

这次他们放出来的cases基本就是照着Banana2来的,多文本生成,文字信息海报,世界知识等等,那我肯定要满足他们的愿望,来一个GPT Image 1.5和Banana2世纪大PK,十二个场景一次性看爽!老规矩所有提示语和图片都打包了,公众号回复“gpt生图”就行先来个6*6网格多元素生成的地狱case热热身,
这是Banana2的,虽然单个元素的画风会比GPT Image 1.5顺眼,但确实列数超过了,有些元素重复生成,

GPT Image 1.5,

第一局用的是GPT Image 1.5的case,第二局轮到Banana2的主场了,
看来GPT Image 1.5的中文还没训练够完整,中文错字好高,反而是拼音注音的准确率还高点,

Banana2做出来的长这样,

OK。马上进入第三局世界知识PK,还是Banana2的主场case,这次就直接开始图生图了,

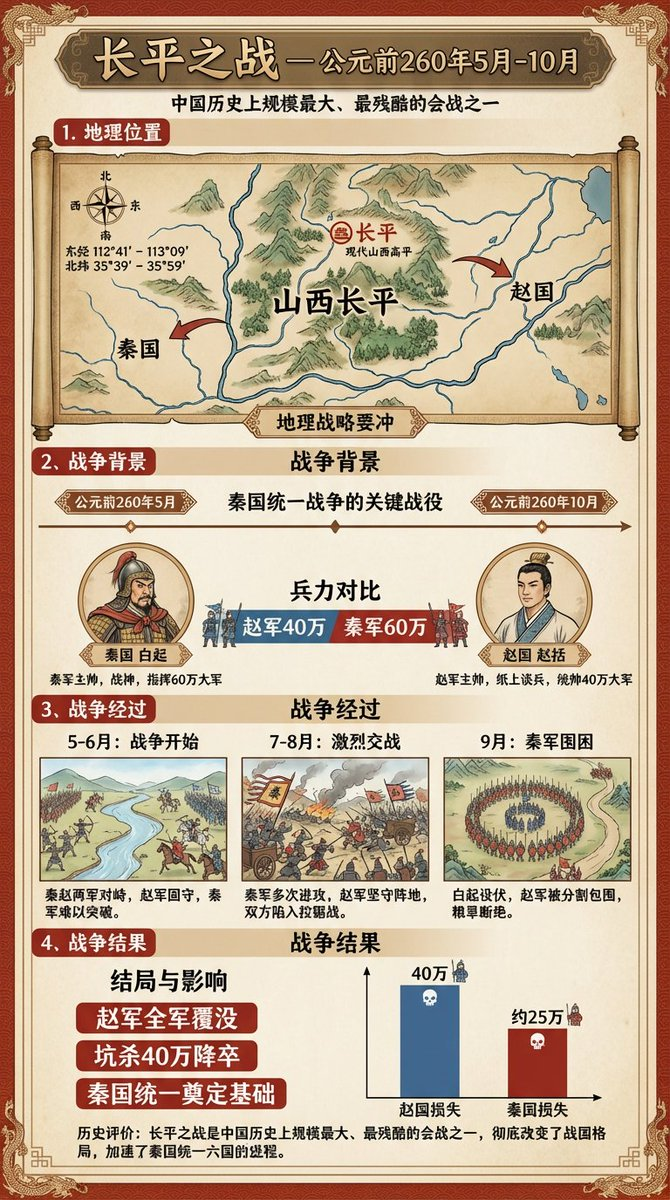
第一眼我真的有被唬到,但我发现数值跟Banana2有点不太一样,这张图里桥面离水面的高度数据最大跨度是对的,其他的都是错误的。
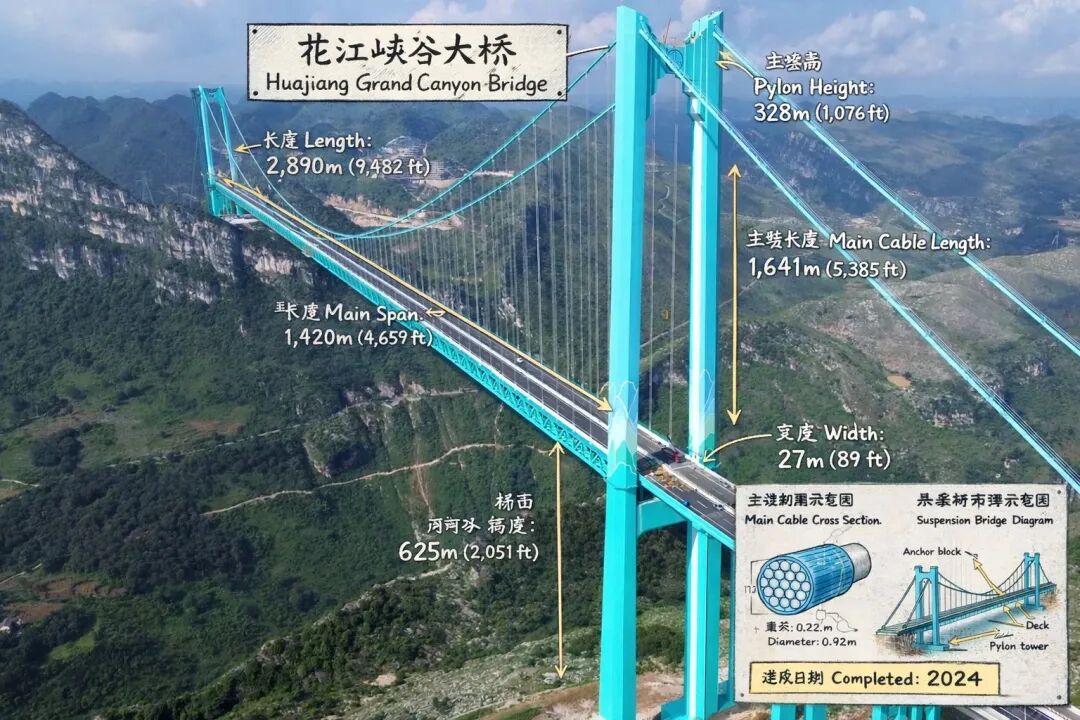
Banana2做出来的数据的正确率高很多,

