
直接两个Pro账号接Agent上就不考虑额度了,但架不住Agent多啊,到周五周六就周限额了,好吧其实是因为我觉得慢给Codex上了1.5倍速硬生生吃2.5倍积分消耗。所以这段时间在尝试把Hermes里的辅助模型换个更快的。

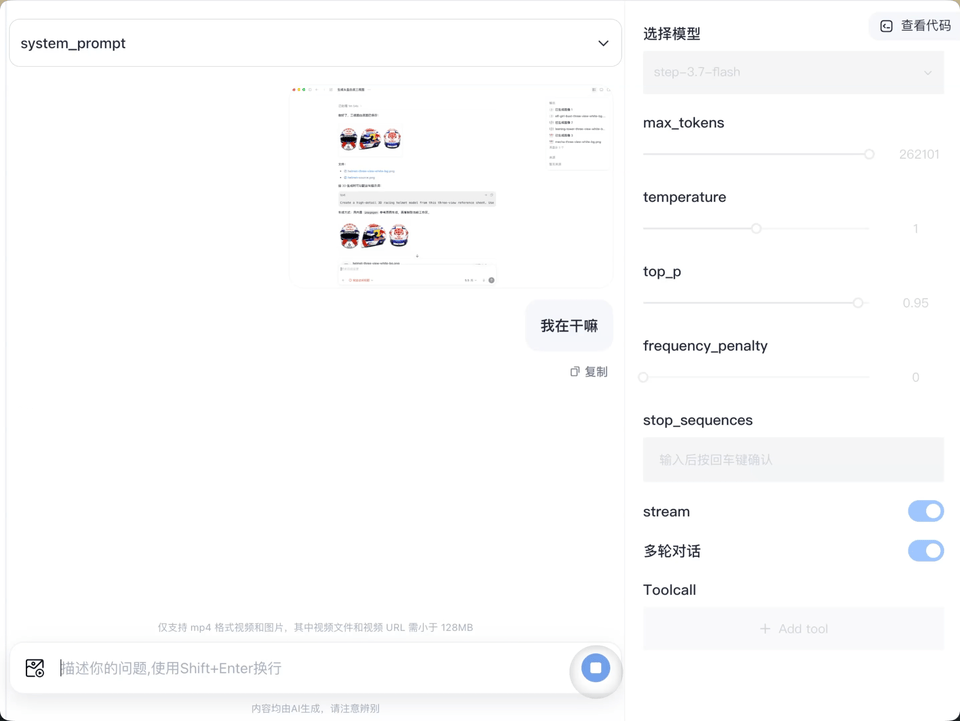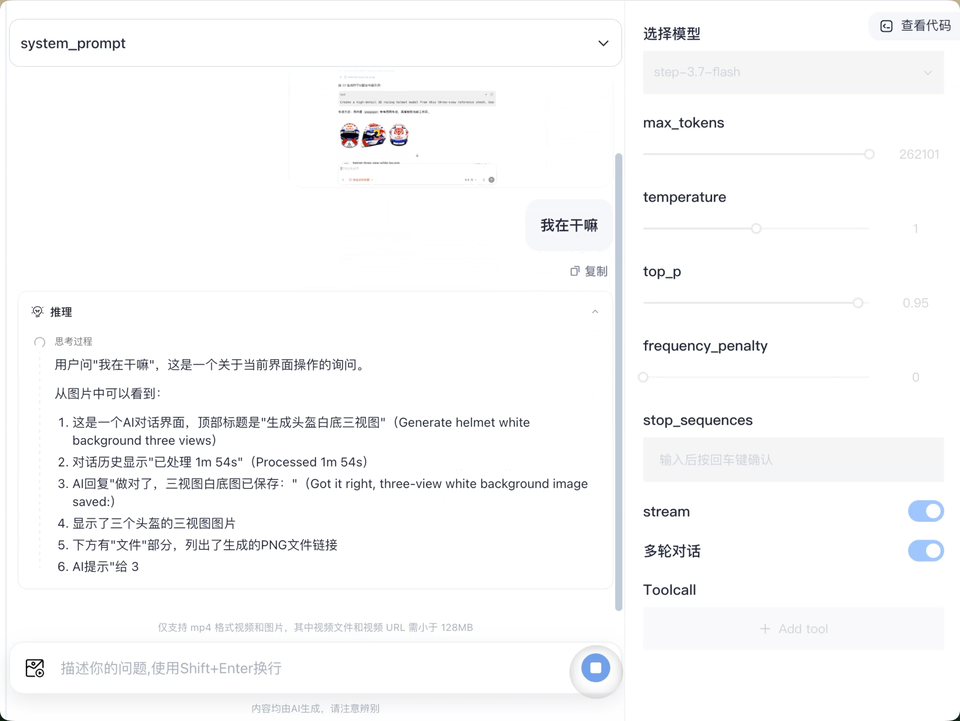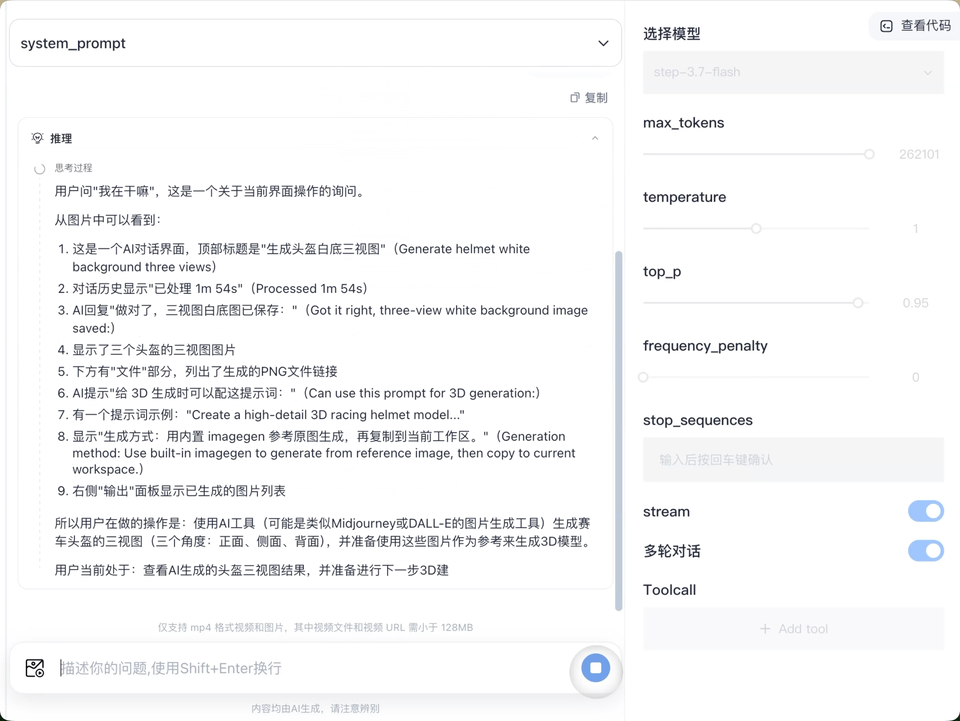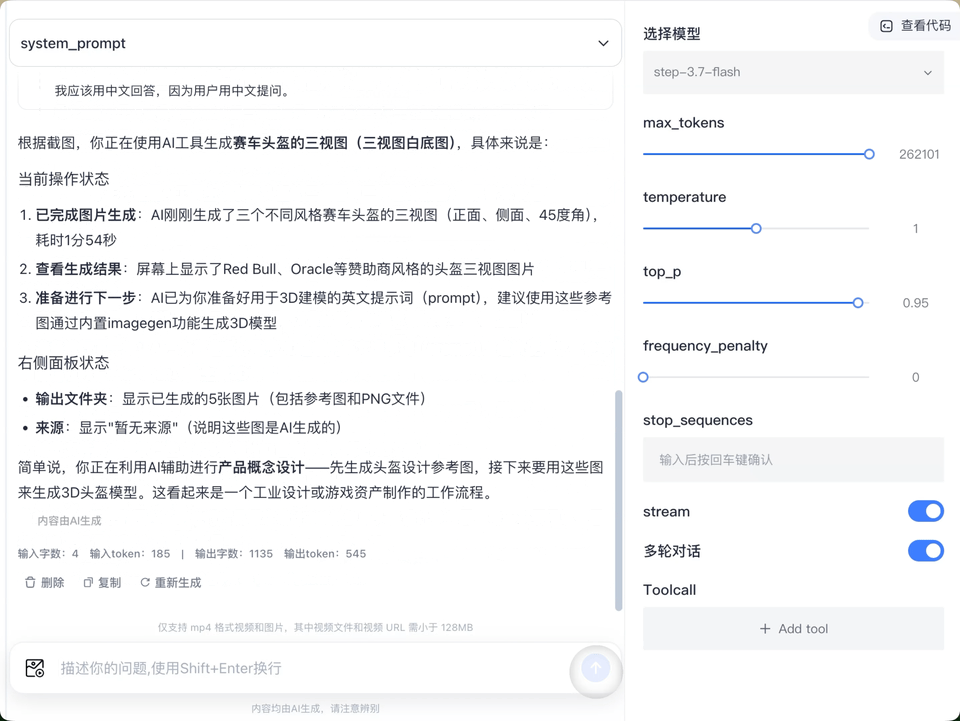
所以当我看到阶跃星辰开源了他们新模型,Step 3.7 Flash,原生多模态,速度来到了400token/s(标准版的GPT5.5 API是42到72token/s),MoE(专家混合模型)架构,总参数196B激活11B,默认上下文是256k,三档推理强度调节,是光看一轮参数就想要上手测试一把的程度。免得说我欺负人家GPT,我还特意做了一个Codex经常用到的案例,就是双command判断目前屏幕发生了什么。
从纸面实力上看,这个快模型没有因为速度牺牲性能。
