两个模型:
①面向云端与高性能集群场景的GLM-4.6V(106B)②面向本地部署与低延迟应用的GLM-4.6V-Flash(9B)
我已经用上了,说实话,视觉能力真的可以,我们做了很多AI产品,有用到视觉能力的准备切换到这个模型了。
GLM-4.6V 跟之前“看懂再回答”的视觉模型完全不同,它把最关键的一步补齐了,把 Function Call 原生融入视觉模型,让模型可以根据图片、截图、文档页面等视觉输入,直接规划并调用工具,完成从感知到行动的闭环。
三大亮点

在 20+ 主流多模态基准取得同规模开源模型中的 SOTA。
106B 版本比肩 2 倍参数量的 Qwen3-VL-235B;9B 的 Flash 版本性能超过 Qwen3-VL-8B。
GLM-4.6V 将上下文长度提升到128K tokens,面向长文档、多文档和长视频理解更友好。
性价比
API 价格腰斩 + Flash 免费。
价格上,GLM-4.6V 相比 GLM-4.5V下调 50%,百万 tokens 输入 1 元/输出 3 元,同时 GLM-4.6V-Flash 免费开放给开发者使用。
这下应该没人会说视觉模型贵了。

GLM-4.6V API 的价格,实在是让开发者们爽爆了。
原生视觉工具调用
传统工具调用大多依赖纯文本,遇到图像、视频、复杂文档往往要反复 OCR/解析/对齐,链路长、损耗大。
GLM-4.6V 的设计思路是把视觉输入、工具调用、视觉结果再理解变成原生能力,给多模态应用落地极大降低了门槛。
从“视觉问答”到“视觉执行”
我是在官网买了个首月 20 元的套餐,确实是划算,但还有更重要的,官方给搞了专用 MCP 工具,用起来比较方便。



文档也是非常齐全,真的要给 GLM 官方点个赞,就差安排个工作人员来帮我干活了。





GLM-4.6V支持像素级前端复刻
现在我们用这个能力开发一个网站,索性直接来复刻升级一下智谱自己的网站吧,看看智谱的模型能不能超越他们自己的前端程序员。(哈哈哈,不知道当讲不当讲,我觉得他们的模型肯定比他们自己的程序员都厉害)
输入提示词和两张图片。






Icon 这些有点差别,不过不影响大局,正常是需要把这些 icon 素材都丢给它的,这里测试就不去搞了。

上才艺!
我上传了一段足球直播片段,让它帮我找到射门的精彩瞬间,并且截取出来这个片段。


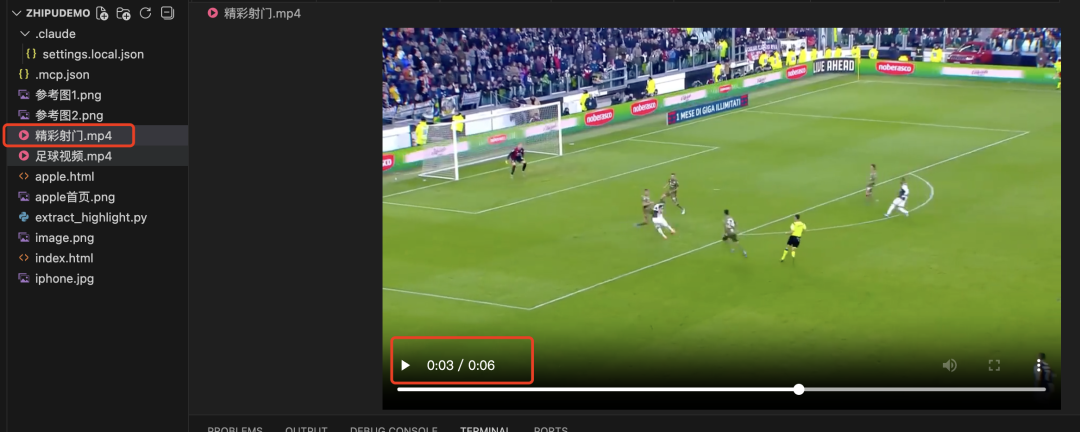
这真的很夸张,意味着可以有更多的想法可以落地了,我们平时开发 APP 很快,之前有很多想法因为一些模型能力的限制被搁置了,有了GLM-4.6V,我感觉我好像又行了。
写在最后
模型能力强、价格低,基本等于把“上视觉”这件事从小团队的奢侈品变成了日常标配。
对开发者来说,最大的感受就一句话:可落地的想法变多了。
以前很多点子卡在成本、卡在模型能力、卡在最后一公里执行,有了 GLM-4.6V,很多本来要算了的功能突然就能开工了。
用 Coding Plan 把 MCP 接进 IDE,去体验一次“设计稿即代码”和“看图就能改”的爽感吧!
只要首月20元,就能拥有 Claude Pro 的三倍用量,可以调用 GLM-4.6 模型,同时还支持搜索、网页读取以及视觉理解等三个 MCP。

项目链接
Hugging Face:https://huggingface.co/collections/zai-org/glm-46v
GLM Coding Plan 视觉 MCP 文档:https://docs.bigmodel.cn/cn/coding-plan/mcp/vision-mcp-server
在线体验:z.ai (选择 GLM-4.6V 模型)

© 版权声明
文章版权归作者所有,未经允许请勿转载。