
玩家控制一个角色在 3D 地图里移动。玩家可以输入自然语言,系统调用 GLM-5.1 高速版,将用户输入转换成结构化 JSON 场景指令,然后前端实时执行这些指令,让 3D 场景立即发生变化。这个是我给的提示词: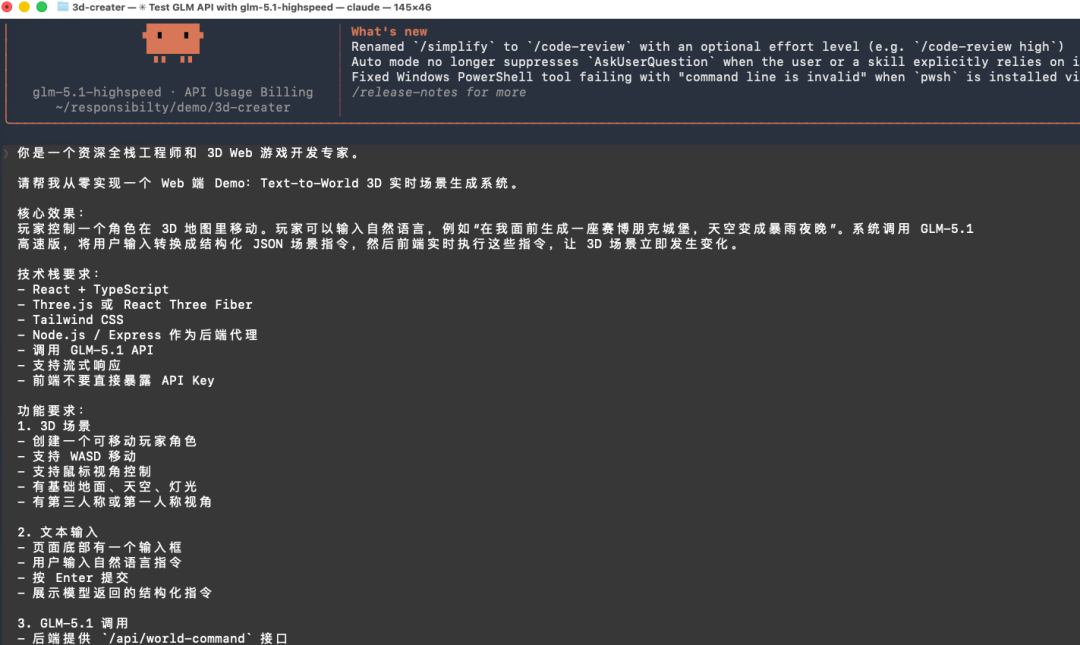
你是资深全栈工程师与3D Web 游戏开发专家,请从零实现一个「Text-to-World」Web Demo:玩家在 Three.js/R3F 的3D 世界中移动,并通过自然语言实时改变场景。用户输入“在前方生成赛博朋克城堡并切换暴雨夜晚”等文本后,后端调用 GLM-5.1高速版,
将文本转换为结构化 JSON commands(spawn_object、set_environment、add_effect 等),前端 SceneCommandExecutor 实时解析并执行,让世界瞬时变化。技术栈要求 React + TypeScript + React Three Fiber + Tailwind + Node.js/Express,
支持 WASD、鼠标视角、流式响应、环境天气、粒子特效、NPC、传送门等能力,且 API Key 不暴露在前端。
请输出完整项目架构、前后端目录结构、JSON Schema、核心执行器设计、完整可运行代码、README、
环境变量配置与启动命令,代码需模块化、类型清晰、具备错误处理与高实时交互体验。
 估算 TPS 为 55.0,总耗时 2.3 分钟。
估算 TPS 为 55.0,总耗时 2.3 分钟。
TPS 指的是模型每秒能生成多少 token,总耗时是指从发送到完整结束花了多久。
这里除去了模型内部推理、代理步骤做的估算 TPS,实际耗时为最终文本到达 WeSight 的时间。 相同的任务,我把 Claude Code 里面的模型替换为 GLM 5.1 高速版,TPS 直接就干到了 350,虽然离官方说的 400 还有一点点差距,但实际体感,无法表达,你还没反应过来就干完了。
相同的任务,我把 Claude Code 里面的模型替换为 GLM 5.1 高速版,TPS 直接就干到了 350,虽然离官方说的 400 还有一点点差距,但实际体感,无法表达,你还没反应过来就干完了。 实际耗时变为了 2.6 秒,这个体感还是非常明显的。在 WeSight 中你也能很直观的看到这个数据变化。
实际耗时变为了 2.6 秒,这个体感还是非常明显的。在 WeSight 中你也能很直观的看到这个数据变化。 相同的任务,这是 Codex 的数据,用的 GPT 5.5 high,TPS 是 153.1,这也符合基准网站 Artificial Analysis 给出的 OpenAI 高速模型 TPS 数据在 120~170 t/s。
相同的任务,这是 Codex 的数据,用的 GPT 5.5 high,TPS 是 153.1,这也符合基准网站 Artificial Analysis 给出的 OpenAI 高速模型 TPS 数据在 120~170 t/s。
侧面反应 WeSight 在预估 TPS 上还是做了很多功课的。
不瞒你说,WeSight 的这个监控能力也是通过 GLM 5.1 高速版开发的,前前后后几个小时就搞定了。现在 WeSight 支持任务状态监控了。这个是我在 WeSight 中用 Claude Code 配合 GLM 5.1 高速版 1.4 分钟就完成的宠物电商网站,功能完全可用。
这个视频是原速录制下来的,你看下这个喷代码的速度,有点可怕的,太快了吧。数据详情: TPS 在 300 左右,总计耗时 1.4 分钟。什么概念,我打个水都没打完,就给我开发完了。我同样的任务,用 DeepSeek V 4 Pro 试了一遍,就花了差不多 4.1 分钟,是 GLM 5.1 高速版耗时的十倍左右。