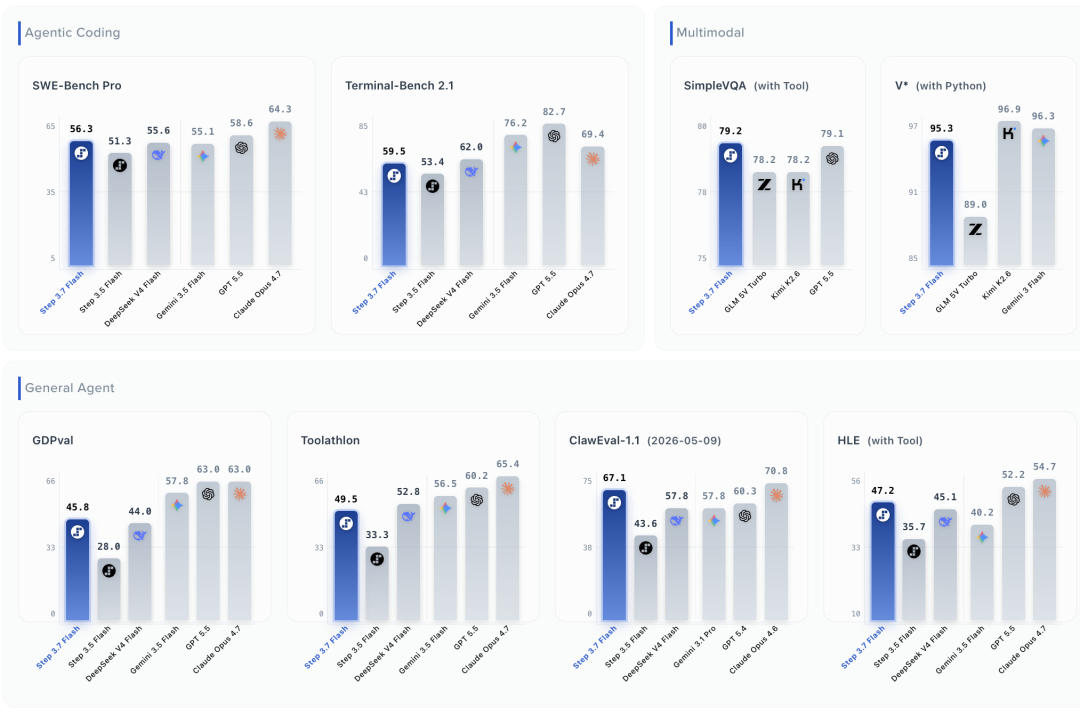
我直接学某包用最直白的方式说明白,比起上一代3.5 flash是有全面提升,在ClawEval-1.1(通用 Agent ),SWE-Bench Pro(真实编程),HLE with Tool(高难知识推理)比DeepSeek V4 Flash和Gemini 3.5 Flash高,可以看到它的定位更多是一个针对Agent类任务调优过的快模型。在终端/命令行任务,复杂编码,工具综合能力也在追GPT-5.5和Claude Opus 4.7了,至于传统的API价差的环节我就直接上图了,
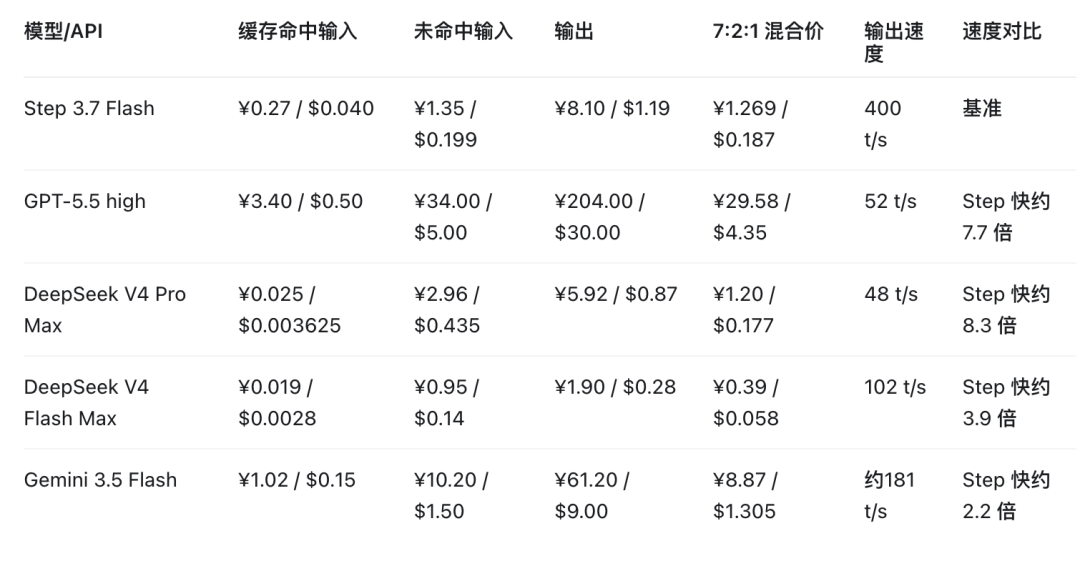
那接下来轮到我跟钱包一拍即合,把三种情况一次性对比明白,

开局先来一个根据截图拆解品牌风格,然后把这个风格应用在另一个领域上的case,

-
直接分析截图的视觉语言。 -
生成原创的AI日报/ AI 选题雷达品牌网页,品牌名自选。 -
产物必须是一个可直接打开的单文件 HTML。 -
写完后简短回复,输出文件路径,从截图借鉴了哪些视觉元素。 -
