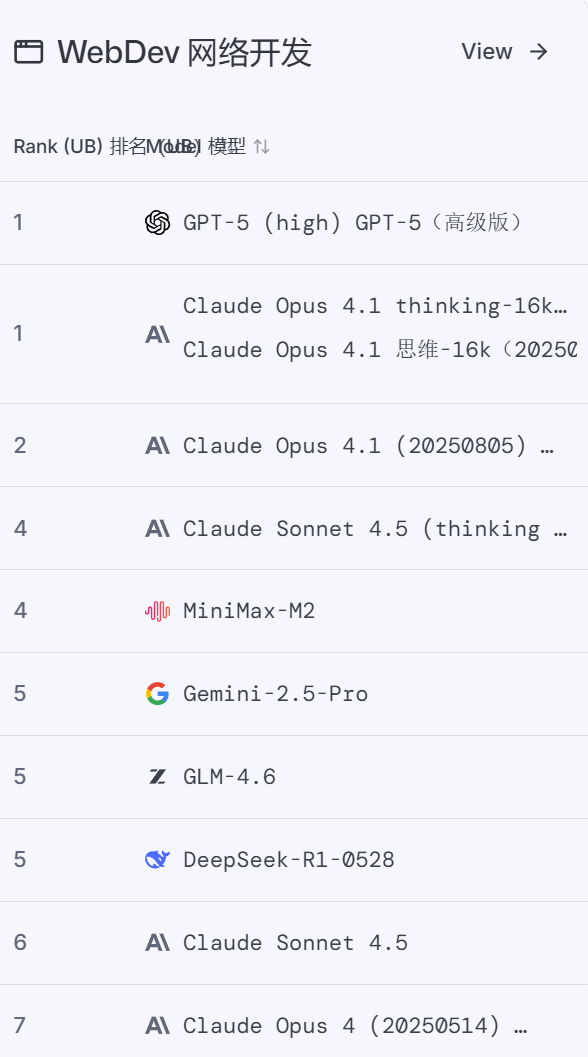
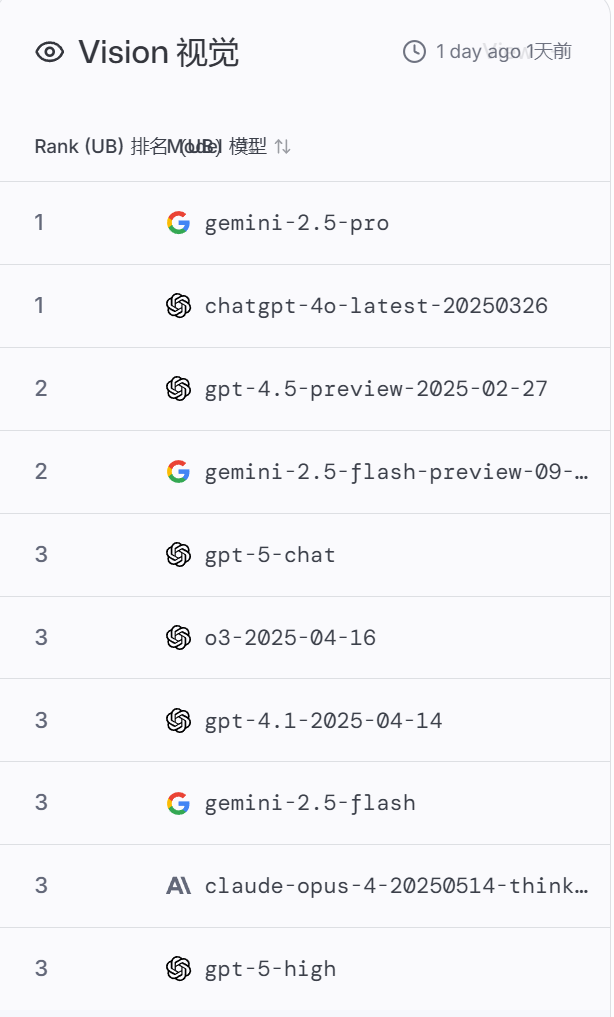
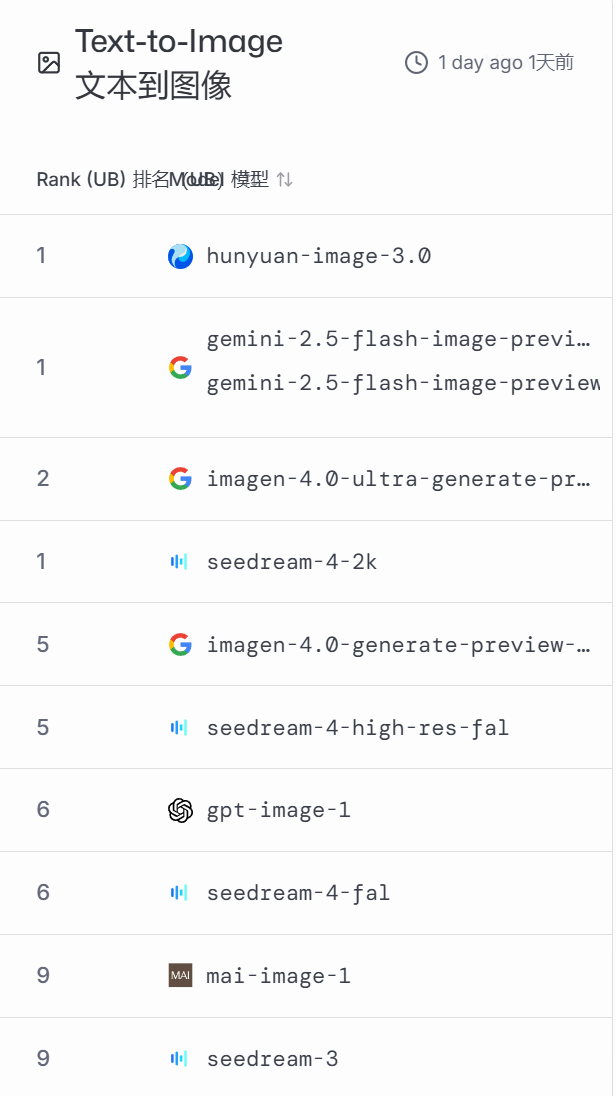
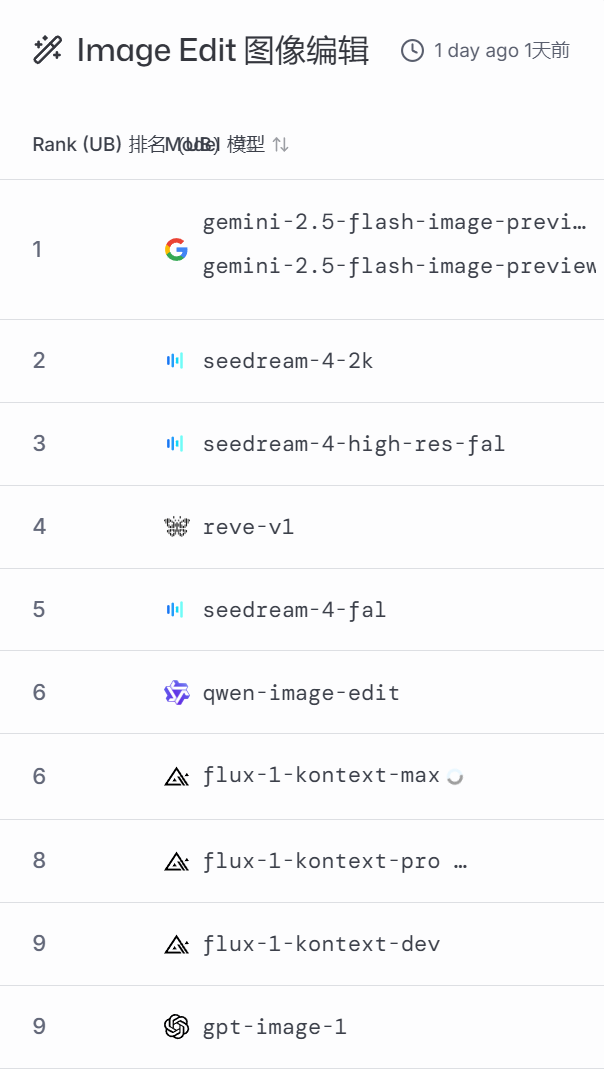
