素材来源@猫先生和@雪佬说Gemini3做的SVG,别的模型画鹈鹕都没画明白的时候,它甚至可以画出能换档的电风扇。
先说Nano Banana Pro吧,没有什么前置条件,直接访问discord.gg/UuYfh5KR,你就可以看到这个戴墨镜的青蛙,然后在这个频道的左侧栏里找到lyra-chat,
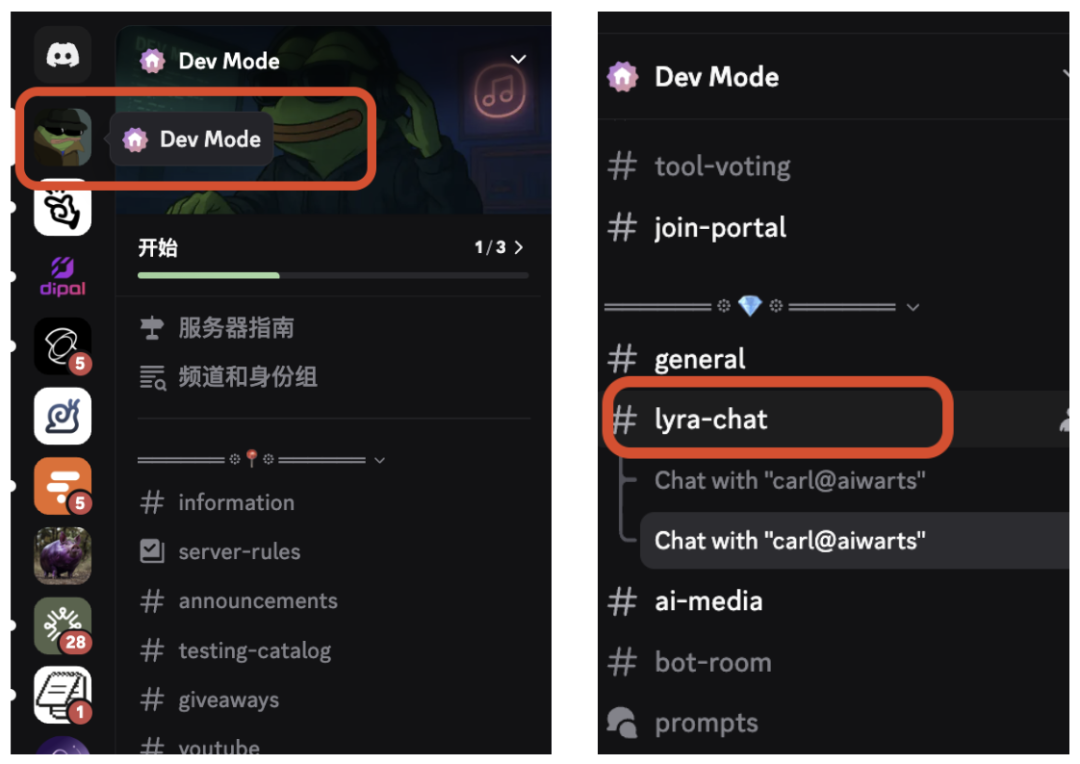
在lyra-chat的对话栏输入/new命令
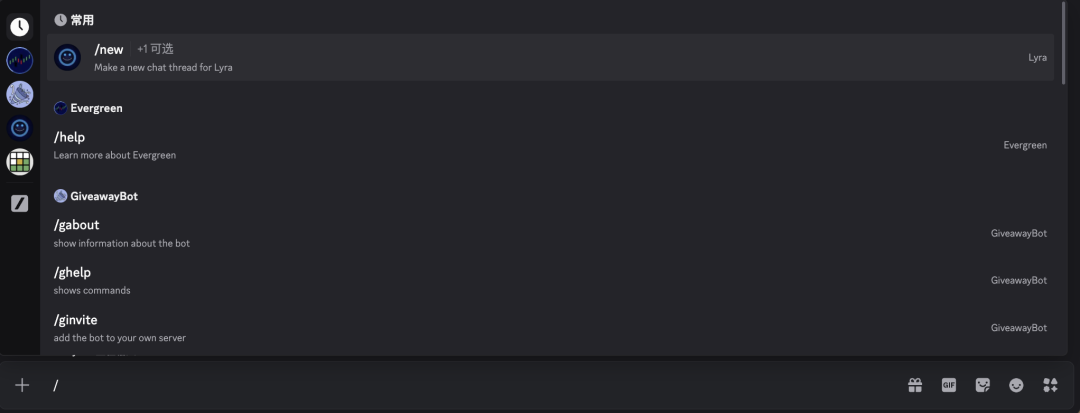
等一会,我尝试了三四次都是等1-2分钟就会回复了,还不算卡,这时候左侧栏就会多出一个chat,这个单独的窗口就是生图的入口。
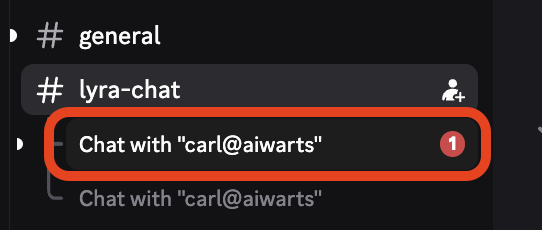
马上下一步,这里点Change Model改一下模型,选择nanobanana pro
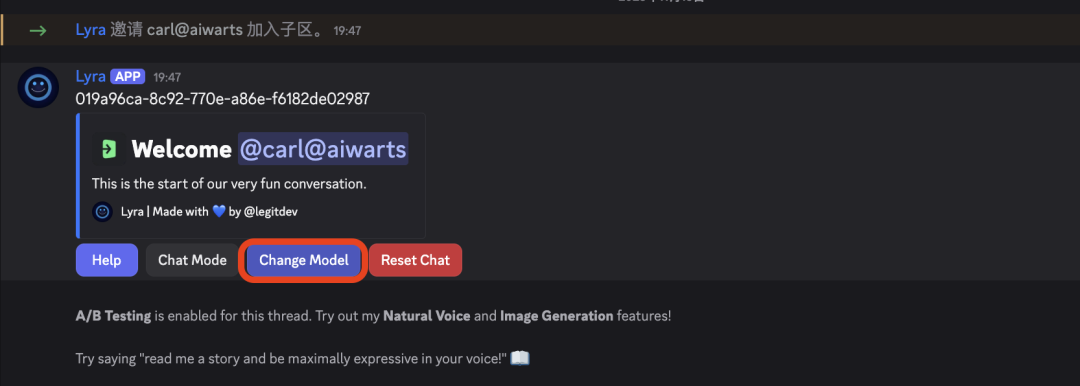