如果无法写入文件,在回复中输出完整 HTML,并用清晰的
BEGIN_HTML/END_HTML包裹。
GPT5.5,
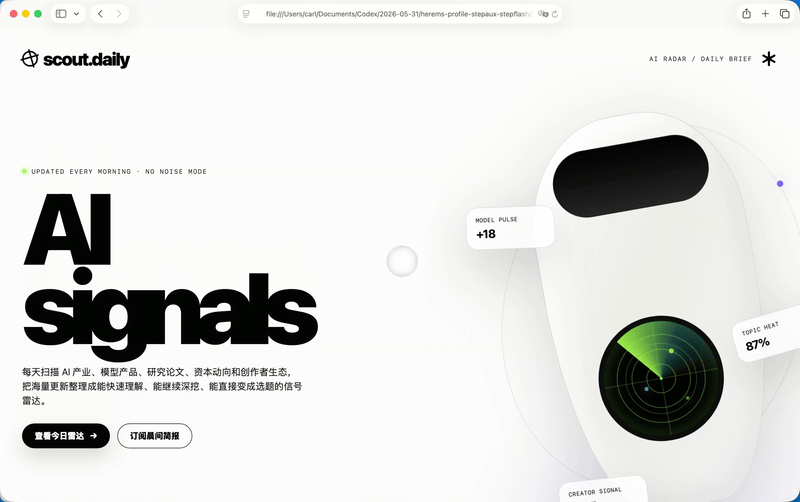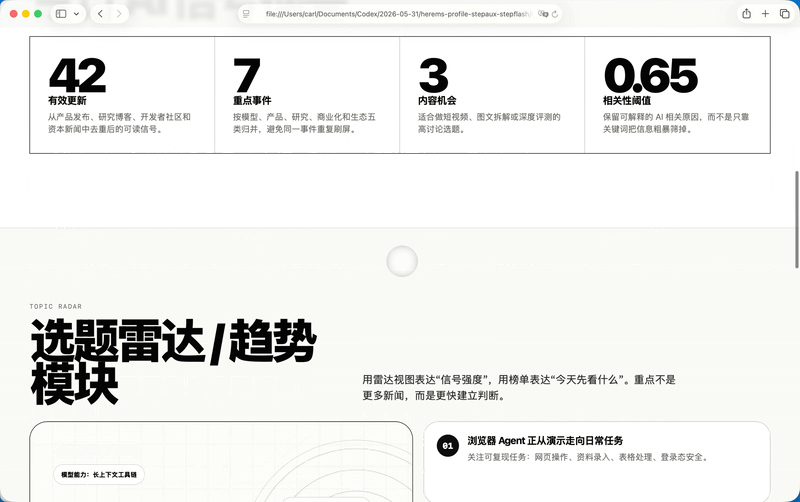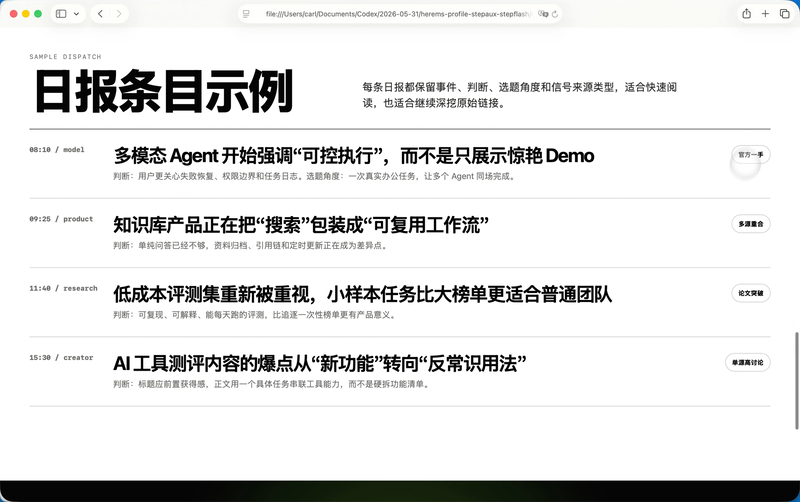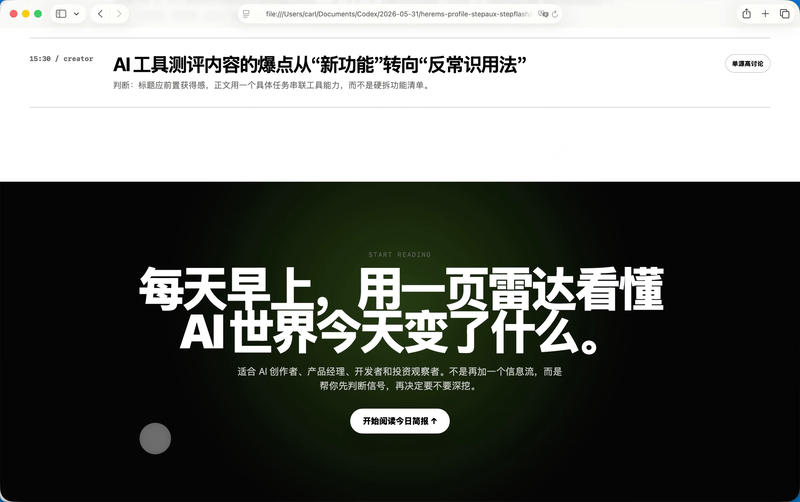
三个版本都抓到了原图里那套极简黑白的气质,大留白、超大字号、黑色胶囊按钮,这些基本都没跑偏。纯GPT-5.5那个版本,我觉得SVG是三个里面最稳的,雷达这个意象也更像一个真正的品牌符号。它的问题也很GPT,慢,而且做前端的时候有时候会把自己的思考过程、解释性内容一起塞进HTML里,后面还要我再清一遍。
GPT 5.5 + step 3.7 flash,

GPT-5.5加Step 3.7 Flash这个版本,中文产品感反而更舒服。标题有主次,Logo更像手机里会出现的入口,还用了日历去表达「今天」这个概念。
Step 3.7 Flash,