看来要降低一点难度,做点信息图或者海报了。还有就是我真没有欺负GPT Image 1.5,生成过程也是会用到GPT 5.2补充知识的,所以通过经纬度还是可以做对应地点的历史海报的。
GPT Image 1.5,
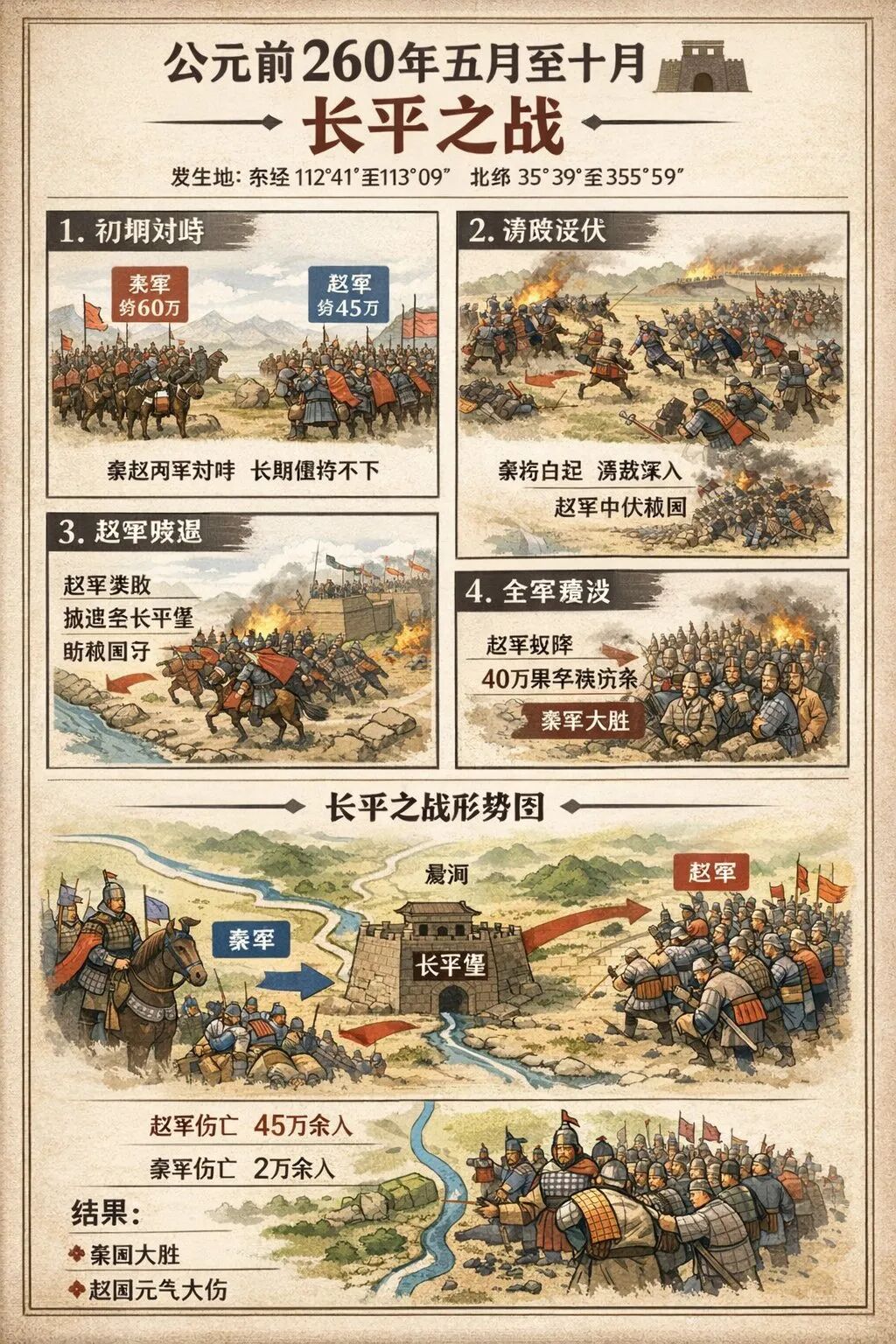
Banana2,
测到现在感觉没啥悬念,1.5有点压不住2啊,OpenAI还给GPT Image 1.5列出了几个小的质量更新,比方说生成非常非常非常非常多的小面孔也不会崩。
Banana2做出来的长这样,