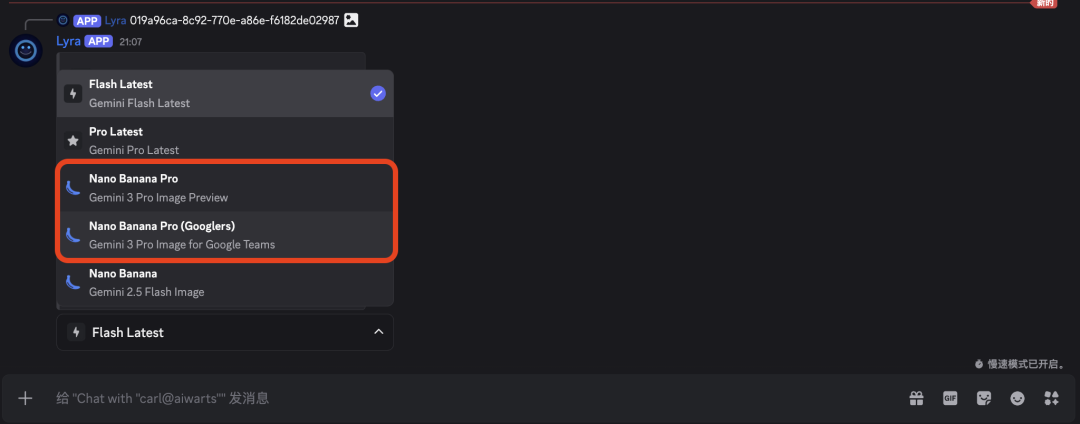
完事了,直接可以开始对话生图了
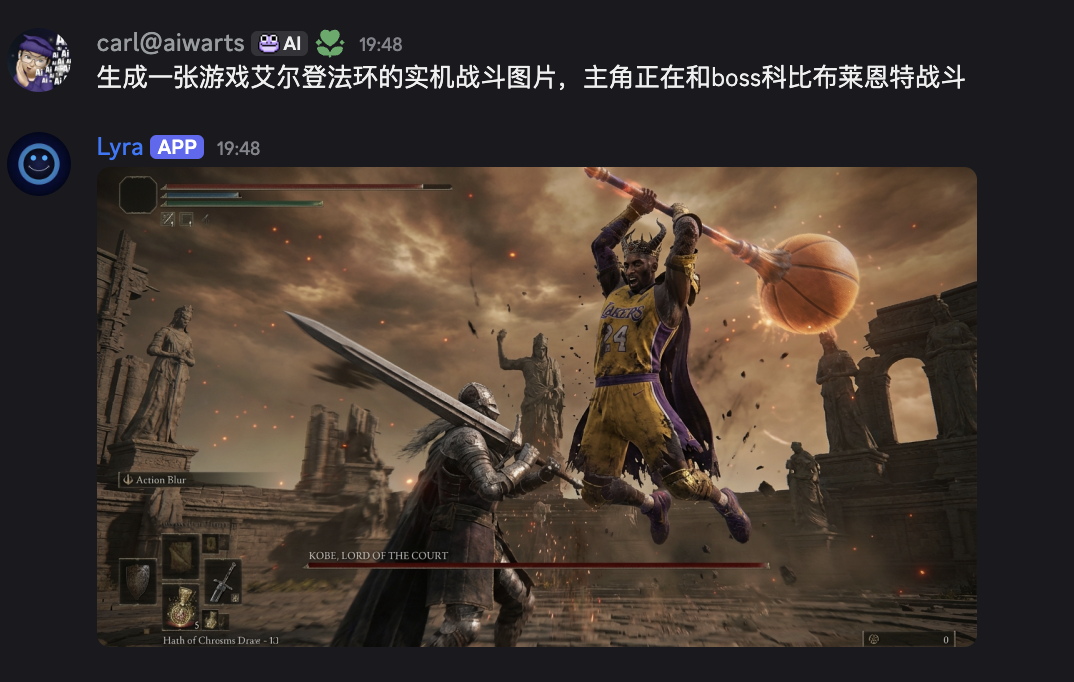
Gemini 3 Pro就更简单了,设置的条件只有一个是Pro账号,对话的时候打开Canvas,
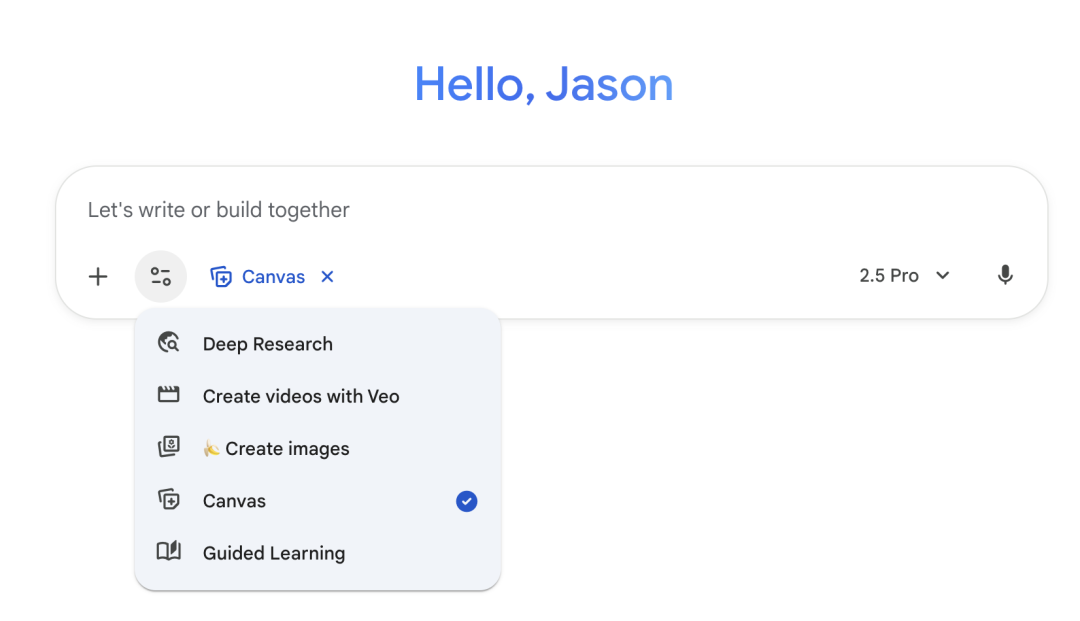
当你能用提示语跑出来能打俄罗斯方块,精灵宝可梦,塞尔达传说,超级马里奥大陆2的任天堂游戏机的时候,是Gemini3Pro没跑了。
当你用提示语跑出来能星星发光的纽约天际线的时候,大概率也是真的。
目前漏出来的model card里面的分数也是很离谱,先说离谱到我猜不出Google塞了多少数据的, MathArena Apex(高难度数学竞赛题),从 2.5 Pro 的0.5%暴涨至23.4%,ARC-AGI-2(视觉推理拼图),从4.9%提升至31.1%,ScreenSpot-Pro(屏幕理解),从11.4%飙升至72.7%,Vending-Bench 