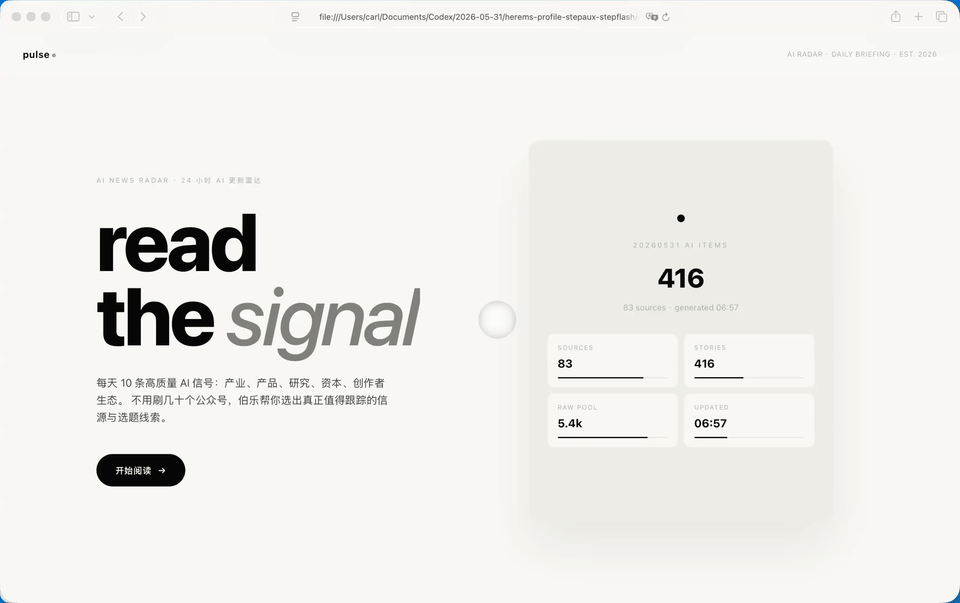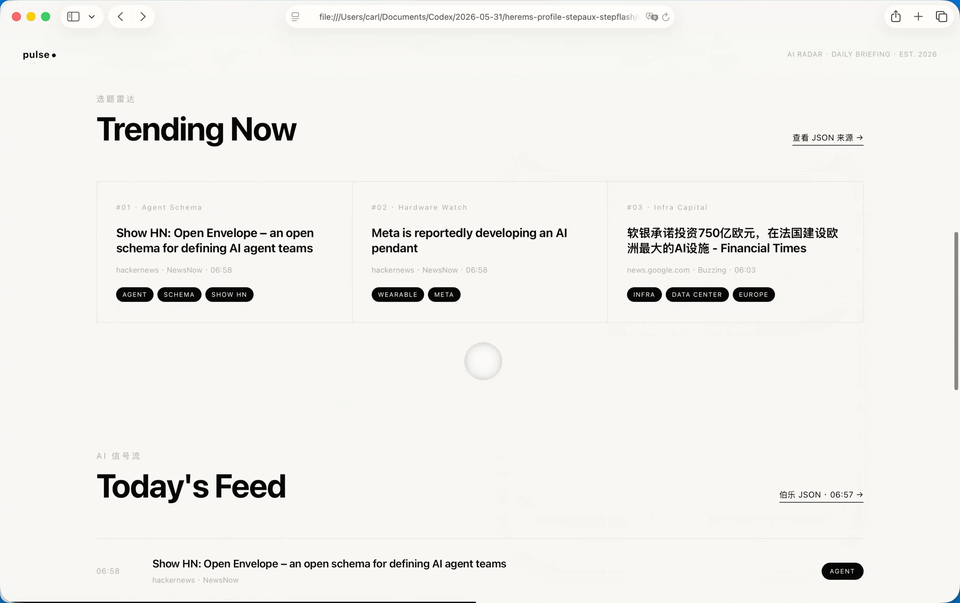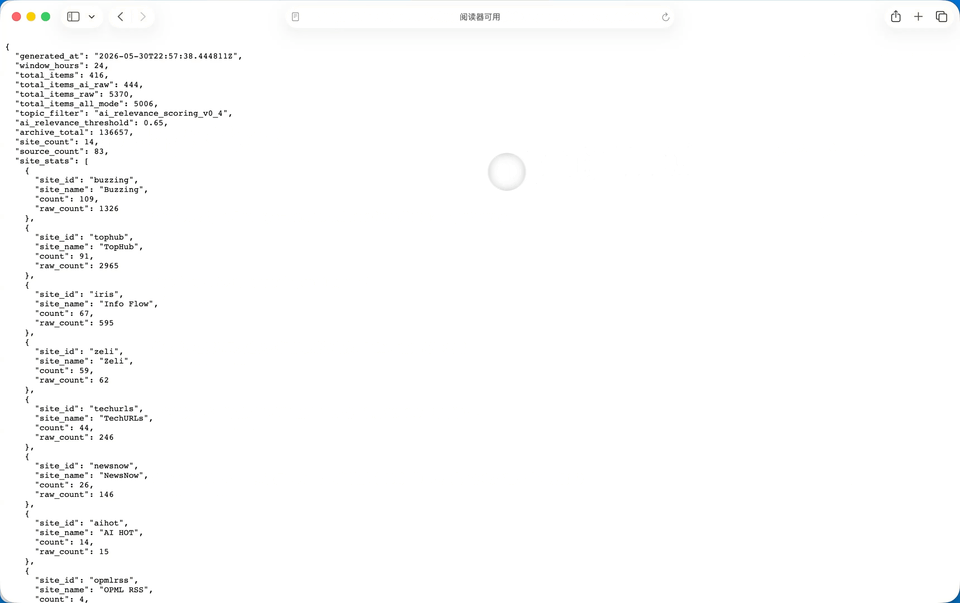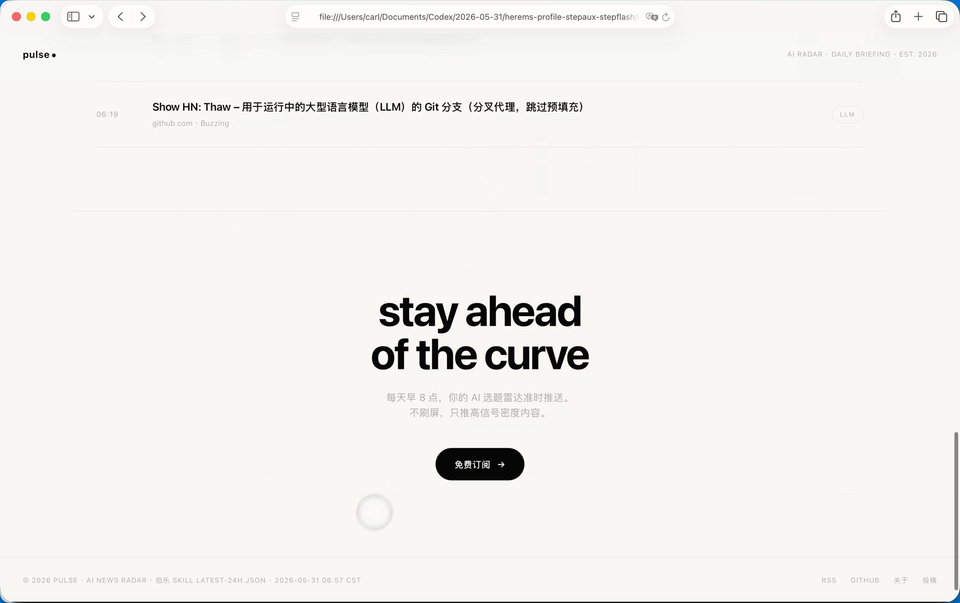
纯Step 3.7 Flash夸张的是速度。GPT-5.5花了4分钟把初版跑出来,它用了36秒就把完整的HTML写完了。
接着我又测了一种现在很常见的主页玩法。很多AI产品会把首屏Hero的提示词直接放出来,背景是生成好的视频或者动画。我们可以先让模型读这个首屏,再顺着同一套风格往下生成子模块。
提示语原文太长,我这里直接翻成人话。这类提示词一般会先把页面的视觉底座钉死,比如字体用什么,背景视频是什么,桌面端和移动端的首屏怎么摆,Hero里有哪些文案和按钮。然后就是技术边界。比如只能用React、ReactDOM、Tailwind CSS、Vite,不允许额外加UI库,也不要临时引入一堆看起来很高级但项目里根本没用到的依赖。一回生二回熟,我们这次照样看看他们的速度,以及在执行的过程中,哪个遵守约束是最稳定的。GPT5.5,