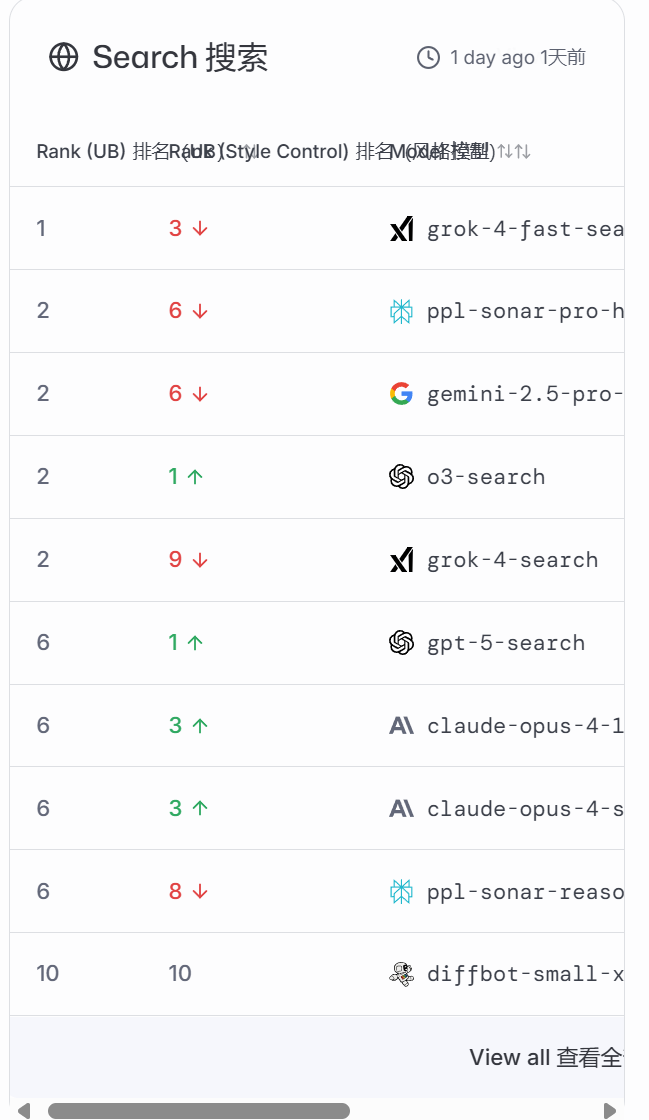
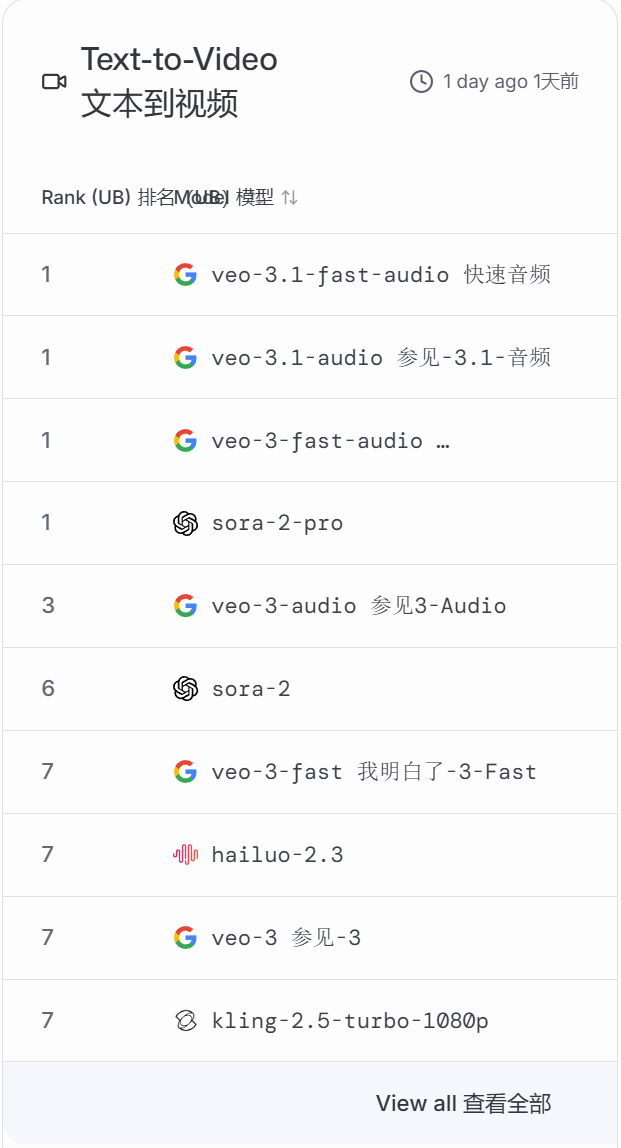

这个平台,不仅让你了解哪个领域哪个AI更擅长?更重要的是,它让你参与并直观的体验,这个过程是不收取任何费用的,而仅是将你的评测数据作为它对AI判定的资料,真的太良心、太科学了!
