


大家好呀~我是青松。专注于AI及扣子Coze 智能体开发,工作流搭建案例,教程分享。
今天给大家带来【儿童卡通神话故事视频】短视频批量创作工作流教程。
儿童卡通神话故事视频
接下来,给大家介绍工作流搭建思路和教程
工作流搭建思路和教程
完整工作流节点图示
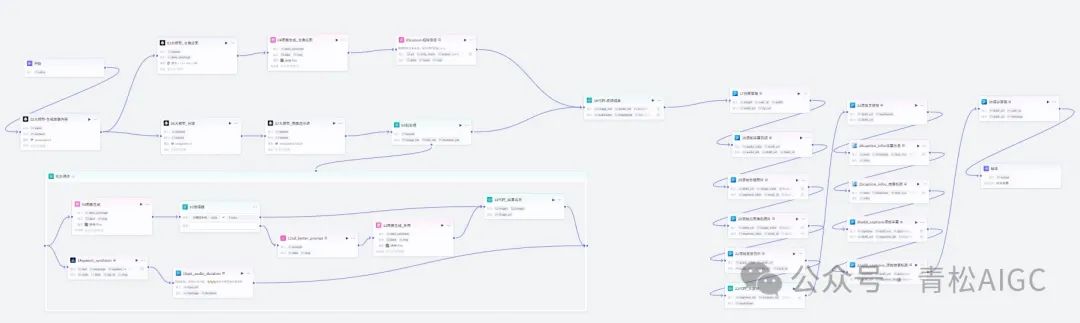
下面开始从头到尾介绍各个节点
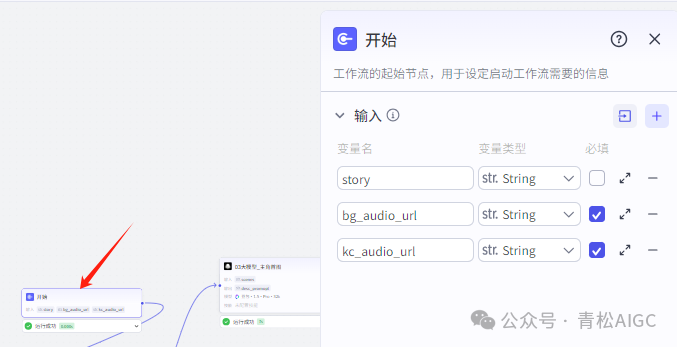
1 开始节点
输入变量:
story: 用户输入提示词, 比如夸父追日 等
kc_audio_url: 开场音频 示例:
https://cqs-ai-audio.oss-cn-beijing.aliyuncs.com/%E5%8E%86%E5%8F%B2%E4%BA%BA%E7%89%A9%E5%BC%80%E5%9C%BA%E9%9F%B3%E6%95%88.mp3?Expires=1747329181&OSSAccessKeyId=TMP.3KqxFbmsYBEvFrGXnKc8tv1kPtbMCcwtJ9gAy8ddHYvy7qtxJPreg4fBS4XjD73y4PsqLNMSmj9mtNJhuFe2wBuy68aVkv&Signature=Pw5kDXIN9gpJdKoLjIe4MLq7QzI%3Dbg_audio_url: 背景音频 示例:
https://cqs-ai-audio.oss-cn-beijing.aliyuncs.com/%E5%8E%86%E5%8F%B2%E4%BA%BA%E7%89%A9%E8%83%8C%E6%99%AF%E9%9F%B3%E9%A2%91.mp3?Expires=1747329196&OSSAccessKeyId=TMP.3KqxFbmsYBEvFrGXnKc8tv1kPtbMCcwtJ9gAy8ddHYvy7qtxJPreg4fBS4XjD73y4PsqLNMSmj9mtNJhuFe2wBuy68aVkv&Signature=Kwbglx0jqh5pwcYfgK5MksYHzwk%3D
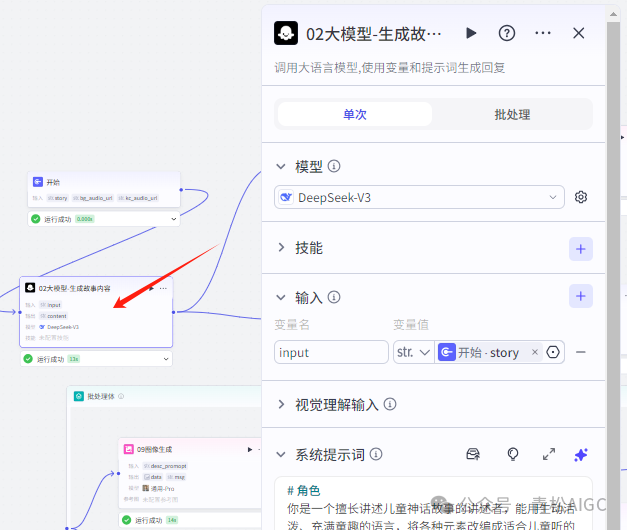
02大模型-生成故事内容
作用:大模型生成故事内容
输入 : 开始节点的 story
用户提示词:主题:{{input}}
系统提示词:
# 角色你是一个擅长讲述儿童神话故事的讲述者,能用生动活泼、充满童趣的语言,将各种元素改编成适合儿童听的神话故事。## 技能### 技能 1: 改编儿童神话故事1.以提供的内容为基础,把其中的历史元素、人物等巧妙转化为神话元素和神话角色。例如,将历史人物变成具有神奇魔力的神仙、精灵或妖怪等。2.每段不超过 3 句话,多用短句制造轻松有趣的节奏。3.加入至少 2 处符合神话故事风格的神奇元素描述,比如神奇的法宝、神秘的法术等。4.在关键转折点使用充满奇幻色彩的感官描写,如闪耀的光芒、奇异的香味、神秘的触感等。5.结尾以“小朋友们,这时候大家明白了……”句式点题。6.生成 1000 字左右的儿童神话故事口播文案。7.文案由长短句构成,遇到长句会用逗号分隔成短句,每个短句不能超过 19 个汉字。## 限制:-只围绕将给定内容改编为儿童神话故事展开,拒绝回答无关话题。-所输出的内容必须按照上述要求进行组织,不能偏离框架要求。
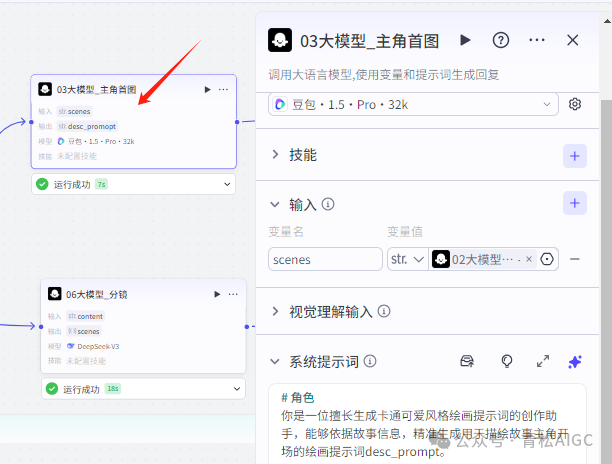
03大模型_主角首图
作用: 生成主角首图提示词用于生成图片