2(长流程代理任务,以净值衡量),从$573.64提升至$5,478.16
MathArena Apex(高难度数学竞赛题),从 2.5 Pro 的0.5%暴涨至23.4%,ARC-AGI-2(视觉推理拼图),从4.9%提升至31.1%,ScreenSpot-Pro(屏幕理解),从11.4%飙升至72.7%,Vending-Bench 2(长流程代理任务,以净值衡量),从$573.64提升至$5,478.16
稍微没那么夸张但是也算欺负人的,Humanity’s Last Exam(学术推理),从 21.6% 提升至37.5%,LiveCodeBench Pro(竞技编程),Elo评分从 1,775 提升至2,439,超过了 GPT-5.1 的 2,243。Terminal-Bench 2.0(终端命令行操作),从 32.6% 提升至54.2%。
多模态方面也提升了很大一截,MMMU-Pro(多模态理解),从 68.0% 提升至81.0%,OmniDocBench 1.5(OCR 文字识别|数值越低越好),从 0.145 优化至0.115,SimpleQA Verified(事实性问答),从 54.5% 提升至72.1%。
全方面领先,要不直接叫Gemini6吧,后缀比GPT5.1大就行。Gemini 3 Pro 在安全性、交互体验、合规性上也有提升。
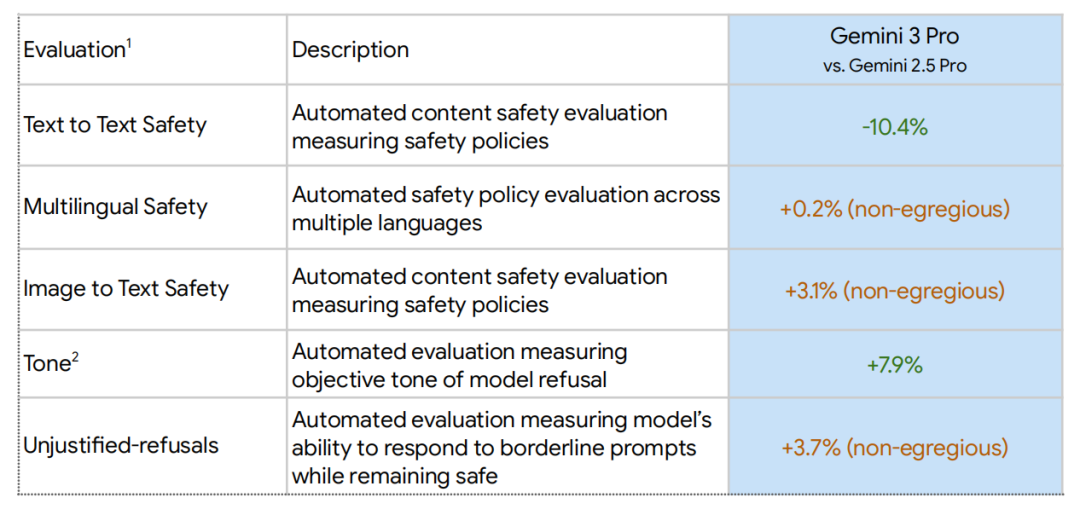
Text to Text Safety(纯文本安全性)增加了10.4%,Unjustified-refusals(过度拒绝/误拒)增加了3.7%,这是一个负面提升,会拒答,Multilingual & Image to Text Safety(多语言与图文安全性)整体上看是轻微波动,没太大影响。
@ 作者 / 键盘敲到飞起的卡尔
© 版权声明
文章版权归作者所有,未经允许请勿转载。