另外,你还可以不盲测,直接选取指定的AI进行PK:

聪明的你一定想到了,这不就可以“白嫖”了吗?是的,甚至没有次数限制,但唯一的问题是没有“上下文”,评测都是单次记分,显然,出图、出视频是非常不错了。
以下是单独打分模式:

评选视频,我们需要移步到discord.com/:

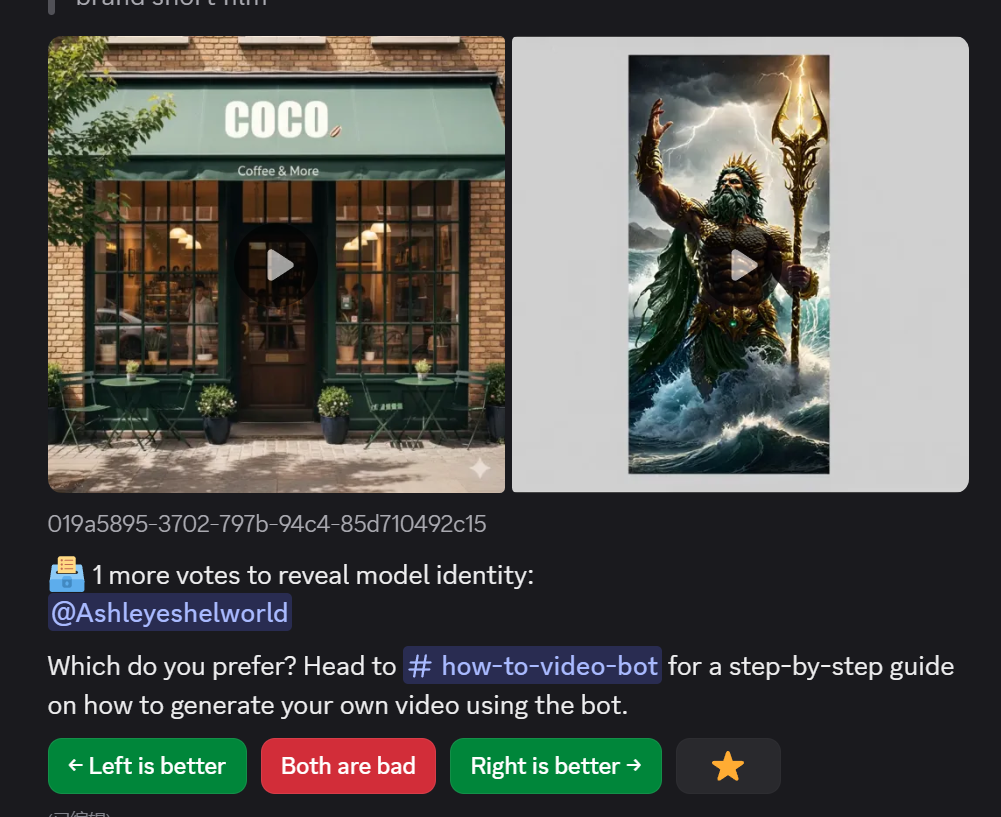
