
大家做模型都在比谁更大。参数更大,上下文窗口更大,反正什么都往天花板往上顶,问题是,Agent如果真的要进入现实世界,它还得变成一种更像水电煤的东西。便宜,稳定,到处能跑。说实话,要是没有Coding Plan和五小时额度刷新,10块百万token我都嫌贵。毕竟,如果像Hermes或者OpenClaw这种重型开发任务只能跑一两个对话,如果是多个Skill混合使用的话,也只能跑20-50个回合。所以我看到面壁这次发MiniCPM-V4.6的时候,第一反应其实是又捞着了。1.3B,能看图,还能跑得很快,
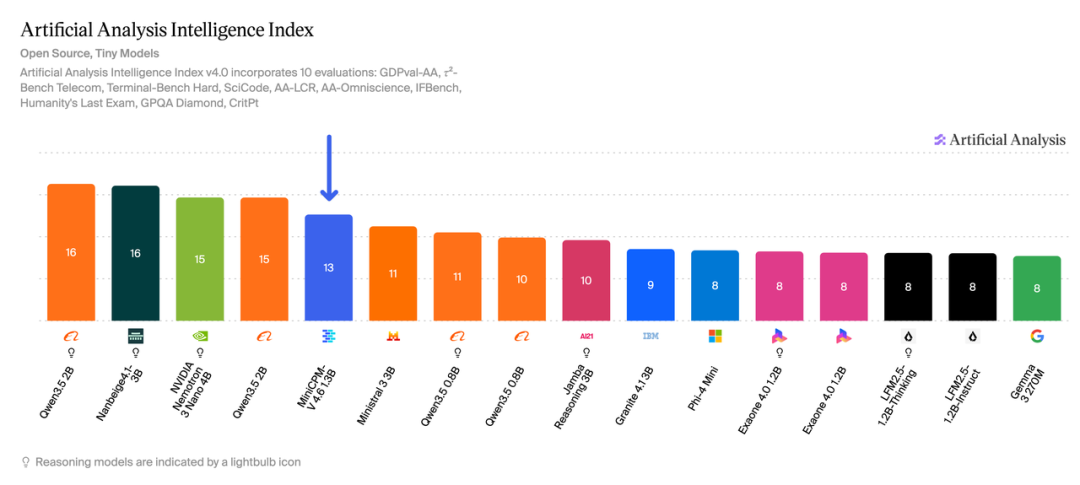
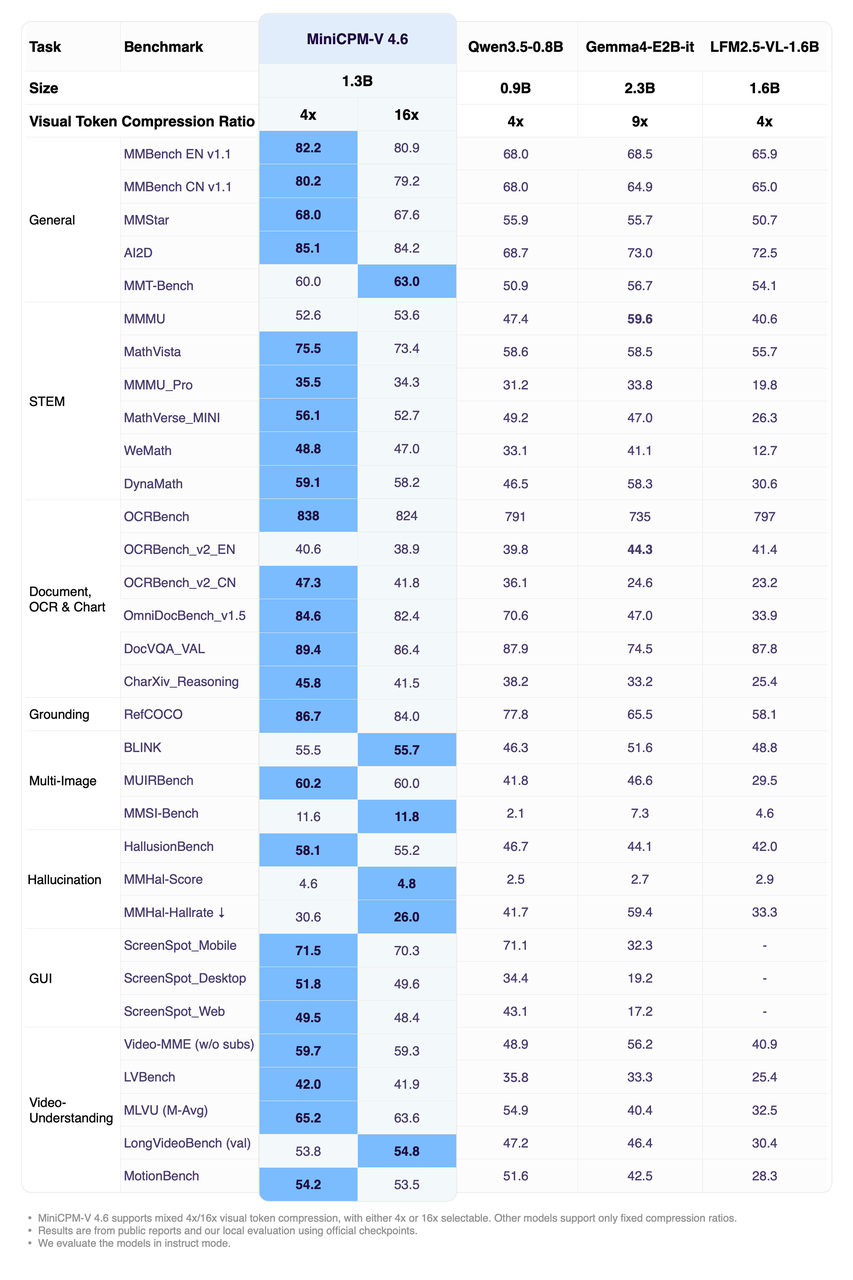
🔗huggingface.co/openbmb/MiniCPM-V-4.6隔壁随便找一个都是500B往上甚至1T的。面壁的MiniCPM-V一直是一个很有代表性的端侧模型系列。从2024年4月发布以来,它打的不是巨无霸路线,是小尺寸,高效率,端侧可用。这次V4.6小到什么程度呢,你可以把它理解成一个能理解图文,还能被消费级显卡随便拿去再训练成适用于各种垂直限时任务的脚手架模型。在公开评测里,MiniCPM-V 4.6的多模态综合能力超过了Qwen3.5-0.8B和Gemma4-E2B-it。
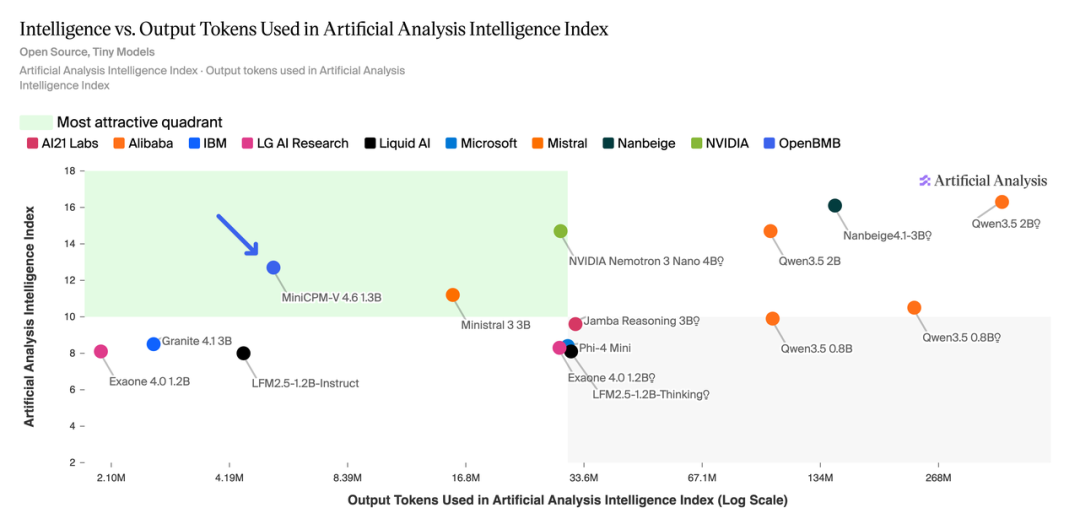
在AA评测里的token消耗非常低,1.3B非推理版本运行只消耗5.4Mtoken,只有Qwen3.5-0.8B非推理版101M的1/19,也只有Qwen3.5-0.8B推理版本233M的1/43。