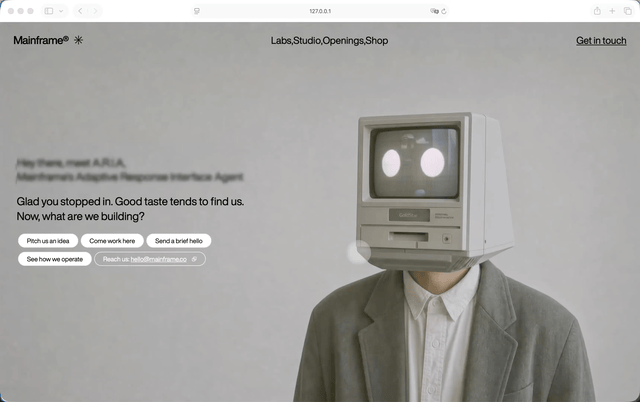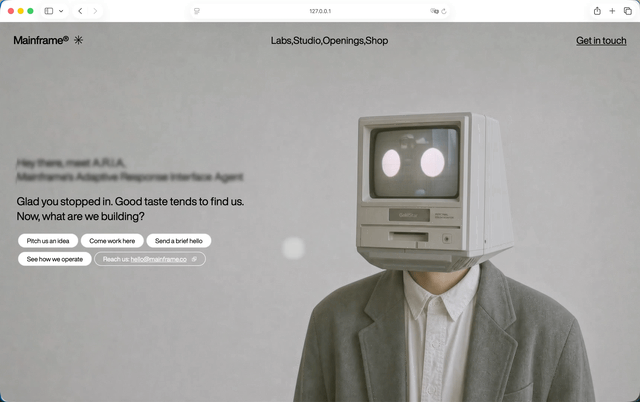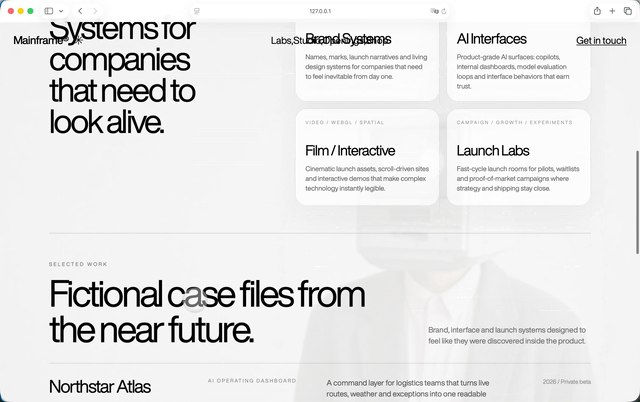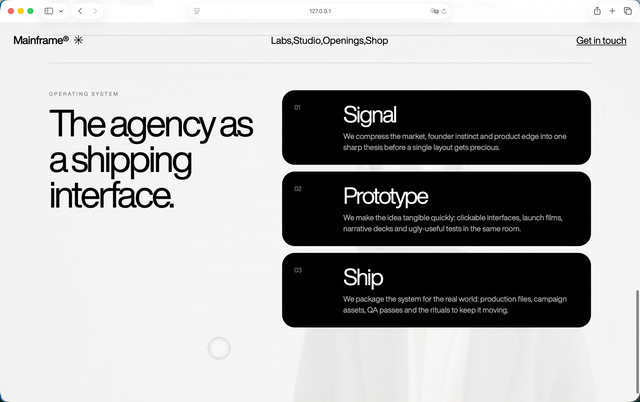
没想到这把纯GPT-5.5有点拉了。第一轮跑下来,背景视频还没有露出来,还是在第二轮的时候修好的,如果说整体的设计有什么我喜欢的点,就是因为它把模块作为背景。所以其实我们在下面滑动这些模块的时候,都能够看到电脑人。
GPT 5.5 + step 3.7 flash,
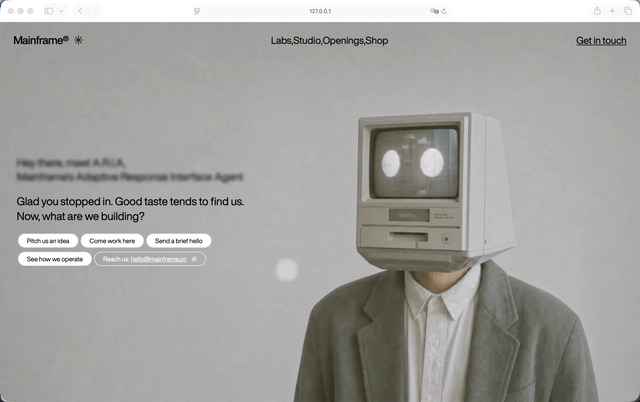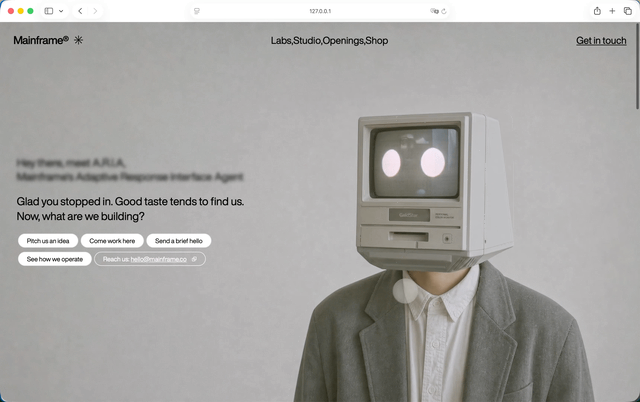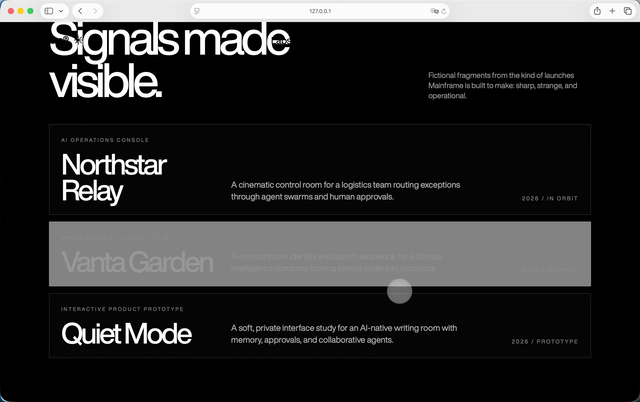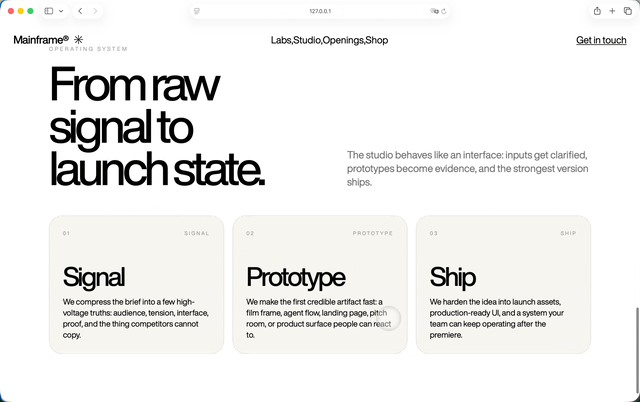