一拉大的话从第四列的人开始脸就开始崩了

但GPT Image 1.5做出来的这个真的会伪人到我做噩梦的程度,优化在哪了?

还有什么能测的呢?多图融合和精确修改还可测测看,因为ChatGPT一次只能上传10个图片,所以我传了10个毛茸茸做多图融合
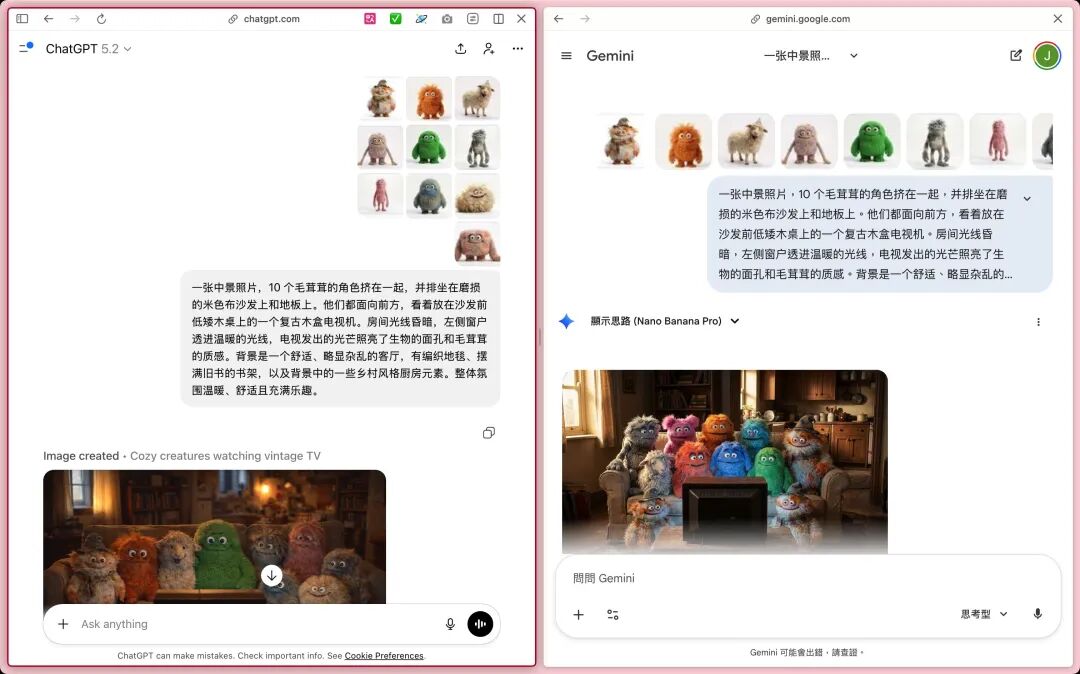
这个case就有点区分不出来哪个比较好了,两个都有漏角色,重复生成的,GPT Image 1.5是少生成了一个,Banana2是多生成了一个,GPT Image 1.5,