如果只是跑一次demo,模型慢点贵点都还能忍。但真实业务里延迟就是体验,吞吐就是成本,显存就是预算,功耗就是影响落地。手机不会因为模型很聪明就多出一块GPU。一个线上系统也不会因为你榜单分数好看,就允许每个请求都烧掉一大把算力。所以MiniCPM-V 4.6要讲的是端侧模型也能做多模态。大模型多模态能力终于开始变得更像一个可以四通八达到处有用的热插拔基础组件了。说到这里,干脆来看看它背后的技术创新吧。

多模态模型看图,最麻烦的一步是它要先把图片拆成一堆视觉token。图片越大,越清楚,里面的信息越多,视觉token就越多。视觉token一多,后面的成本就上去了。你可以把它想成搬家。如果一开始把所有东西都原封不动搬上车,后面再说我要节省空间就没啥空隙了,很多多模态模型的做法,就是在ViT(Vision Transformer 视觉模型)之后再压缩token。这样确实可以减轻后面语言模型的负担,但前面的视觉编码器已经吃过一遍大图的计算开销了。MiniCPM-V 4.6的LLaVA-UHD v4优化的点是把视觉token压缩提前到ViT内部。更早压,更省空间。
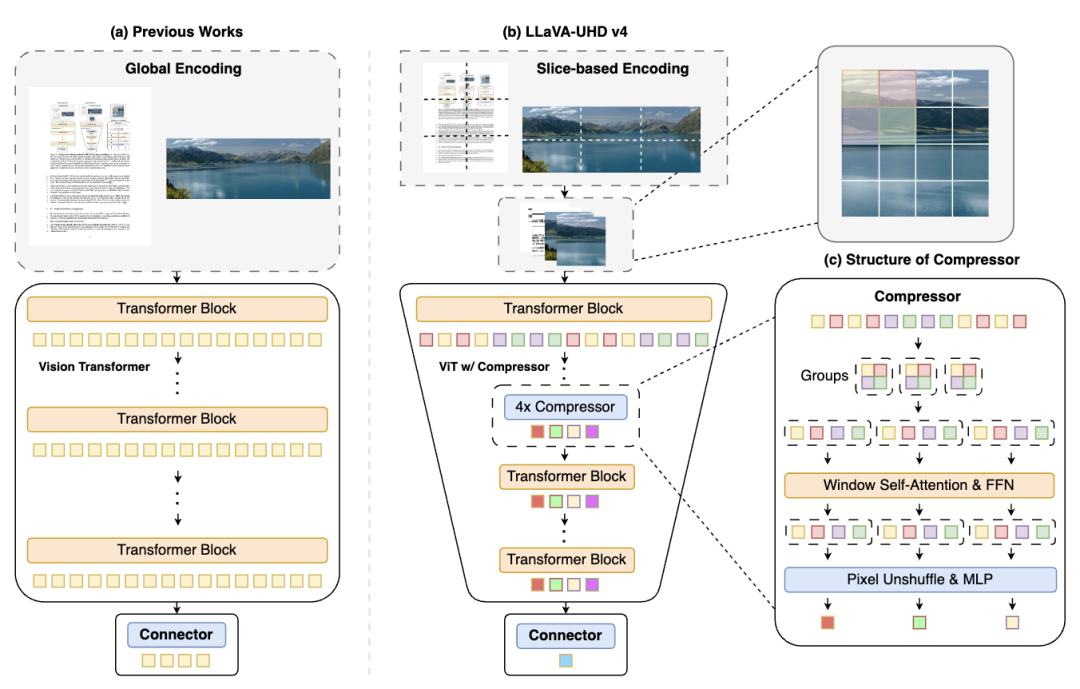
让后面大部分ViT层一开始就少处理很多token。视觉编码阶段的FLOPs(浮点运算次数)降低55.8%。做起来没那么容易。因为不能粗暴地把视觉token砍掉,砍猛了,图像表征就坏了,模型可能省了算力,但也看不清了。