GPT-5.5加Step 3.7 Flash这组,过程中用到了不允许的React插件,但它很快反应过来,自己删掉了。把Hero模块生成之后,我就让他沿用延续同一套风格,把首屏下面的几个模块做出来。做完之后我甚至怀疑自己是不是打开错页面了。因为一直很固执的GPT-5.5,在Step 3.7 Flash参与之后,模块响应和色彩轮换居然有一点Claude那种味道了。
Step 3.7 Flash,
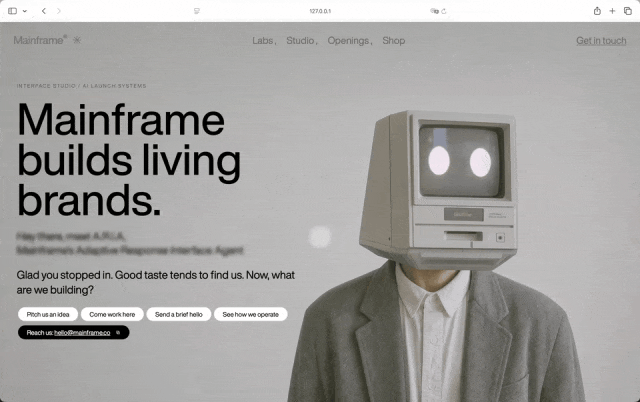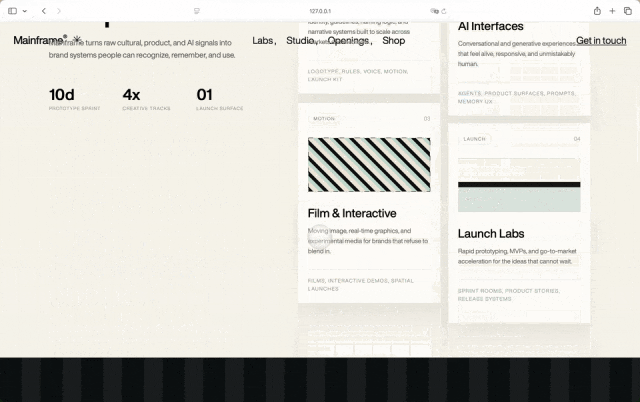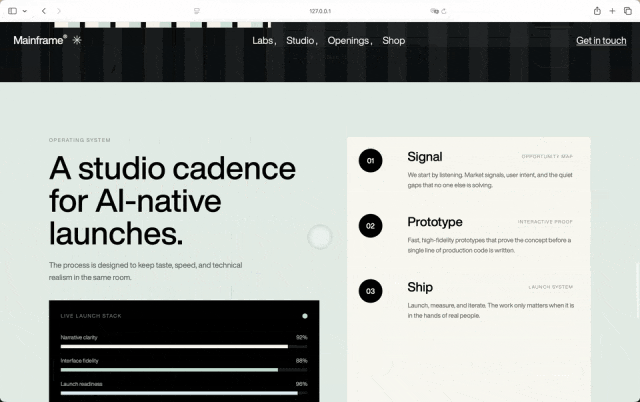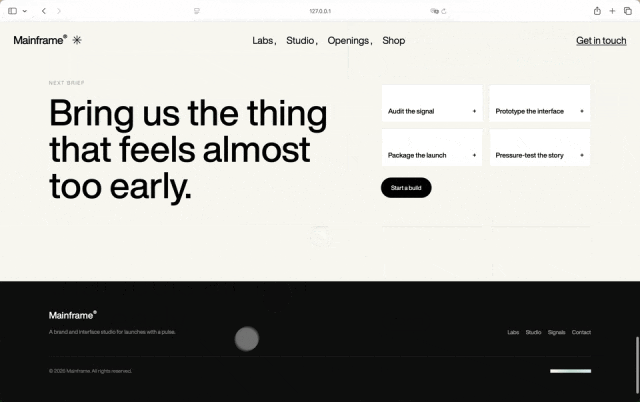
纯Step 3.7 Flash还是最快,152秒左右完成,不过依赖没那么干净,打字机那里出现了Gad…undefined这种文本bug。不过从设计上来说,我还是蛮喜欢它这种条纹类的,给我一种眼前一新的感觉,因为它用到更多丰富的色彩。
第三个Case,我换成PPT。现在我们可以用一个带Deep Research思路的提示语,再接一个HTML PPT Skill,直接生成一份信息密度比较高、还能带演讲模式的说明式PPT。
纯GPT5.5,

