
Gemini 3 Pro,
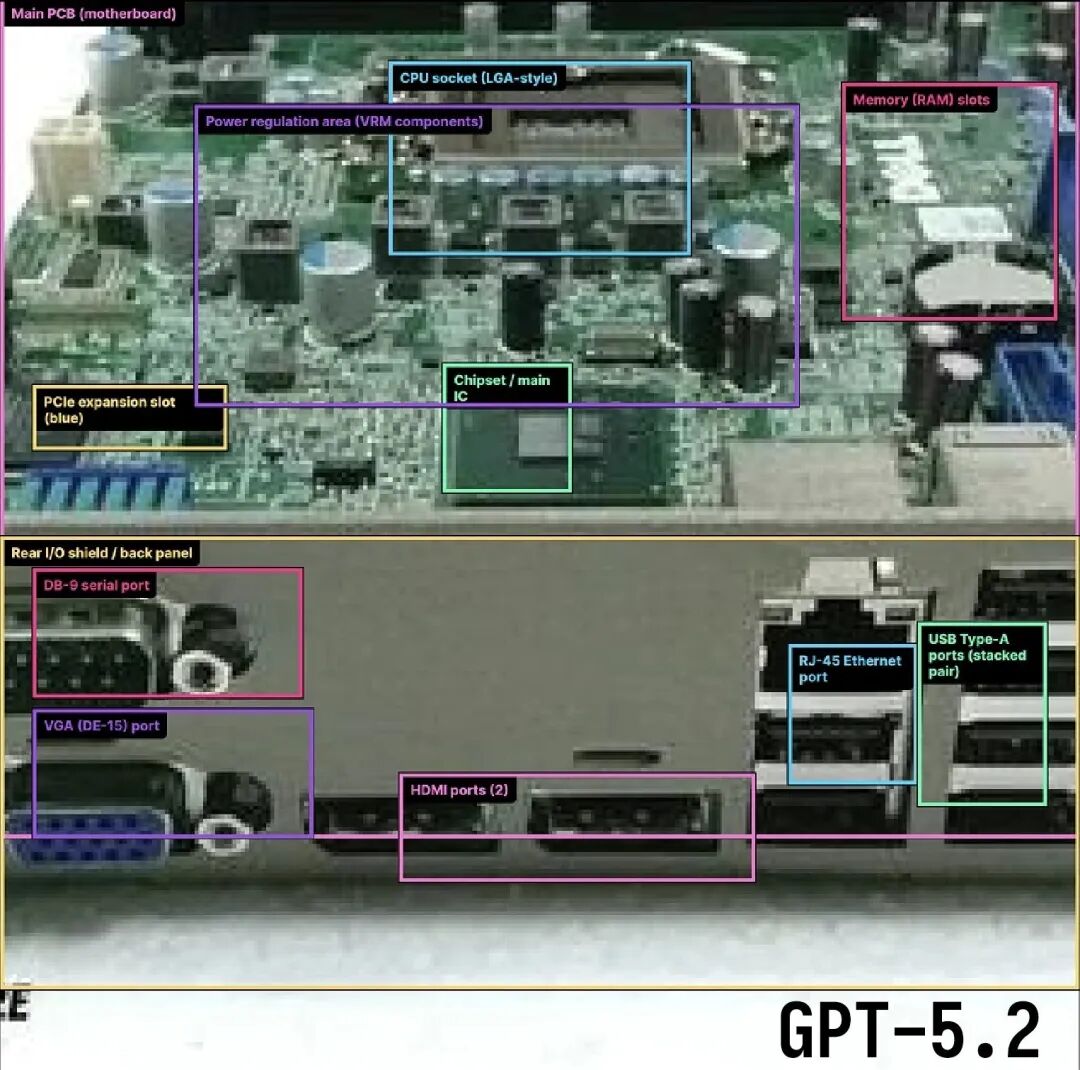
enmmm,有点不对,再看看OpenAI自己放出来的主case呢,一个电脑主板上面的元件和接口识别标记的case,结果连Gemini 2.5 Pro都没打赢