LLaVA-UHD v4里面用了早期ViT内压缩模块,配合窗口注意力,让邻近token先做上下文交互,再通过复用相邻预训练ViT层参数,尽量减少对原有视觉表征的扰动。翻译成人话就是,它没有一口气把所有部分都压缩。

它在尽量不伤筋动骨的情况下,把最费算力的部分提前瘦掉。这就是MiniCPM-V 4.6能又小又快的关键之一。顺着这个再聊,就到了另一个很重要的点,4倍和16倍混合视觉token压缩。我觉得这个点挺适合拿普通相机来理解。4倍压缩更像高清模式,保留更多细节,适合追求识别精度的时候用。16倍压缩更像高速省电模式,画面信息压得更狠,但推理速度会更快,成本也更低。过去很多模型的技术路线是二选一,要么偏精度,要么偏速度。到了MiniCPM-V 4.6,它开始把两种压缩率混在一起用,能切换两类完全不同的场景。
MiniCPM-V 4.6已经可以在手机上用了一类是端侧,手机,电脑,车机,智能家具,这些设备对算力功耗很敏感,我不指望它们像云端机房一样随便烧。另一类是云端高并发。很多业务不是一个人问模型一次,而是几万个请求同时涌进来。每个请求还要求对很多候选结果做理解,打分,召回,排序。
MiniCPM-V 4.6要解决的是两个问题。普通设备上怎么运行AI,以及高并发怎么省钱。隔壁快手OneRec推荐大模型在处理视频输入里的字幕,标签,ASR(语音识别),OCR(字符识别),封面图这些多模态表征时,就用到了MiniCPM-V-8B,OneRec承接了短视频推荐主场景25%的请求。
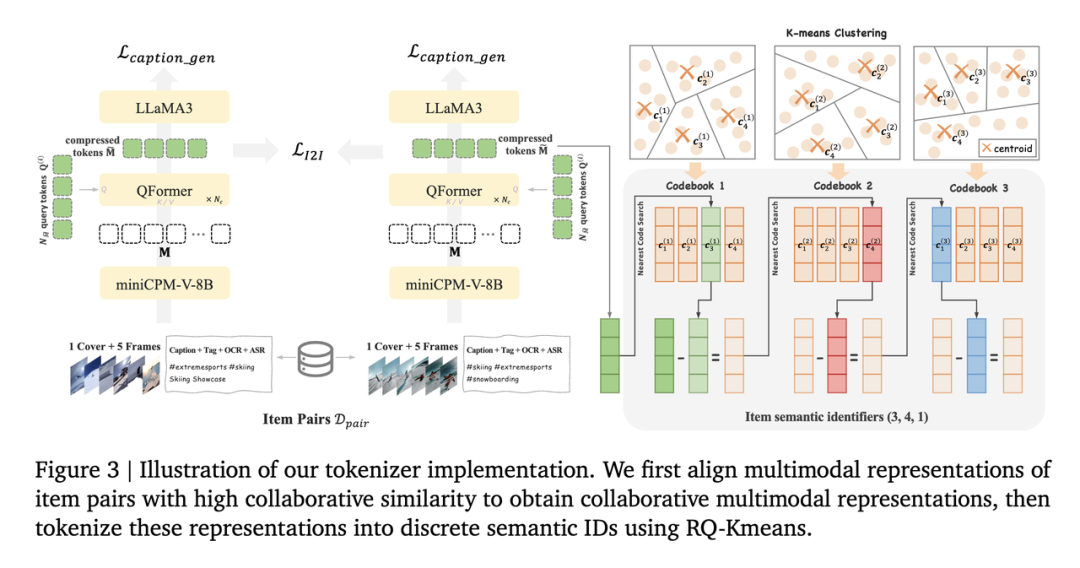