TPS 在 300 左右,总计耗时 1.4 分钟。什么概念,我打个水都没打完,就给我开发完了。我同样的任务,用 DeepSeek V 4 Pro 试了一遍,就花了差不多 4.1 分钟,是 GLM 5.1 高速版耗时的十倍左右。 当你把 GLM 5.1 高速版接入 Claude Code 或者 Hermes Agent、OpenClaw,这才是你起飞的开始。比如,你看我用飞书直接指挥搭载 GLM 5.1 高速版 Claude Code 和搭载 GPT 5.5 的 OpenClaw 同时做个爱心表白网页。
当你把 GLM 5.1 高速版接入 Claude Code 或者 Hermes Agent、OpenClaw,这才是你起飞的开始。比如,你看我用飞书直接指挥搭载 GLM 5.1 高速版 Claude Code 和搭载 GPT 5.5 的 OpenClaw 同时做个爱心表白网页。 你可以看到 GLM 5.1 高速版几乎是秒出结果:
你可以看到 GLM 5.1 高速版几乎是秒出结果: 而 GPT 5.5 花费了 47.2 s,对比下来速度差了不是一点半点。
而 GPT 5.5 花费了 47.2 s,对比下来速度差了不是一点半点。 而实际出来的效果是差不多的。
而实际出来的效果是差不多的。 为什么快这么多?简单说下技术层面。GLM-5.1 高速版背后是智谱自研的 TileRT 推理引擎,核心思路是把传统推理框架里那些零碎的算子调度、内存读写、同步等待全部干掉,编译期就把整个计算图编排成一个常驻 GPU 的 Engine Kernel。通俗讲就是:传统方案每算一步都要「汇报一次」,TileRT 直接把整条流水线焊死在 GPU 上,中间不回头,一路算到底。所以 400 tokens/s 不是峰值跑分,是稳定可用的生产级速度。写在最后说真的,这次体验完 GLM-5.1 高速版,我最大的感受是:速度本身就是一种能力。以前我们评价模型,看的是跑分、看的是效果。但当你真正把模型接进工作流,每天跟它协作几十上百次的时候,你会发现速度才是决定体验的那个变量。3 秒出结果和 30 秒出结果,不只是时间差了 10 倍,是你的心流状态完全不一样。快到一定程度,AI 真正变成了你的实时搭档,想到哪它就跟到哪。看了下目前 GLM-5.1-HighSpeed 模型仅面向部分企业客户定向开放。我是苍何,AI 时代的速度战争才刚刚开始,咱们下期见。
为什么快这么多?简单说下技术层面。GLM-5.1 高速版背后是智谱自研的 TileRT 推理引擎,核心思路是把传统推理框架里那些零碎的算子调度、内存读写、同步等待全部干掉,编译期就把整个计算图编排成一个常驻 GPU 的 Engine Kernel。通俗讲就是:传统方案每算一步都要「汇报一次」,TileRT 直接把整条流水线焊死在 GPU 上,中间不回头,一路算到底。所以 400 tokens/s 不是峰值跑分,是稳定可用的生产级速度。写在最后说真的,这次体验完 GLM-5.1 高速版,我最大的感受是:速度本身就是一种能力。以前我们评价模型,看的是跑分、看的是效果。但当你真正把模型接进工作流,每天跟它协作几十上百次的时候,你会发现速度才是决定体验的那个变量。3 秒出结果和 30 秒出结果,不只是时间差了 10 倍,是你的心流状态完全不一样。快到一定程度,AI 真正变成了你的实时搭档,想到哪它就跟到哪。看了下目前 GLM-5.1-HighSpeed 模型仅面向部分企业客户定向开放。我是苍何,AI 时代的速度战争才刚刚开始,咱们下期见。
© 版权声明
文章版权归作者所有,未经允许请勿转载。