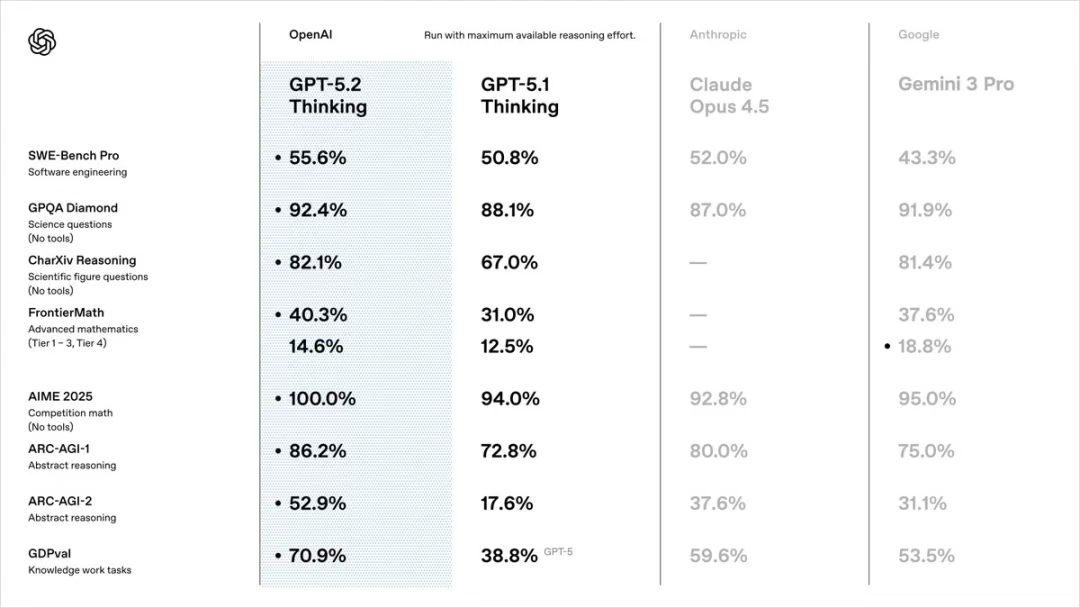
难道是我报告看劈叉了,再翻翻还是很顶,在AIME 2025(竞赛数学)拿满分,在 ARC-AGI-2(视觉推理)上拿到了 52.9%(翻了三倍,和 Gemini3 相当),在SWE-Bench Pro(软件工程)、GPQA Diamond(科学问题)上也抢回第一了,256K文档的四针测试正确率离谱到100%,知识截止日期也更新到25年8月份了。怪不得之前有人P图GPT5.2全系第一。。。
重点在GDPval和ARC-AGI-2,

简单来说,OpenAI想测试模型在真实世界对GDP的贡献,可以说是赚钱能力,GDPval这数据集就是从银行那调取的信息,选出对美國 GDP 贡献最大的 9 个行业中选出的 44 种职业,

1,320 个专业任务,每个任务都由平均有 14 年以上领域经验的专业人士设计,任务本体包含了参考文件和背景信息,预期的输出涵盖文档、ppt、图表、电子表格和多媒体。