从视觉上看,纯GPT-5.5整体风格都有在hold住,但中间有一页突然用了橙色字体一出来。
GPT 5.5 + step 3.7 flash,

GPT-5.5加Step 3.7 Flash这个版本,内容组织更积极,抓到的资料源也更多。但它在章节大标题页上有点掉模板,章节页面会单剩一个文字块。
Step 3.7 Flash,
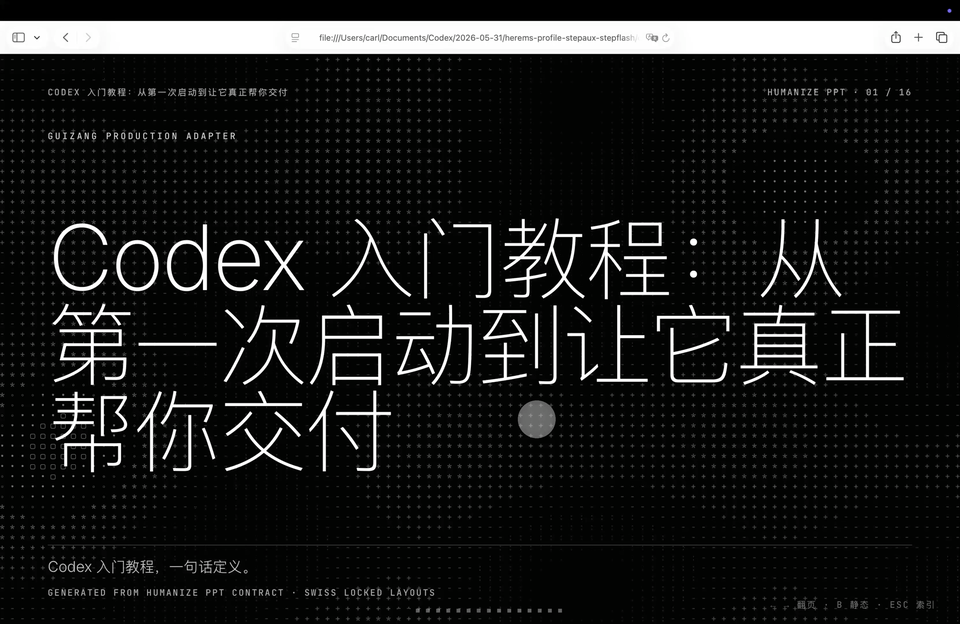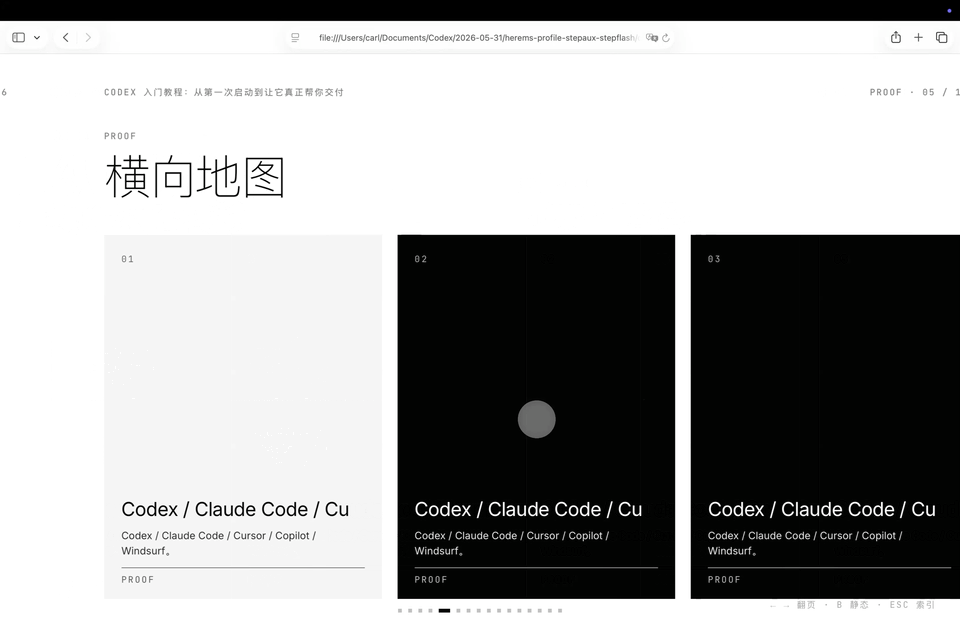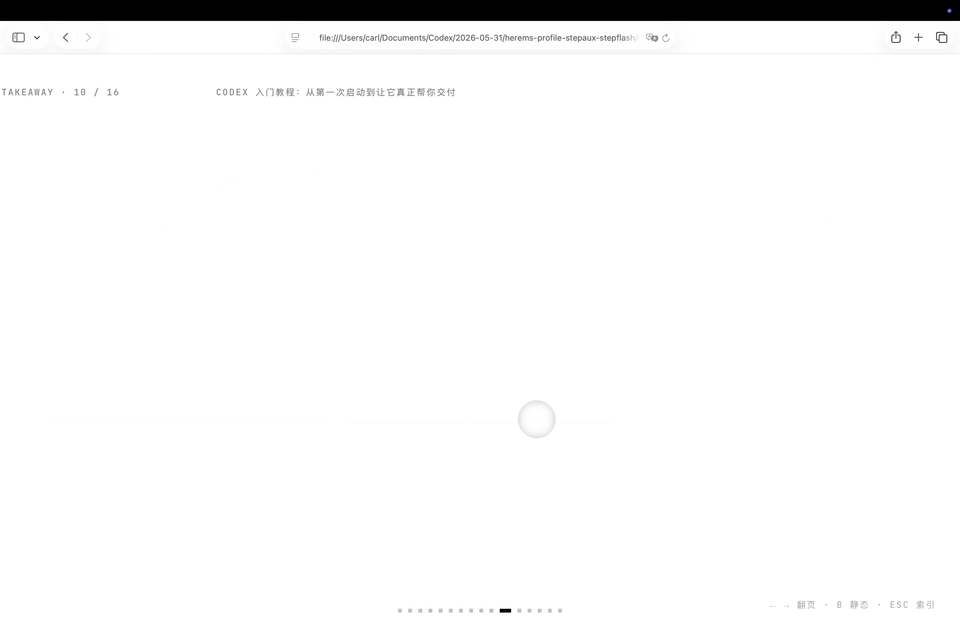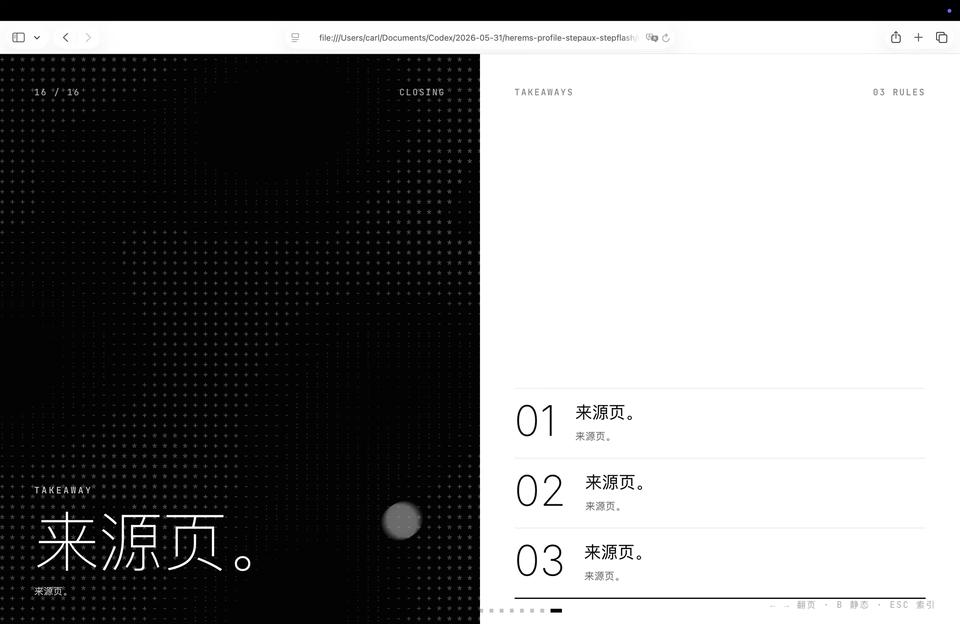
纯Step 3.7 Flash还是speed speed speed,提示语发出去没多久,整个页面就已经有了。它还把原来蓝色主题里那种星星点阵,跟黑色底色混在一起,做出了一套不太一样的主题。再看内容和资料引用,GPT-5.5加Step 3.7 Flash抓的源最多,然后是GPT-5.5,再就是Step 3.7 Flash。
