阿里千问发布“2025十大AI提示词”!排名第一的是它→→ 今日(12月22日),阿里千问官方发布了“2025十大AI提示词”榜单。"> 阿里千问发布“2025十大AI提示词”!排名第一的是它→→- · 科普中国网 AI 新资讯教育资讯# ai# 大语言模型 7个月前5,783219
研究显示:用 AI 的科研人员论文产出量暴增,但质量隐忧浮现 最新研究显示,AI技术显著提升了科研论文的产出数量,尤其在社会科学和人文科学领域增幅高达59.8%。但研究也警告,AI生成的论文语言越复杂,质量可能越低。 #AI科研# #论文质量# AI 新资讯行业资讯# ai# 人工智能# 大语言模型 7个月前8,436192
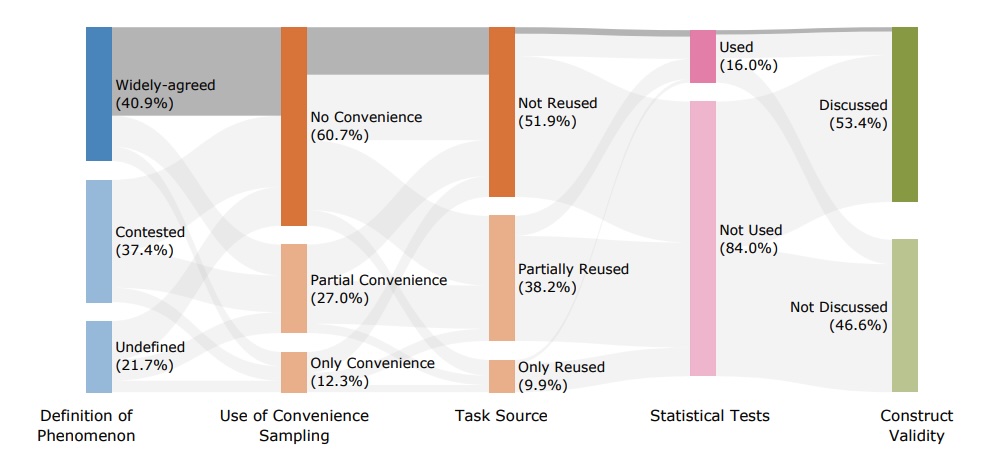
科学家发现多数大语言模型测试标准存在缺陷,无法客观给出评分 牛津大学等机构研究发现,多数大语言模型测试标准存在方法论缺陷,如术语模糊、数据采样不当等,导致AI进步难以客观衡量。研究建议明确定义目标、防止数据污染等改进措施。#AI测试标准##大语言模型# AI 新资讯行业资讯# 大语言模型 9个月前6,251149
微软:AI 聊天机器人越聊越“笨”,主流大模型在多轮对话中成功率降至 65% 微软与赛富时联合研究发现,主流大模型在多轮对话中成功率从90%骤降至65%,出现“迷失会话”缺陷。模型并非智力下降,而是变得不稳定,容易因过早生成、答案膨胀等机制累积错误。这对依赖AI构建复杂对话的开... AI 新资讯行业资讯# 大语言模型# 微软 5个月前5,16090