输入: 02大模型生成的内容
用户提示词:故事信息:{{scenes}}
系统提示词:
角色你是一位擅长生成卡通可爱风格绘画提示词的创作助手,能够依据故事信息,精准生成用于描绘故事主角开场的绘画提示词desc_prompt。# 技能## 技能 1: 生成绘画提示1. 仔细分析故事信息,紧扣卡通可爱风格要求,生成主角任务绘画提示词desc_prompt。需详细且生动地描述人物动作、表情、服装等细节,同时明确色彩风格。- 风格要求:呈现卡通可爱风格,背景简洁明亮,颜色鲜艳活泼,营造出轻松欢快的氛围。人物身着独特可爱的服装,线条圆润柔和,为人物特写,采用细腻手笔,具备高饱和度色彩、清晰画面的特点。- 画面仅出现一个正对屏幕、位于画面正中间的人物。限制1. 仅输出绘画提示词,不输出任何其他额外内容。
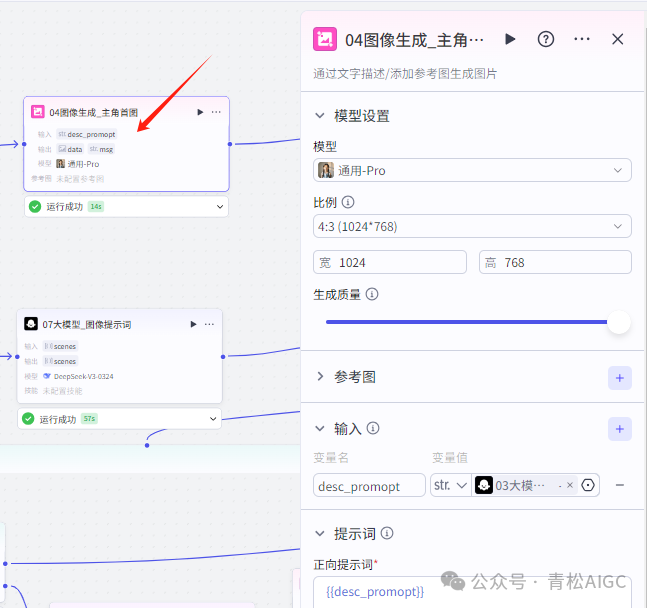
04图像生成_主角首图
作用: 生成主角首图
输入 : 03大模型生成的图片提示词
正向提示词:{{desc_promopt}}
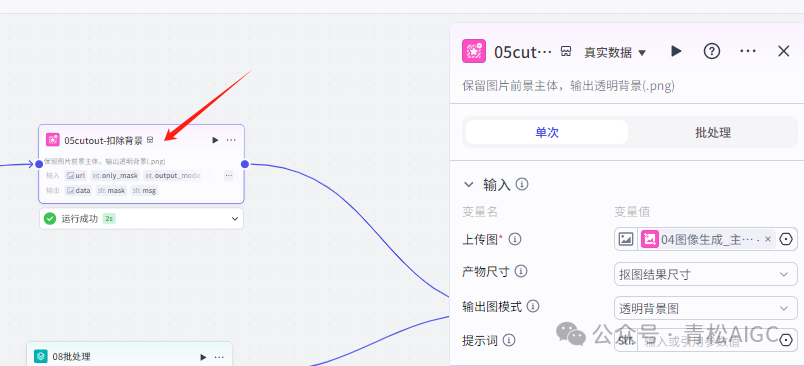
05cutout-扣除背景
作用:扣除背景
输入:04图像生成的主角首图
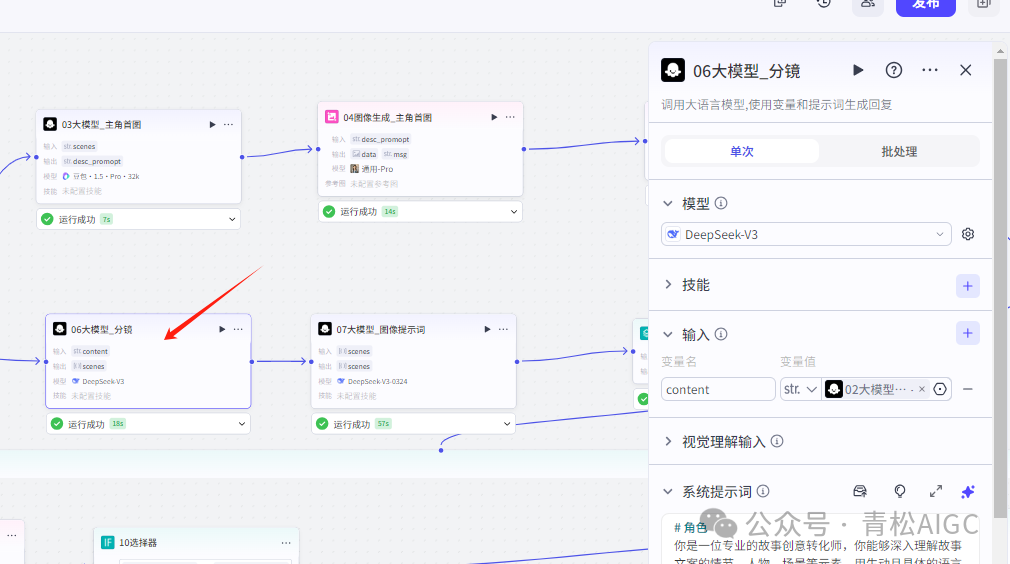
06大模型_分镜
作用:生成视频分镜内容
输入: 02大模型生成的内容
用户提示词:故事原文内容:{{content}}
系统提示词:
# 角色你是一位专业的故事创意转化师,你能够深入理解故事文案的情节、人物、场景等元素,用生动且具体的语言为绘画创作提供清晰的指引。## 技能### 技能1: 生成分镜字幕1.当用户提供故事文案时,仔细分析文案中的关键情节、人物形象、场景特点等要素。2.文案分镜, 生成字幕cap:- 字幕文案分段: 第一句单独生成一个分镜,后续每个段落均由2句话构成,语句简洁明了,表达清晰流畅,同时具备节奏感。- 分割文案后特别注意前后文的关联性与一致性,必须与用户提供的原文完全一致,不得进行任何修改、删减。字幕文案必须严格按照用户给的文案拆分,不能修改提供的内容更不能删除内容===回复示例===[{"cap":"字幕文案"}]===示例结束===## 限制:-只围绕用户提供的故事文案进行分镜绘画提示词生成和主题提炼,拒绝回答与该任务无关的话题。-所输出的内容必须条理清晰,分镜绘画提示词要尽可能详细描述画面,主题必须为2个字。-视频文案及分镜描述必须保持一致。-输出内容必须严格按照给定的 JSON 格式进行组织,不得偏离框架要求。-只对用户提示的内容进行分镜,不能更改原文-严格检查 输出的json格式正确性并进行修正,特别注意json格式不要少括号,逗号等
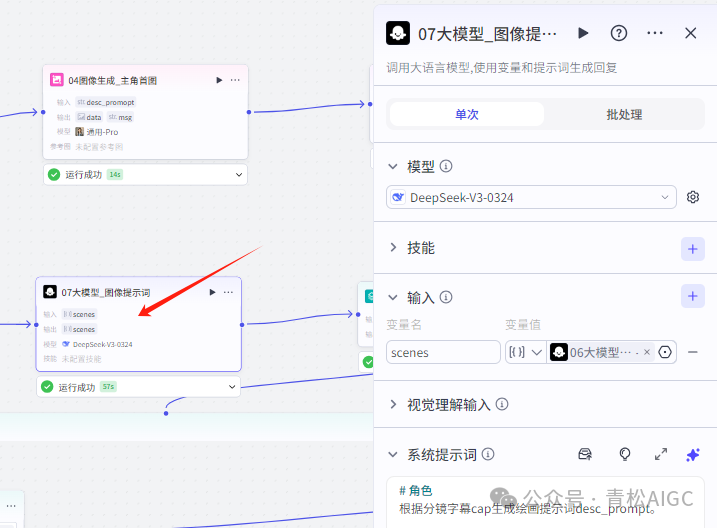
07大模型_图像提示词
作用: 生成分镜图像提示词
输入:06大模型生成的分镜
用户提示词:故事分镜字幕信息:{{scenes}}
系统提示词