只能说原生多模态是真的爽,提示语发出去没多久整个页面就都有了,如果它能把这些高频,重复,低风险但非常吃token的任务完整跑完,那它对Agent工作流的价值,可能比一句国产模型能上Claude Code还好用。因为Agent每次对话都不只调用一次模型。它可能一次任务里调用十几次、几十次,甚至更多。单次快一点,放到完整工作流里,体感差距会被放大。尤其是Hermes这种起标题,上下文压缩摘要,轻量分类这种后台任务。如果每个中间动作都用最贵的Pro模型跑,省心是省心了,一次对话十几分钟真的是有点等不下去。这里回收一下副标题,把Step 3.7 Flash接在闪电说里面,识别的速度非常快,进度条就没卡过。
如果把这些新出的模型,不止是Step 3.7 flash,作为一个辅助模型先跑起来,试错成本也低很多。我从Claude切到GPT的时候就非常不顺手,也是先手动把一些任务拆开,把放心交给GPT做都先丢过去。不像把API,账号登陆Codex只能二选一,我们完全可以给一个长期运转的Agent自由搭配不同的模型,比起之前要测几十万token,确认新模型能不能取代惯用模型的紧张感,我还是更喜欢现在的松弛感。
© 版权声明
文章版权归作者所有,未经允许请勿转载。