Banana2,

图像修改的话,GPT Image 1.5刚好碰上Banana2更新了,上传图片的时候可以画圈,箭头,文字来指定修改,

左侧case没找到出处,右侧是@歸藏佬做的让GPT Image 1.5也挑战一下吧,
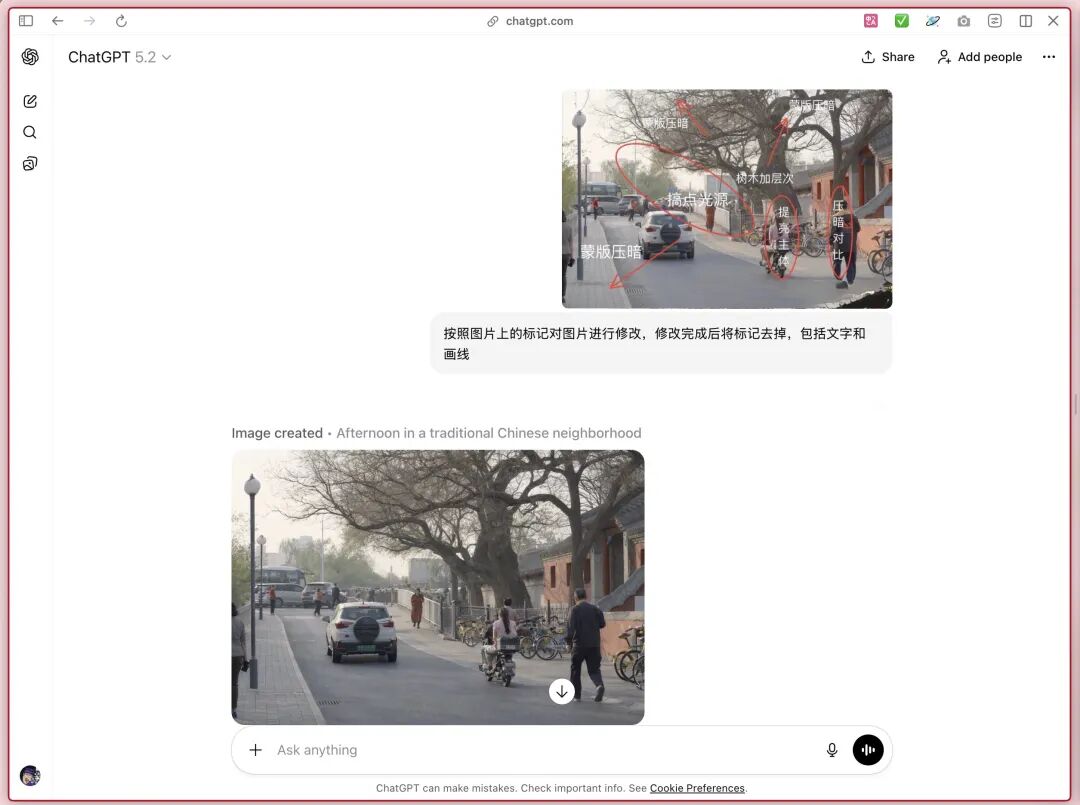
画面我是真没太看出来明暗有什么变化,但是划线花圈文字啥的确实都抹除了,换个case来看会更加明显,三个不同颜色的圈圈成功了一个。