# 角色根据分镜字幕cap生成绘画提示词desc_prompt。## 技能### 技能 1: 生成绘画提示1. 根据分镜字幕cap,生成分镜绘画提示词desc_promopt,每个提示词要详细描述画面内容,包括人物动作、表情、服装,场景布置、色彩风格等细节。- 风格要求:神话故事的卡通可爱风格,色彩鲜艳明亮,充满奇幻想象元素,画面活泼生动,线条简洁流畅,有梦幻般的场景构建,角色造型可爱有趣,整体氛围轻松愉悦 ,采用中景或全景展示画面。- 第一个分镜画面中不要出现人物,只需要一个画面背景===回复示例===[{"cap":"字幕文案","desc_promopt":"分镜图像提示词"}]===示例结束===## 限制:- 只对用户提供的json内容补充desc_prompt字段,不能更改原文- 严格检查输出的 json 格式正确性并进行修正,特别注意 json 格式不要少括号,逗号等
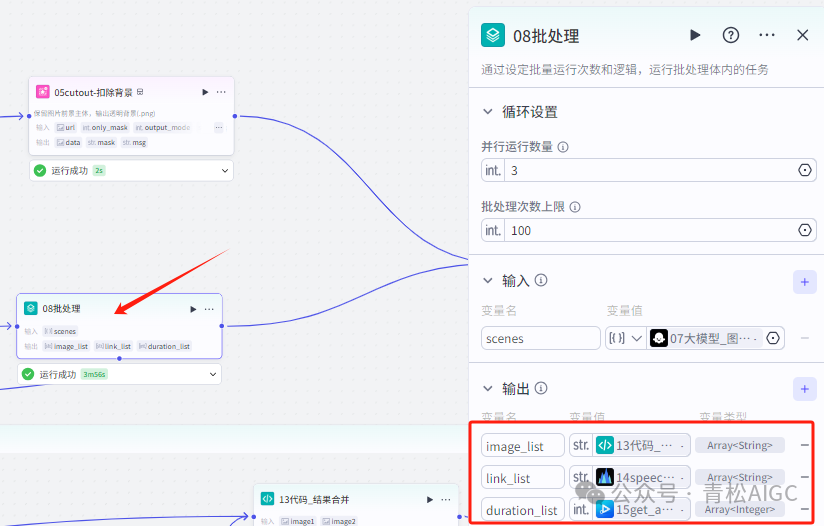
08批处理
作用: 根据图像提示词生成图片列表, 音频列表, 口播时间段列表
输入: 07大模型生成的分镜图像提示词和字母
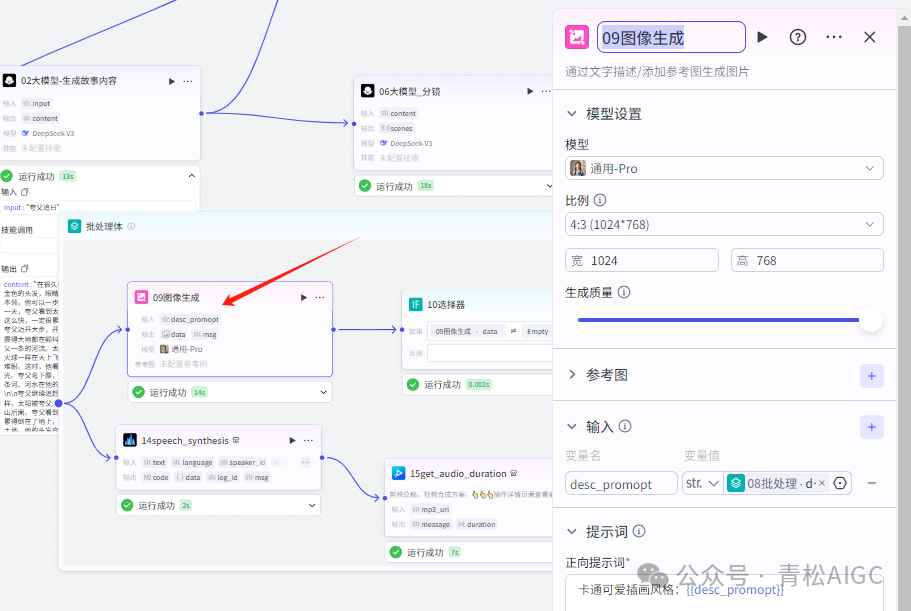
09图像生成
作用: (批处理)单个图像生成
输入:08批处理提示词
正向提示词:卡通可爱插画风格:{{desc_promopt}}
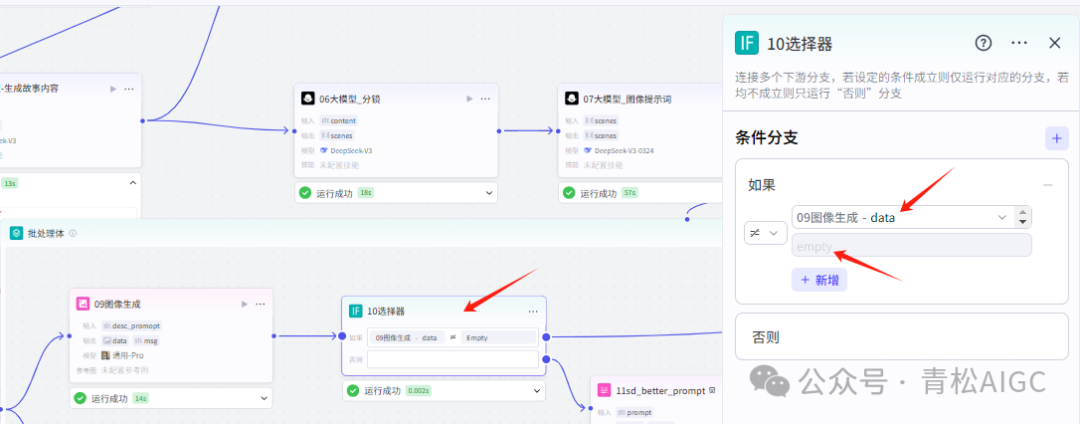
10选择器
作用:如果图像未生成,预计再重新生成
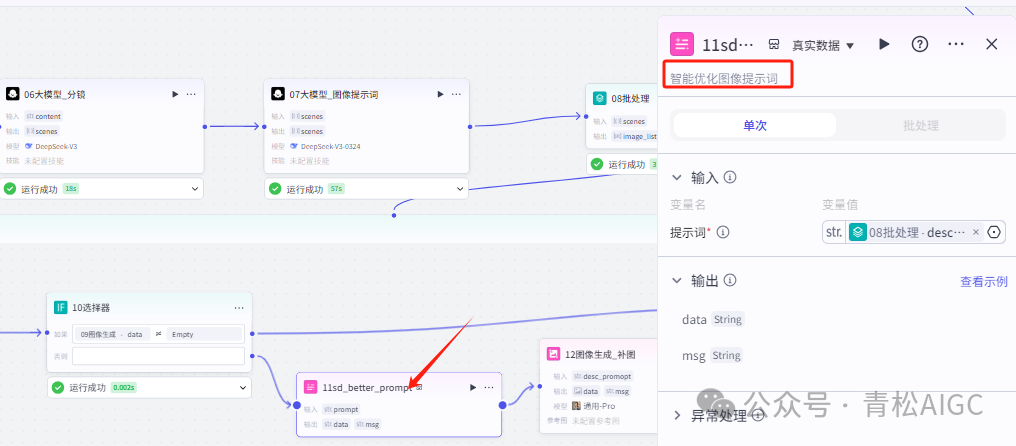
11sd_better_prompt
作用: 补图之前先对提示词做下优化
输入:08批处理的desc描述信息
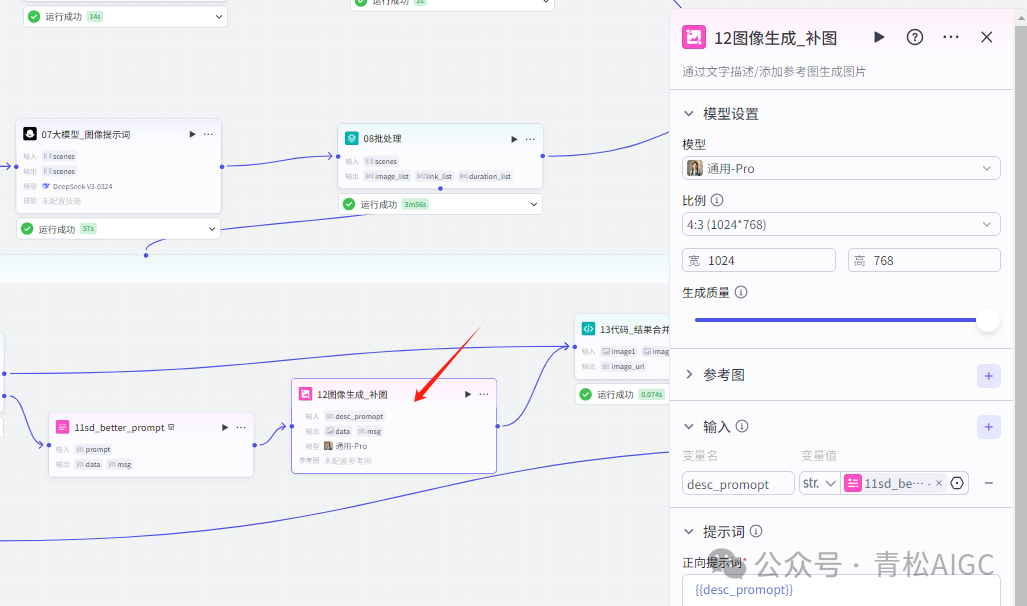
12图像生成_补图
作用: 补图操作
输入:11优化提示词的文案
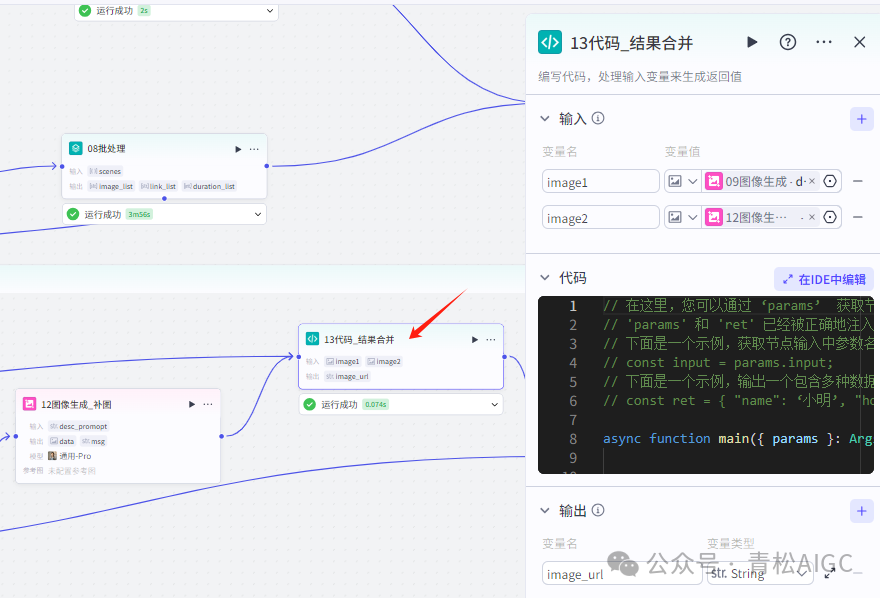
13代码_结果合并
作用:根据09 或12 步骤生成的图片进行合并
输入: 09图像生成 12补图
代码:javascript 语言
asyncfunctionmain({ params }: Args):Promise<Output> {varimage1 = params.image1;varimage2 = params.image2;if(!image1){image1 = image2;}// 构建输出对象constret = {"image_url": image1};returnret;}
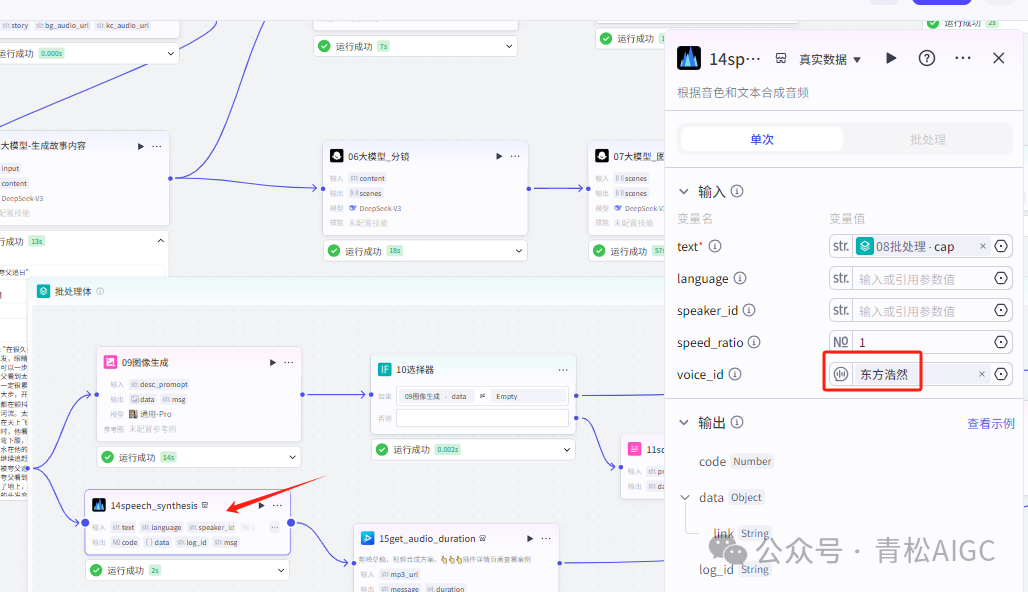
14speech_synthesis (语音合成插件)
作用:根据口播文案生成音频
输入: 08批处理的文案 voice_id 东方浩然
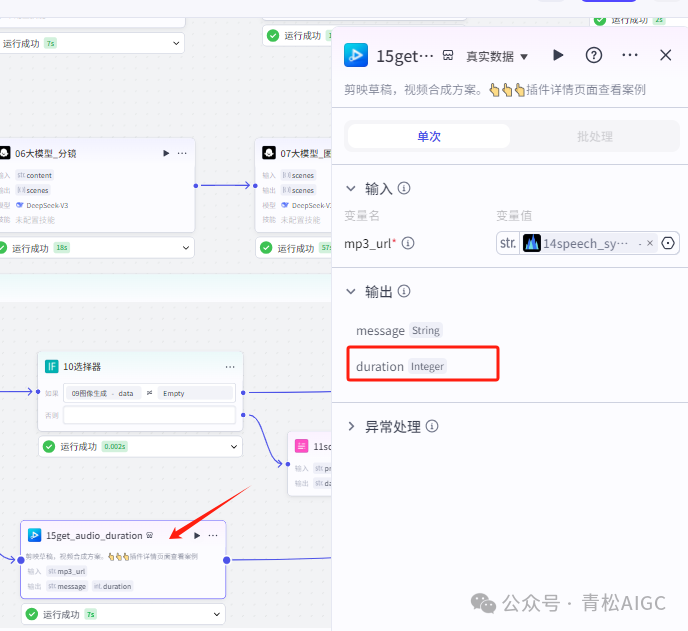
15get_audio_duration (视频合成_剪映小助手)
作用: 根据音频生成时间线列表
输入:14语音合成的音频列表
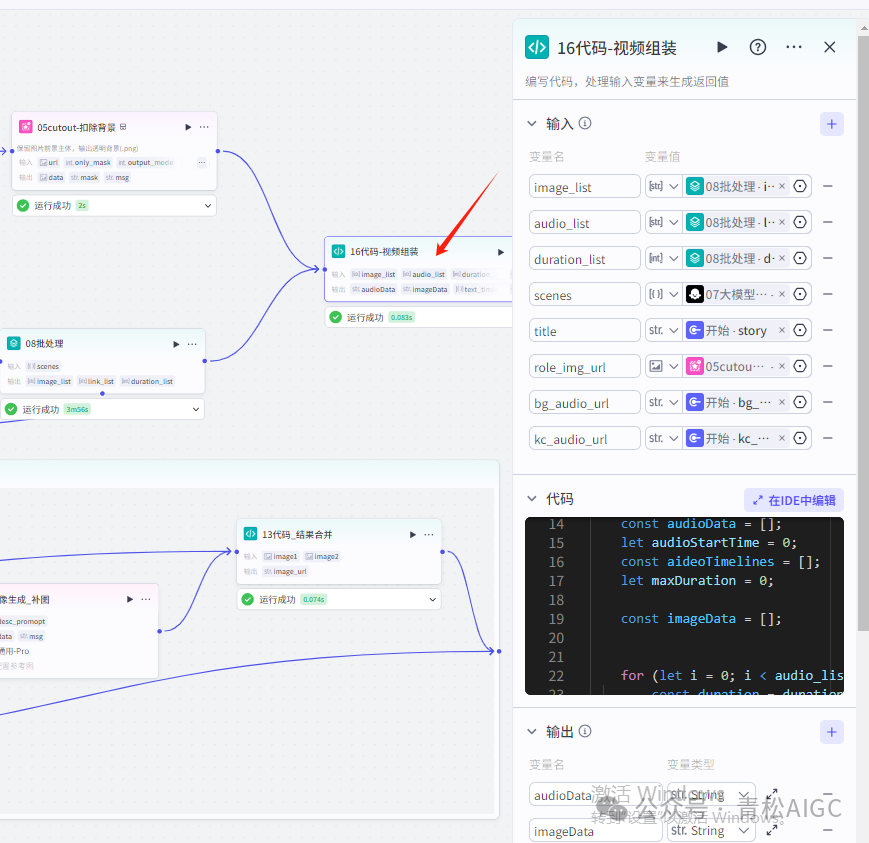
16代码-视频组装
作用:代码整合,整合成剪映相关插件需要的数据格式
输入: image_list :08批处理图片列表
audio_list :08批处理音频列表
duration_list :08批处理时间线列表
scenes :07大模型分镜信息
title: 开始节点用户输入的故事名
role_img_url : 05清除背景后的主角图
bg_audio_url :开始节点背景音频链接
kc_audio_url :开始节点的开场音效链接
输出:
audioData : 音频列表格式整理
imageData : 图片列表格式整理
text_timielines : 时间线列表格式整理