和此前文字、图片不一样的是,我们可以看到别人出的视频,然后进行打分,同时,也可以自己进行“文生视频”和“图生视频”。
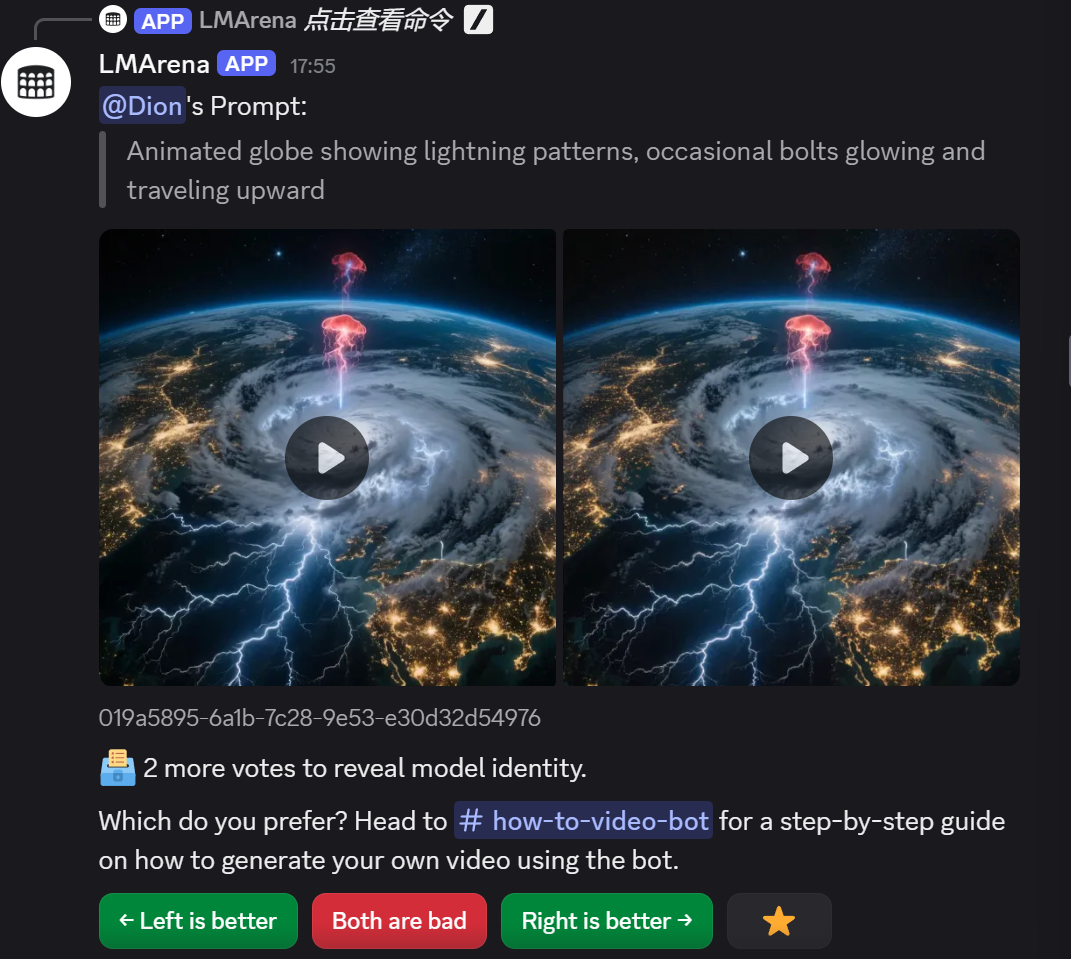
我们如果自己生成视频,所写提示词记得转成英语哟!(以下是我的操作)
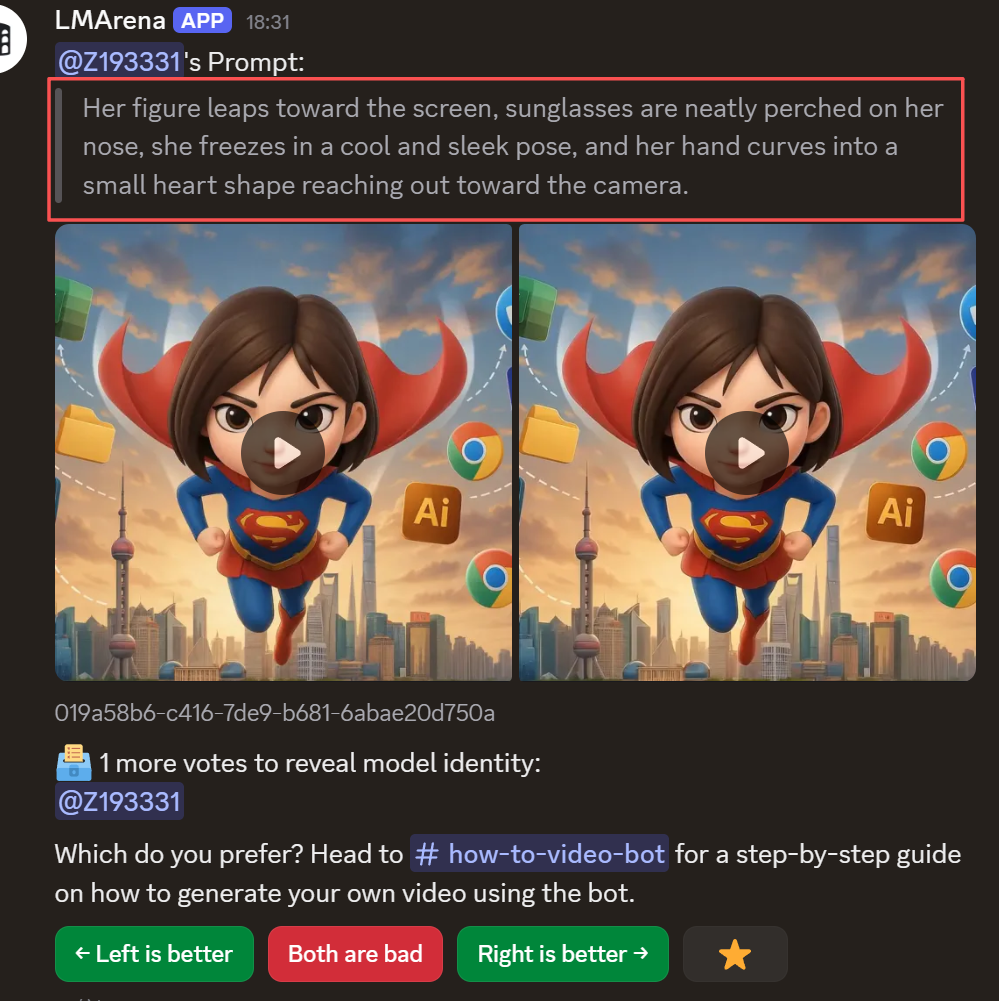
左侧视频如下:
右侧视频如下:
高下立判有没有!快去尝试一下吧!https://lmarena.ai
LMArena.ai 前身为 Chatbot Arena,由伯克利 LMSYS 团队(含 Ion Stoica 等学者)2023 年创立,是全球公信力强的大模型众测平台。(全称:Large Model Arena,意为大模型竞技场)它以匿名双盲对战 + Elo 算法排行为核心,设三重评估体系(众包投票、专家 MT-Bench、P2L 预测模型)。2025 年开放第三方评测、注册公司并获 6 亿估值,截至 2025 年 7 月收录超 50 个模型,日均 20 万次投票,影响 AI 公司估值与订单。
© 版权声明
文章版权归作者所有,未经允许请勿转载。