🔗https://arxiv.org/pdf/2510.04374测试的case长这样,GPT 5.2 Thinking的平均得分比GPT 5.1 Thinking高9.3%,还是比较明显能看到区别的。
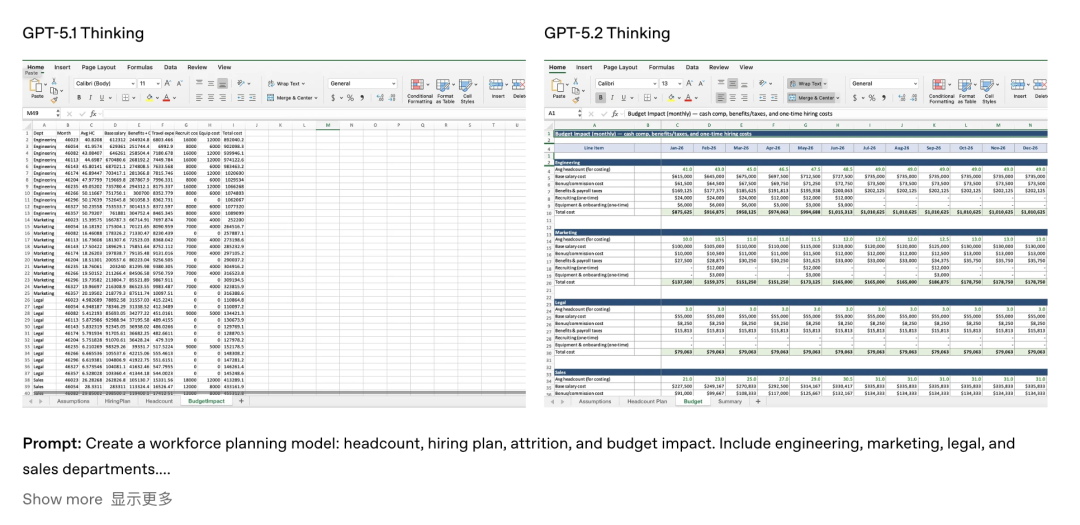
我用Gemini 3 Pro搓了一个贼复杂的Excel提示语,直接搭一个完整的模型。
GPT 5.2 Thinking跑啊跑,跑了半小时,把我所有的要求都实现了,以后出门在外自称是Excel专家没得问题了。再试一个常见的视频转录任务,GPT 5.2 Thinking没有内置工具,所以它会联网搜索一个免费转录的工具,转录后再把结果整理好给我。
再来再来,既然转录也能找到免费了,说不定PDF排版也行。
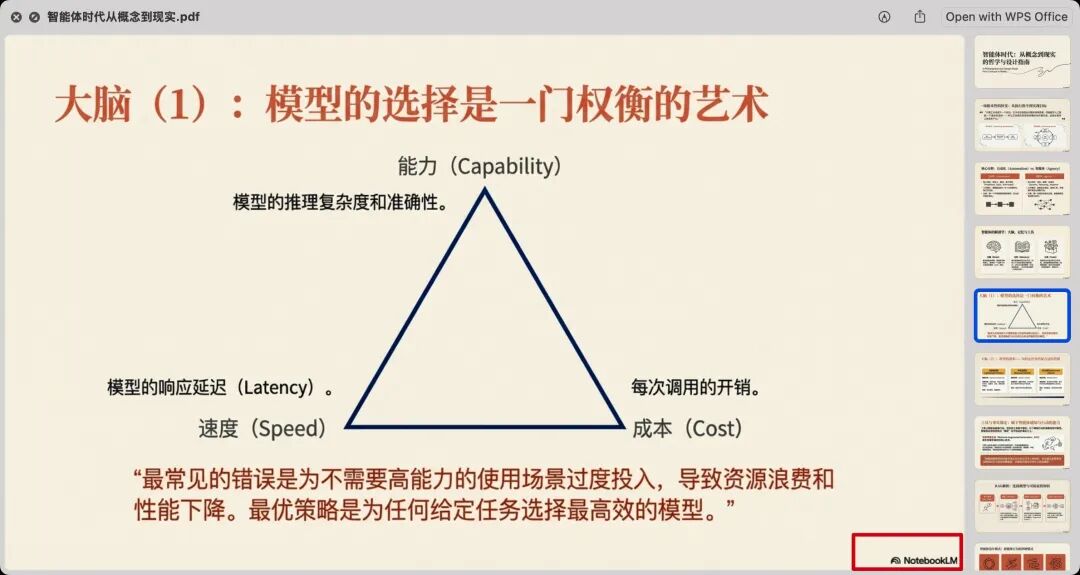
GPT2.5的解法是将图片和结构图等截图放到word里面,我看下来就只有代码部分会出现行号和文字排版多了换行,其他文字和格式都保留下来了。我必须要额外吐槽一下instant,thinking和pro这个后缀,穿插在报告里面看到眼花。我愿称之为AI界的中杯大杯超大杯