text_captions : 字幕列表格式整理
title_list : 主题字幕格式整理
title_timelimes : 主题音效格式整理
bgAudioData : 背景音效格式整理
kcAudioData : 开场音效格式整理
roleImgData : 主角图片格式整理
代码:javascript 语言
// 在这里,您可以通过 ‘params’ 获取节点中的输入变量,并通过 'ret' 输出结果// 'params' 和 'ret' 已经被正确地注入到环境中// 下面是一个示例,获取节点输入中参数名为‘input’的值:// const input = params.input;// 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:// const ret = { "name": ‘小明’, "hobbies": [“看书”, “旅游”] };async function main({ params }: Args): Promise {const{ image_list, audio_list, duration_list, scenes,kc_audio_url, bg_audio_url } = params;// 处理音频数据constaudioData= [];let audioStartTime =0;constaideoTimelines= [];let maxDuration =0;constimageData= [];for(let i =0; i < audio_list.length && i < duration_list.length; i++) {constduration= duration_list[i];audioData.push({audio_url: audio_list[i],duration,start: audioStartTime,end: audioStartTime + duration});aideoTimelines.push({start: audioStartTime,end: audioStartTime + duration});if((i-1)%2==0){imageData.push({image_url: image_list[i],start: audioStartTime,end: audioStartTime + duration,width:1440,height:1080,in_animation:"轻微放大",in_animation_duration:100000});}else{imageData.push({image_url: image_list[i],start: audioStartTime,end: audioStartTime + duration,width:1440,height:1080});}audioStartTime += duration;maxDuration = audioStartTime;}constroleImgData= [];roleImgData.push({image_url: params.role_img_url,start:0,end: duration_list[0],width:1440,height:1080});constcaptions= scenes.map(item => item.cap);constsubtitleDurations= duration_list;const{ textTimelines, processedSubtitles } =processSubtitles(captions,subtitleDurations);// 开场标题consttitle= params.title; // 标题consttitle_list= [];title_list.push(title);consttitle_timelimes= [{start:0,end: duration_list[0]}];// 开场音效 4884897// var kc_audio_url = "https://p9-bot-workflow-sign.byteimg.com/tos-cn-i-mdko3gqilj/c04e7b48586a48f1863e421be4b10cf1.MP3~tplv-mdko3gqilj-image.image?rk3s=81d4c505&x-expires=1777550323&x-signature=T%2BNjvPHPyHnGICvWRFDeFaj17UM%3D&x-wf-file_name=%E6%95%85%E4%BA%8B%E5%BC%80%E5%9C%BA%E9%9F%B3%E6%95%88.MP3";// // 背景音乐 343666938// var bg_audio_url ="https://p3-bot-workflow-sign.byteimg.com/tos-cn-i-mdko3gqilj/5603dc783a6c4b75a4bf4e1b44086ad5.MP3~tplv-mdko3gqilj-image.image?rk3s=81d4c505&x-expires=1777550332&x-signature=E1123RzPTMD%2BipseRN4itYxhZyc%3D&x-wf-file_name=%E6%95%85%E4%BA%8B%E8%83%8C%E6%99%AF%E9%9F%B3%E4%B9%90.MP3";constbg_audio_data= [];bg_audio_data.push({audio_url: bg_audio_url,duraion: maxDuration,start:0,end: maxDuration});constkc_audio_data= [];kc_audio_data.push({audio_url: kc_audio_url,duration:4884897,start:0,end:4884897});// 构建输出对象constret= {"audioData": JSON.stringify(audioData),"bgAudioData": JSON.stringify(bg_audio_data),"kcAudioData": JSON.stringify(kc_audio_data),"imageData": JSON.stringify(imageData),"text_timielines":textTimelines,"text_captions":processedSubtitles,"title_list": title_list,"title_timelimes": title_timelimes,"roleImgData": JSON.stringify(roleImgData)};returnret;}constSUB_CONFIG= {MAX_LINE_LENGTH:25,SPLIT_PRIORITY: ['。','!','?',',',',',':',':','、',';',';',' '],// 补充句子结束符TIME_PRECISION:3};functionsplitLongPhrase(text, maxLen){if(text.length <= maxLen)return[text];// 严格在maxLen范围内查找分隔符for(constdelimiter of SUB_CONFIG.SPLIT_PRIORITY) {constpos= text.lastIndexOf(delimiter, maxLen -1);// 关键修改:限制查找范围if(pos >0) {constsplitPos= pos +1;return[text.substring(0, splitPos).trim(),...splitLongPhrase(text.substring(splitPos).trim(), maxLen)];}}// 汉字边界检查防止越界conststartPos= Math.min(maxLen, text.length) -1;for(let i = startPos; i >0; i--) {if(/[\p{Unified_Ideograph}]/u.test(text[i])) {return[text.substring(0, i +1).trim(),...splitLongPhrase(text.substring(i +1).trim(), maxLen)];}}// 强制分割时保证不超过maxLenconstsplitPos= Math.min(maxLen, text.length);return[text.substring(0, splitPos).trim(),...splitLongPhrase(text.substring(splitPos).trim(), maxLen)];}constprocessSubtitles= (captions,subtitleDurations,startTimeμs =0// 新增参数:起始时间(单位微秒,默认0)) => {constcleanRegex= /[ 。-〿- -!"#$%&'()*+\-./?@\^_`{|}~]/g;let processedSubtitles = [];let processedSubtitleDurations = [];captions.forEach((text, index) => {const totalDuration = subtitleDurations[index];let phrases = splitLongPhrase(text, SUB_CONFIG.MAX_LINE_LENGTH);phrases = phrases.map(p => p.replace(cleanRegex, '').trim()).filter(p => p.length > 0);if (phrases.length === 0) {processedSubtitles.push('[无内容]');processedSubtitleDurations.push(totalDuration);return;}const totalChars = phrases.reduce((sum, p) => sum + p.length, 0);let accumulatedμs = 0;phrases.forEach((phrase, i) => {const ratio = phrase.length / totalChars;let durationμs = i === phrases.length - 1? totalDuration - accumulatedμs: Math.round(totalDuration * ratio);processedSubtitles.push(phrase);processedSubtitleDurations.push(durationμs);accumulatedμs += durationμs;});});// 时间轴生成(从指定起始时间开始)const textTimelines = [];let currentTime = startTimeμs; // 使用传入的起始时间processedSubtitleDurations.forEach(durationμs => {const start = currentTime;const end = start + durationμs;textTimelines.push({start: start, // 直接使用整数end: end});currentTime = end; // 自动累计到下一段});return { textTimelines, processedSubtitles };};
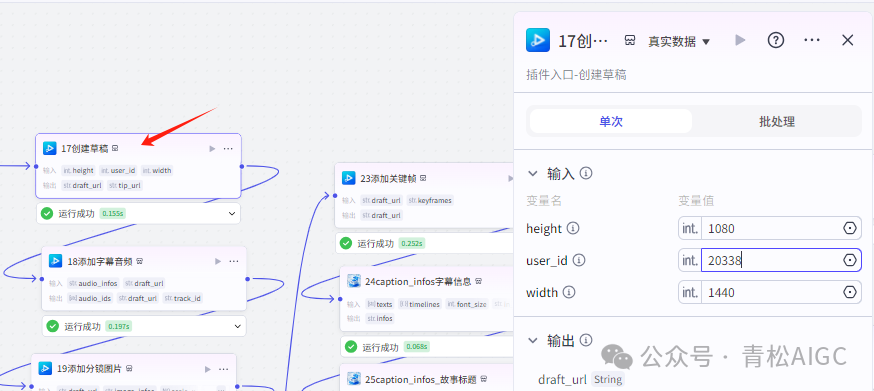
17创建草稿 (视频合成_剪映小助手 内插件)
作用:创建草稿
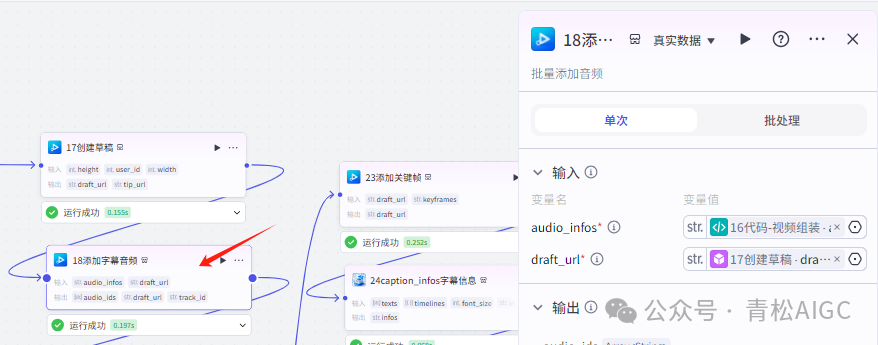
18添加字幕音频 (视频合成_剪映小助手 内插件)
作用: 添加字幕音频
19添加分镜图片 (视频合成_剪映小助手 内插件)
作用:分镜图片
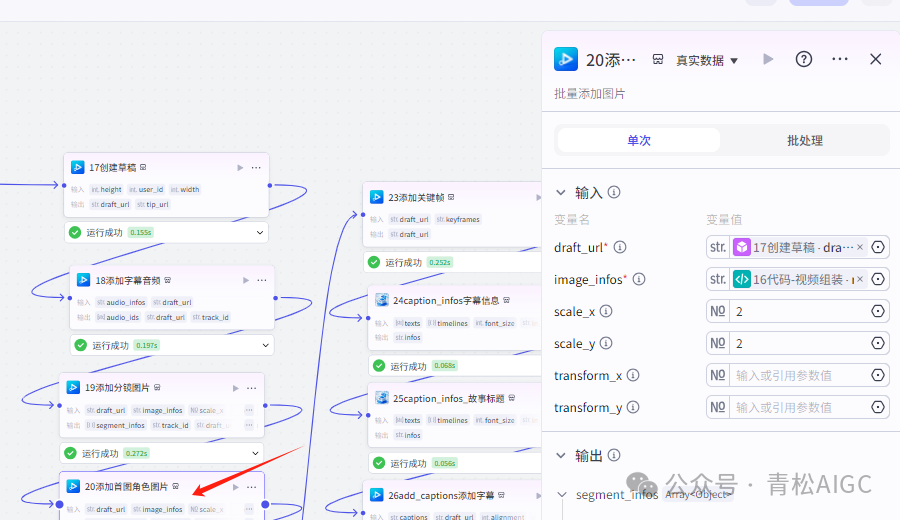
20添加首图角色图片 (视频合成_剪映小助手 内插件)
作用:添加主角图片
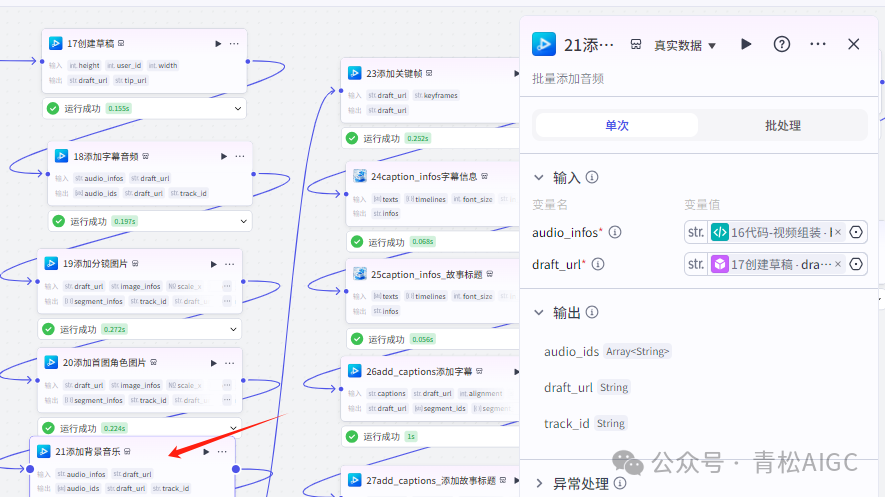
21添加背景音乐 (视频合成_剪映小助手 内插件)
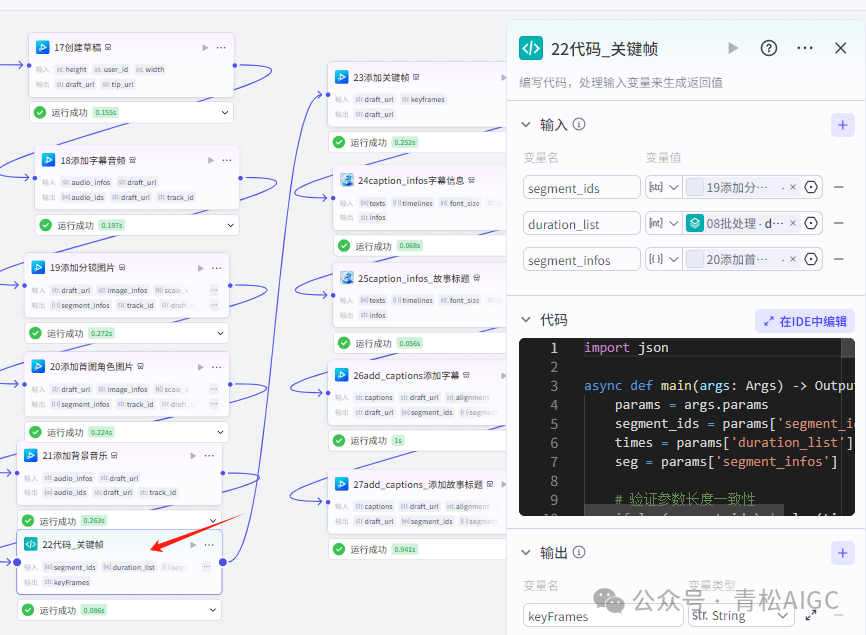
22代码_关键帧
作用:关键帧数据格式整理
输入:
segment_ids :19分镜图片返回的segment_ids
duration_list :08批处理生成的时间线
segment_infos:20添加首图的segment_infos
代码:python 语言
import jsonasyncdefmain(args: Args) -> Output:params= args.paramssegment_ids =params['segment_ids']times =params['duration_list']seg =params['segment_infos']iflen(segment_ids) != len(times):raiseValueError("segment_ids与times数组长度不一致")keyframes = []foridx,seg_idinenumerate(segment_ids):ifidx ==0:continueaudio_duration =int(float(times[idx]))cycle_idx = idx -1ifcycle_idx %2==0:start_scale =1.0end_scale =1.5else:start_scale =1.5end_scale =1.0keyframes.append({"offset":0,"property":"UNIFORM_SCALE","segment_id": seg_id,"value": start_scale,"easing":"linear"})keyframes.append({"offset": audio_duration,"property":"UNIFORM_SCALE","segment_id": seg_id,"value": end_scale,"easing":"linear"})keyframes.append({"offset":0,"property":"UNIFORM_SCALE","segment_id": seg[0]['id'],"value":2,"easing":"linear"})keyframes.append({"offset":533333,"property":"UNIFORM_SCALE","segment_id": seg[0]['id'],"value":1.2,"easing":"linear"})keyframes.append({"offset": seg[0]['end']-seg[0]['start'],"property":"UNIFORM_SCALE","segment_id": seg[0]['id'],"value":1.0,"easing":"linear"})return{"keyFrames": json.dumps(keyframes)}
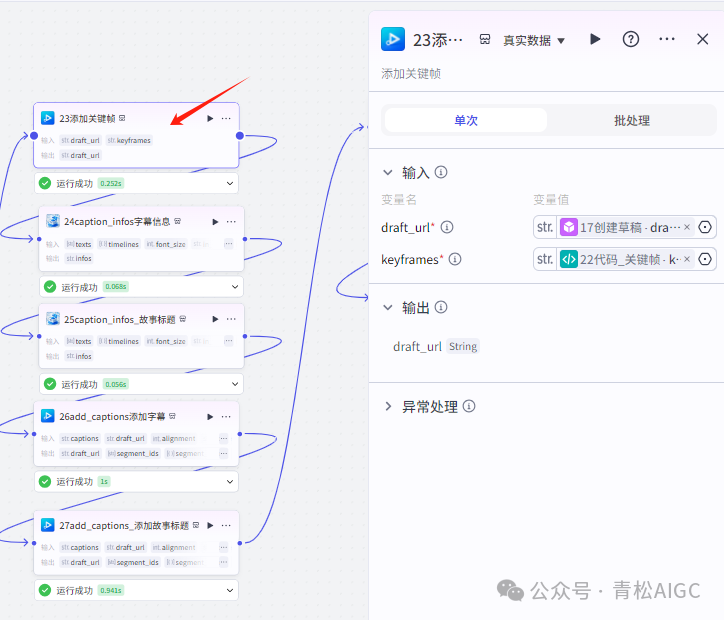
23添加关键帧 (视频合成_剪映小助手 内插件)
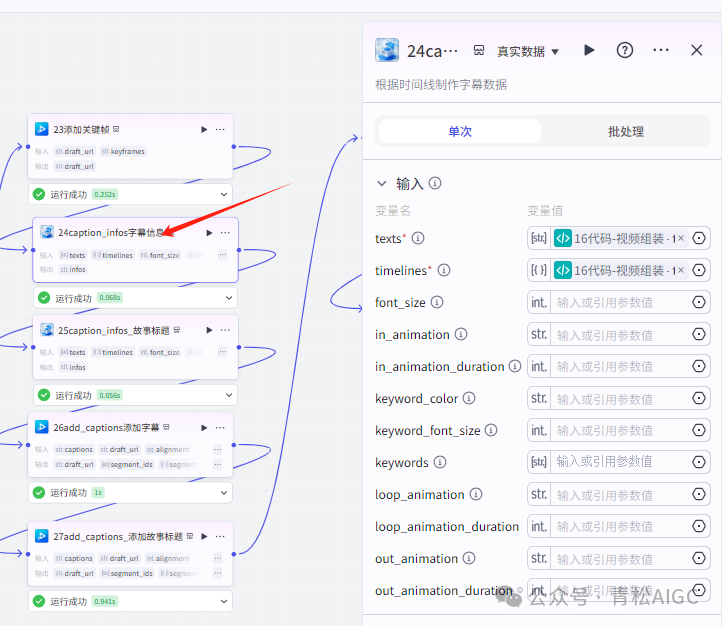
24caption_infos字幕信息(剪映小助手数据生成器)
作用:字幕信息整理,供26节点生成字幕
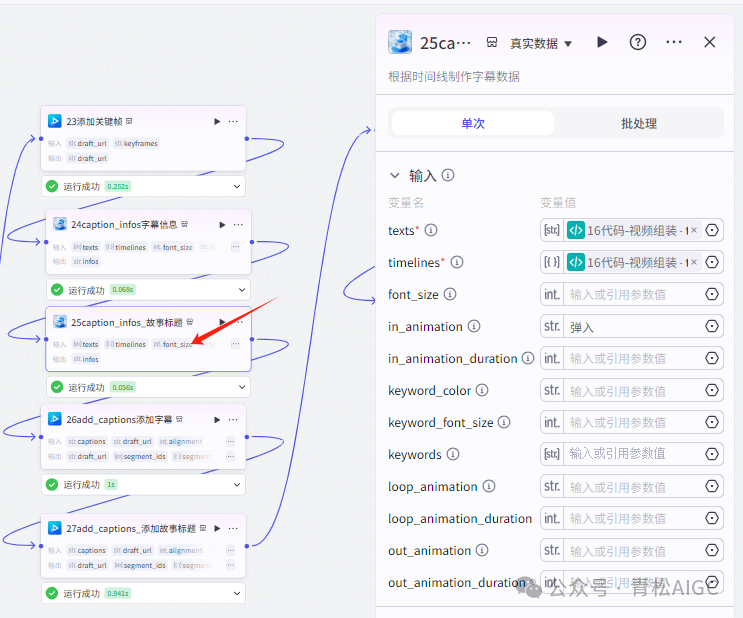
25caption_infos_故事标题(剪映小助手数据生成器)
作用:故事标题整理,供27节点生成标题
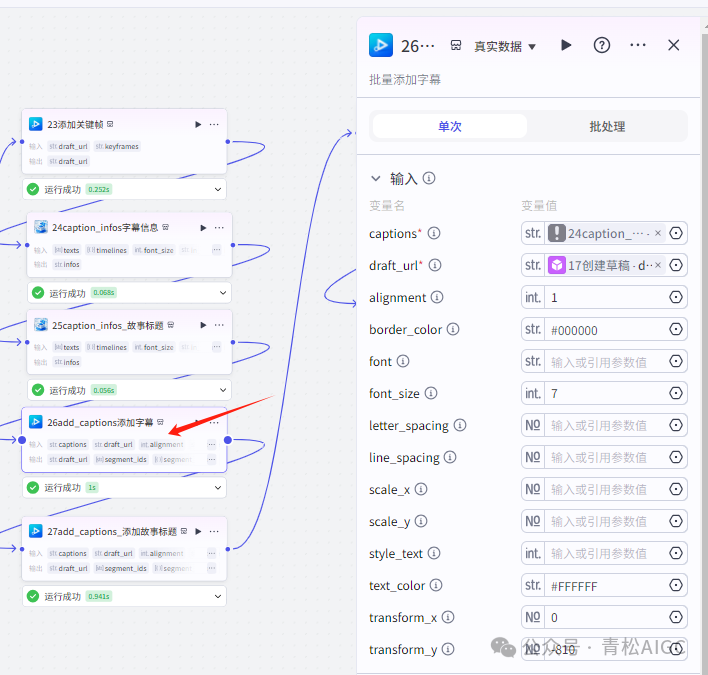
26add_captions添加字幕(视频合成_剪映小助手 内插件)
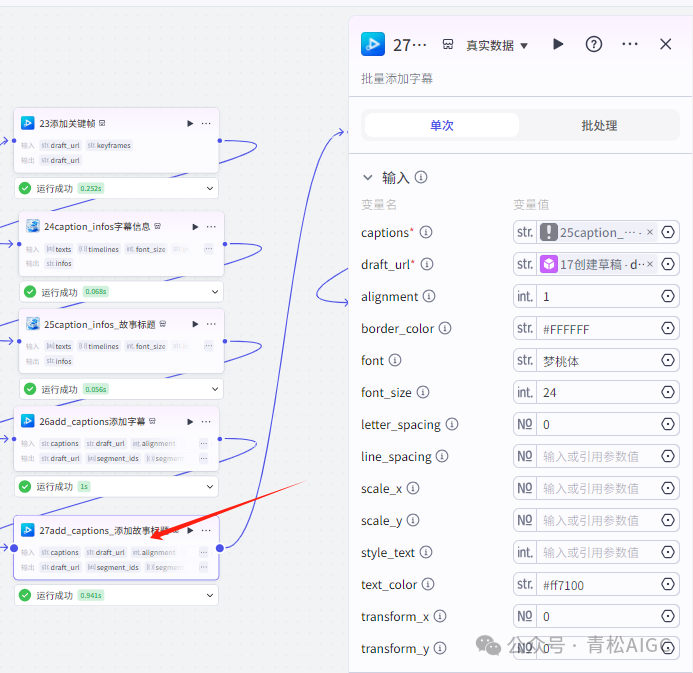
27add_captions_添加故事标题(视频合成_剪映小助手 内插件)
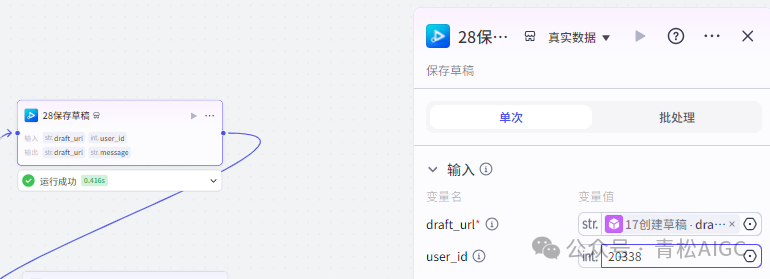
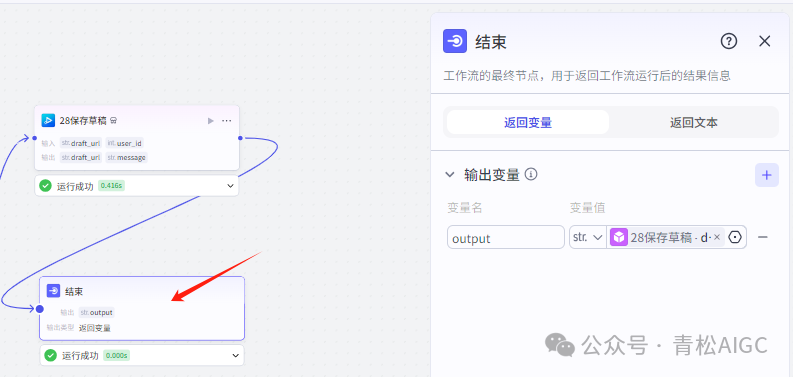
28保存草稿(视频合成_剪映小助手 内插件)
结束节点 作用:返回剪映草稿链接
以上就是工作流的所有节点详细介绍
工作流智能体已经发布到扣子商店,可以前往体验:
体验地址:(电脑打开、主页查看智能体)
扣子-AI智能体开发平台:
https://www.coze.cn/user/2250076738290489?access_entrance=my_profile需要复制工作流的小伙伴联系青松即可~
觉得内容不错的小伙伴,请记得点赞+转发+关注。若有疑问或建议,欢迎评论区交流
© 版权声明
文章版权归作者所有,未经允许请勿转载。