在这种地方,模型不能像GPT5.5一样想个5分钟,然后憋一句稳稳接住你。它只需要提供一点点更好的信号。比如这个封面图到底是什么内容。这段视频更像美食教程还是探店吐槽。这个字幕里有没有关键品牌名。这个用户当下更可能想看什么。单看每一次判断,好像都不复杂。但它会被放大到几千万,几亿次请求里。这种模型要的不是单次表演有多好。它要的是够快,够轻,够稳,够便宜。能让整体系统效果往上抬一点点,这也是我这三年越来越强烈的一个感受。很多人聊AI,还是喜欢盯着最强模型。谁超过了GPT,谁又近了Claude,这些当然重要。但真正能让AI渗入现实世界的,是一堆稳定不需要烦恼token数的端侧模型。它们不一定会都被用户看见。它们会让一个系统变得更聪明一点,更快一点,更省钱一点。这次面壁还做整套从微调到部署的工具链。微调端支持ms-swift和LLaMA-Factory,部署端适配vLLM、SGLang、llama.cpp、Ollama。甚至消费级显卡,RTX4090,也可以跑通微调流程。小尺寸模型的生命力,本来就在于被改造。我们不需要把MiniCPM-V 4.6当成一个万能助手。它更适合去做一个垂直文档解析模型,一个OCR整理模型,一个本地相册理解模型,一个摄像头画面异常识别模块。它在这些场景里只要把一件事做得够稳快便宜就好了。从这个角度看,MiniCPM-V 4.6好就好在,它把多模态往基础设施的方向,又推进了一小步。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