除了牛马预备役的设定外,GPT 5.2在ARC-AGI-2的性能也很强,用人话说,就是看看模型在完全没见过的图像推理题上表现怎么样。这有个术语,流体智力(Fluid Intelligence),不依赖于已有的知识,在全新情境下进行逻辑推理、识别模式和解决问题的能力。

我记得第一代的时候我当时找了一堆人,做10条只对了3条。GPT 5.2的得分到了52.9%,比GPT 5.1高35.3%,正确率过半了。GPT 5.2有一个我印象比较深刻的case,就是这个3D深海,这个光影我反手就是一个3A大作。
我一开始看那么简单的提示语嘴都笑歪了,结果后面不只我一个人发现了thinking和pro会时不时降智。@向阳乔木用的同一个手柄提示语,用instant,thinking和pro生成的三张图,
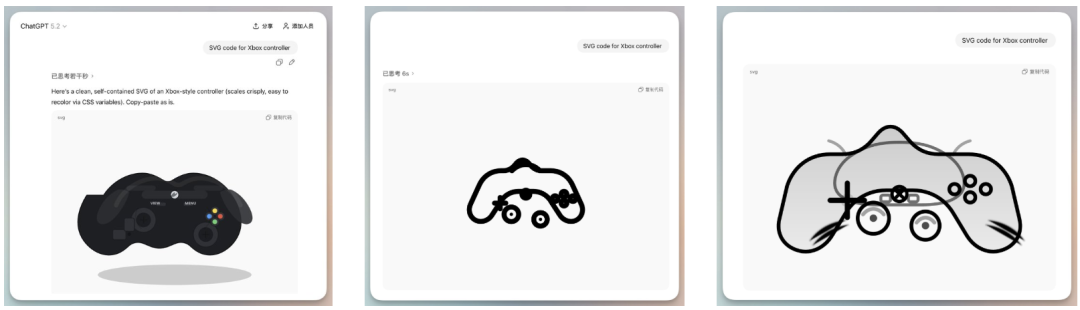
所以我后面干脆改用GPT5.2(无后缀版)抽卡了,还是可以抽出(抽了一晚上)相当不错的效果的,小球弹跳3D版,
以及模拟官方case的3D海浪,
@karminski-牙医得到的结论也很一样,下面两个演示动画是我节选他跑的一部分效果,我觉得可以基本实锤了。测试中的GPT 5.2 thinking和pro差距并不大, 但价格差了11倍。大象牙膏测试,甚至不如 GPT5,粒子效果还不如国产开放权重模型,
鞭炮连锁爆炸测试, 建模和光照, 粒子效果都非常好, 但追求画质的结果就是牺牲了性能,
总的来说,模型写出来的代码都挺好看,但性能没太大进步。最后,来测试看看GPT5.2的写作能力吧,既然都囊括了44种职业了,那文案是不是也要拉上来。我基本都是一个固定提示语测试,太短了看不出AI味,太多提示语限制的话看不出最低下限

尽力了,3k字压成图片传上来还是有点糊的,怎么说呢,GPT5.2的AI味还是重,破折号双引号冒号顿号,固定的不是…而是的句式还是时不时会弹出来,但是这个故事的本身设定我还是很喜欢的,不再完美的AI零七和被算法讨厌的噪音工程师林佑的联手还蛮有看点的。最后的最后,GPT-5.1三个月后也会下线,我们又一次告别了一个GPT开头的模型,GPT5.2发布当天,OpenAI十周年这周,奥特曼写了一封公开信《Ten Years》,他说,再过十年,我们几乎肯定能造出超级智能。实话说,我对OpenAI的感情是复杂的,Gemini 3.0 Pro 独一档强,Claude基本不能用的情况下,我是真心希望GPT5.2能支棱起来,别真被彻底超过了,多多优化模型吧。
@ 作者 / 卡尔
© 版权声明
文章版权归作者所有,未经允许请勿转载。