OpenAI也主动承认了GPT Image 1.5在风格化上会比上一代要差,想要表现好的话可以用提供的滤镜,不过只有13种够谁用啊。
再拉我也测试看看,

可能是我做的时候对GPT Image 1.5没抱太大期望,这把他居然是还行的,

左边是GPT Image 1.5右边是Banana2把一张九宫格图做成完整视频目前应该是只有Sora2能做到,之前我都用Banana2做图的,今天刚好也试试看GPT Image 1.5做的效果。

GPT Image 1.5生成的九宫格里面画风偏了我就不挑了,问题是这个九宫格它前后有逻辑顺序吗?

Banana2做出来的逻辑性会强很多,

当然我这个没有用原版的九宫格生成提示语(太长了放链接),Banana2联动可灵正确玩法!我现在做Ai视频只要一张图就够了那个是会分析图片里所有关键元素,强制对应真实世界里的某一个片子的。GPT Image 1.5做出来的长这样,也没好多少。。。

最后我用Grok汇总了一下两个模型的对比,就更没想到GPT Image 1.5有啥竞争力了,可能就是生图速度快点了,但光快也没用啊。。。

Greg给GPT Image 1.5站台做的case也被Banana2比下去了。
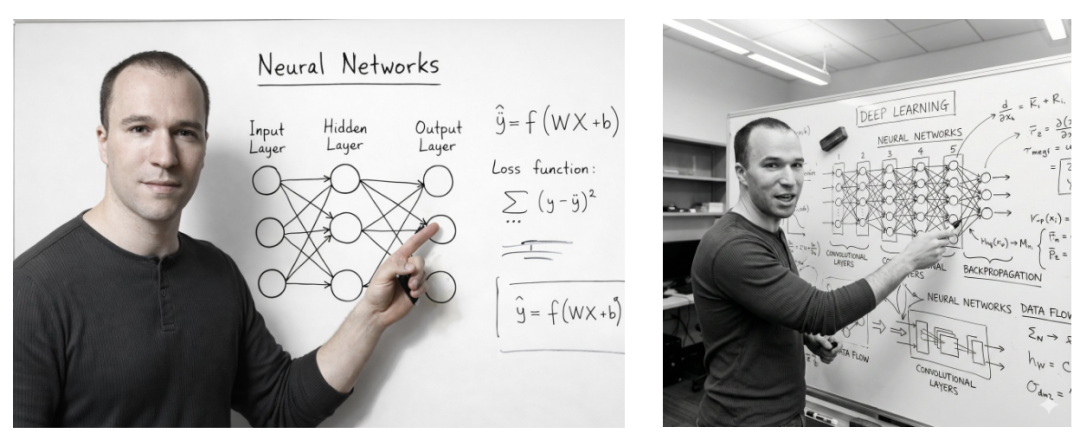
对了对了,差点忘了当时Banana2惊艳我的线稿上色的case了,

从左到右是原图,Banana2,GPT Image 1.5还有还有还有,测到停不下来了,
这一把又测到凌晨六点了,该洗洗睡了,这句话我送给我自己,也送给GPT Image 1.5,测试过程中发现Banana2懂中文已经把我养刁了,别的缺点都可以忍,不会中文是真忍不了一点要不要考虑学学隔壁Sora2,找点IP联名后再来挑战吧。
@ 作者 / 困得不行的卡尔
© 版权声明
文章版权归作者所有,未经允许请勿转载。


