1. 音频特征提取系统首先使用WeNet模型从输入音频中提取语音特征:
-
音频预处理:在音频前后添加静音段以确保特征提取的稳定性 -
MFCC特征提取:将音频转换为梅尔频率倒谱系数(MFCC)特征 -
深度特征提取:使用WeNet的Conformer编码器提取更高层次的语音表示 -
特征适配:将提取的特征适配到与视频帧率相匹配的时间维度
2. 人脸特征提取与处理系统使用SCRFD人脸检测器和PFPLD关键点检测器从参考视频中提取人脸特征:
-
人脸检测:使用SCRFD模型检测每一帧中的人脸位置 -
关键点定位:使用PFPLD模型提取人脸的68个关键点 -
面部掩码生成:基于关键点生成面部区域掩码,重点关注嘴部区域 -
面部对齐:将检测到的人脸裁剪并对齐到标准尺寸
3. 数字人面部动画生成这是核心步骤,系统使用一个深度学习模型将音频特征映射到面部动画:
-
模型架构:基于生成对抗网络(GAN)的架构,包含生成器(G)和判别器(D) -
输入融合:将音频特征、参考人脸图像和面部掩码作为输入 -
口型合成:生成器网络根据音频特征调整嘴型,生成与语音同步的面部动画 -
融合处理:将生成的面部动画与原始人脸图像进行平滑融合
4. 视频合成与后处理
-
帧合成:将生成的面部动画逐帧合成到视频序列中 -
超分辨率处理:根据需要对视频帧进行超分辨率增强 -
视频编码:将处理后的帧序列编码为最终视频,并与原始音频合成
工作流程总结
- 准备阶段:
-
加载参考视频(提供数字人的外观) -
加载驱动音频(提供说话内容和语调) - 特征提取阶段:
-
从音频中提取语音特征(音素、语调等) -
从参考视频中提取人脸特征(面部结构、关键点等) - 动画生成阶段:
-
使用深度学习模型将音频特征映射到面部动画参数 -
根据这些参数调整嘴型和面部表情 - 视频合成阶段:
-
将生成的面部动画与参考视频融合 -
进行必要的后处理(如超分辨率增强) -
与原始音频同步生成最终视频
这种技术被称为”音频驱动的面部动画”(Audio-driven facial animation),能够生成与语音高度同步的自然面部动画,特别适用于数字人、虚拟主播等应用场景。
https://www.mindtechassist.com/
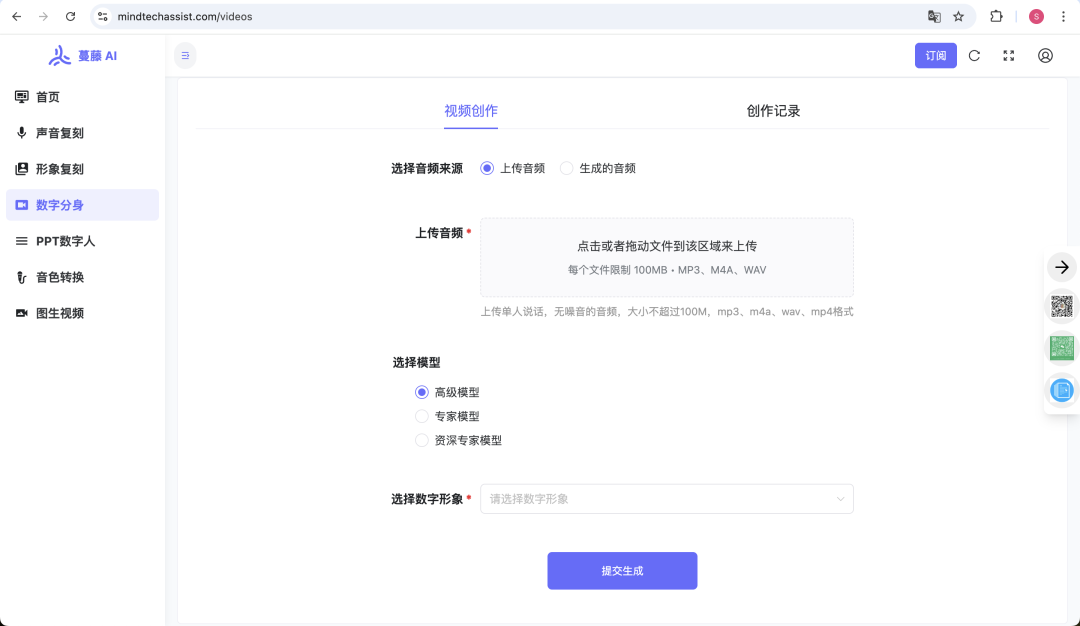


https://ai.feishu.cn/wiki/Mu5nwfNrqiytllkkrWhcuGbJnPh

© 版权声明
文章版权归作者所有,未经允许请勿转载。